[ACM MM 2021]结合文字识别结果的鲁棒和精确文本视觉问答

一、研究背景
为了解决通用视觉问答(VQA)方法无法处理图像中文字信息的缺陷,文本视觉问答(TextVQA)任务被提出。TextVQA为了回答与图像中文字相关的问题,需要同时考虑视觉场景和文字等多个模态的信息及其关系,具有很大挑战。目前主流的方法通过引入一个外部的光学字符识别(OCR)模块作为前处理,再将其与VQA框架结合预测答案,这会使得TextVQA性能很大程度上受到OCR精度的影响,具体表现为以下两种误差累积传播现象:1)OCR错误使得对文字的直接语义编码错误,导致多模态信息的交互推理过程出现偏差,从而无法定位出准确的答案。2)即使是在推理和定位答案正确的情况下,OCR错误仍然会导致最终从OCR结果中“复制”的答案错误。另外,视觉物体模态与图像文字、问题模态交互时存在语义间隔,使得多模态信息无法有效融合。
二、方法简介

图 1 模型整体框架
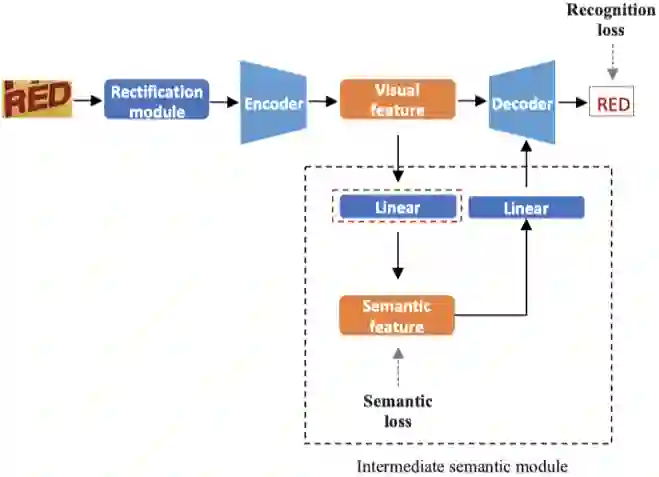
图 2 文字相关的视觉语义映射网络(TVS)结构图
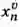 ,其中
,其中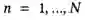 )与FastText(
)与FastText( )、PHOC(
)、PHOC( )、Faster R-CNN视觉(
)、Faster R-CNN视觉(
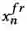 )和位置(
)和位置(
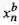 )特征结合,得到最终的视觉增强的文字表征:
)特征结合,得到最终的视觉增强的文字表征:
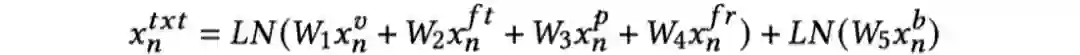
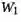 至
至
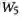 是可学习的参数矩阵,LN是层归一化。
是可学习的参数矩阵,LN是层归一化。

图 3 语义导向的物体识别网络(SEO-FRCN)结构图
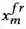 ,其中
,其中
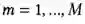 )和位置特征(
)和位置特征(
 ),再与预测的物体类别嵌入向量(
),再与预测的物体类别嵌入向量(
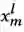 )进行结合,得到最终的物体表征:
)进行结合,得到最终的物体表征:
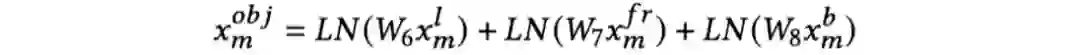
 至
至
 是可学习的参数矩阵,LN是层归一化。
是可学习的参数矩阵,LN是层归一化。
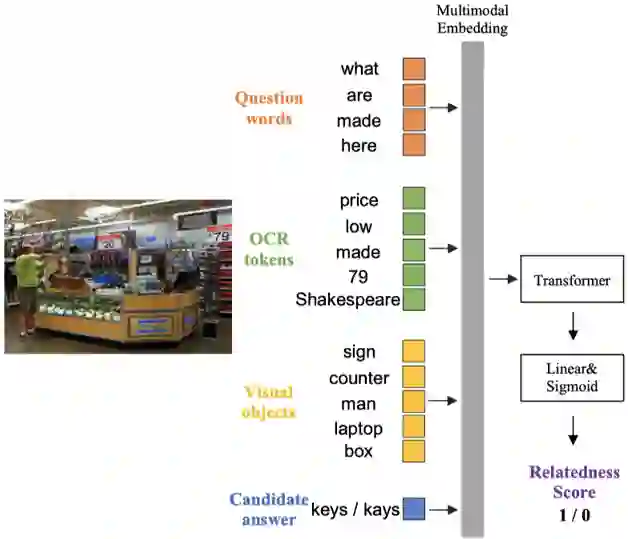
图 4 上下文感知的修正模块(CRM)结构图
在答案预测阶段,该方法提出一个上下文感知的答案修正模块(CRM)作为后处理来改进“复制”的答案。CRM结构如图4所示。具体来说,如果某个解码步的输出指向图像中的文字,则将它作为一个候选答案词,利用该候选词的上下文信息,即输入的问题、其他文字信息以及相关的物体信息对其进行修正。CRM由一个Transformer网络和一个二分类器构成,其中Transformer网络对上下文信息进行融合交互。将Transformer对应候选词的输出向量经过一个线性映射层和一个Sigmoid函数执行二分类,预测一个相关分数,通过最小化交叉熵损失训练。训练数据通过将多个外部OCR系统的候选识别结果和真实答案进行比对来构造。如果候选识别结果与真实答案词相同,则标注为正样本(相关分数为1);否则,如果候选识别结果与真实答案词的IOU大于设定阈值,则标注为负样本(相关分数为0)。前向推断时,则将多个外部OCR系统的识别结果送入CRM,选择相关分数最大的识别结果作为最终的答案词输出。
三、主要实验和可视化结果

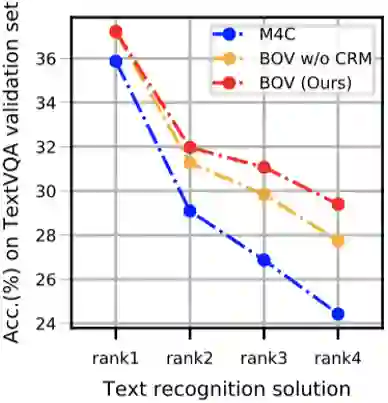
图 5 BOV与M4C在不同OCR结果时的比较(Rank1至Rank4的OCR准确率逐步下降)


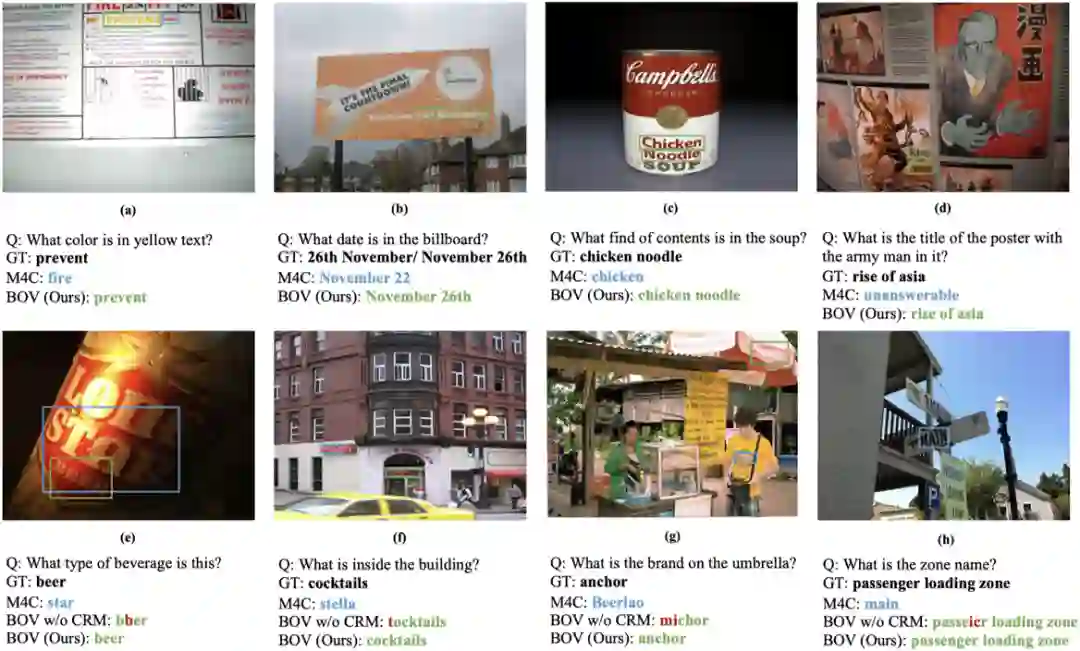
四、总结与讨论
BOV方法通过将OCR融入TextVQA的前向处理流程,构建了一个鲁棒且准确的TextVQA模型。区别于以前的方法将OCR模块视作固定的前处理,BOV联合OCR和VQA来消除OCR错误的负面影响。具体地,提出了一个视觉增强的文字表征和一个语义导向的视觉表征来减小多模态信息间的语义间隔,并增强特征表示。为了提升对OCR的鲁棒性,进一步提出了一个上下文感知的答案修正模块,在上下文信息的辅助下,从多个候选答案中选择正确的答案。实验证明该方法在不同OCR条件下都能取得较好的性能,优于已有的方法,而且能够在真实场景下发挥更大潜能。
相关资源
论文地址:
https://dl.acm.org/doi/10.1145/3474085.3475606
原文作者: Gangyan Zeng, Yuan Zhang, Yu Zhou, Xiaomeng Yang
撰稿:曾港艳、周宇
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TVQA” 就可以获取《[ACM MM 2021]结合文字识别结果的鲁棒和精确文本视觉问答》专知下载链接







