微信OCR(1)——公众号图文识别中的文本检测



OCR技术,通俗来讲就是从图像中检测并识别字符的一种方法,它是模式识别乃至人工智能领域最经典的研究方向之一。不同于传统OCR技术,针对自然场景图像中的文字识别技术则简称为 STR(Scene Text Recognition),其技术难度远高于传统OCR。 在STR领域,由于受到自然场景中图像退化的多样性以及多变的字体及风格等因素的影响,STR的识别率一直较低。
微信公众号里的图片素材属于STR领域中的自然场景图像,大多有着多样化的图像和文字,文字处于复杂的图像背景中,图片素材中的文字来源可能也各不相同。在微信公众号中,经统计,目前商家提供的素材信息80%是图片,而文字信息有限。此次公众号图文识别项目,是微信公众平台和我们 微信AI - 图像组 尝试合作和探索,针对微信公众号中的图像,自动并智能挖掘出图片里含有的文本信息。其目的是实现公众号信息的个性化推荐,不同用户看到的公众号推送内容是不同的。从而提高点击转化率。
其中该项目应用流程如下:
1. 公众号商家提供公众号文章候选、图文素材、商品信息、商品类目等;
2. 通过分析用户行为获取用户兴趣、意图等;
3. 1和2的信息交叉分析,自动排序公众号文章候选,生成包含若干篇文章的公众号推送消息,同时排序文章内的商品购买链接。

图1 :微信公众号的图片素材
1.文本检测和一般目标检测的不同——文本线是一个sequence(字符、字符的一部分、多字符组成的一个sequence),而不是一般目标检测中只有一个独立的目标。这既是优势,也是难点。
优势
体现在同一文本线上不同字符可以互相利用上下文,可以用sequence的方法比如RNN来表示。
难点
体现在要检测出一个完整的文本线,同一文本线上不同字符可能差异大,距离远,要作为一个整体检测出来难度比单个目标更大,所以预测文本的竖直位置(文本bounding box的上下边界)比水平位置(文本bounding box的左右边界)更容易。
2. Top-down(先检测文本区域,再找出文本线)的文本检测方法比传统的 bottom-up的检测方法(先检测字符,再串成文本线)更好。自底向上的方法的缺点在于,没有考虑上下文,不够鲁棒,系统需要太多子模块,太复杂且误差逐步积累,性能受限。
3. RNN 和 CNN 的无缝结合可以提高检测精度。CNN 用来提取深度特征,RNN(如LSTM)用来序列的特征识别,二者无缝结合,用在检测上性能更好。
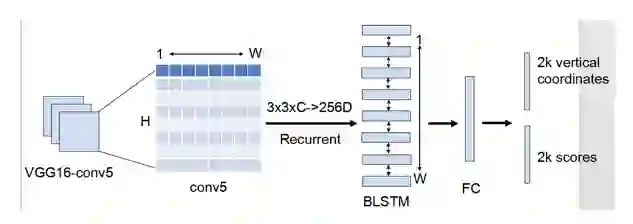
图2 :文本检测流程
我们所实现的文本检测技术基本流程如图2,总结起来,整个检测分为六步:
1. pretrain mode 可以采用 VGG16,ResNet50,ResNet50 的性能比 VGG16 要更好,检测速度也要更快在这里用 VGG16 作为 pretrain model 介绍技术细节。用 VGG16 的前 5 个 Conv stage ,这样得到网络的第5个卷积层的输出 conv5 的 feature map(C x H x W)。
2. 在Conv5的feature map的每个位置上取 3*3*C 的窗口的特征,这些特征将用于预测该位置 k 个 anchor(anchor的定义和Faster RCNN类似)对应的类别信息和位置信息。k个anchor尺度和长宽比设置:宽度都是 16,k = 10,高度从11~273(每次除于0.7)。回归的高度和bounding box的中心的y坐标如下,带*的表示是 ground Truth,带 a 的表示是 anchor。
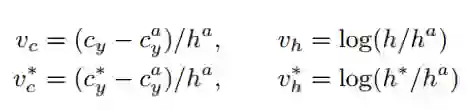
在这里,score的阈值设置是0.7(+NMS)。
3. 接着我们把CNN和RNN进行无缝衔接。将每一行的所有窗口对应的 3*3*C的特征(W*3*3*C)输入到RNN(BLSTM)中,得到W*256的输出。在这里,RNN的类型是BLSTM(双向LSTM),每个 LSTM有128个隐含层,所以RNN的输出是256维特征。RNN的输入是,每个滑动窗口的3*3*C的特征(可以拉成一列),同一行的窗口的特征形成一个序列。
将 RNN(如我们使用的LSTM)的序列化特性引入到文本检测,增加了文本检测候选区域的上下文信息,有效地提升了文本检测任务的性能。图4显示了一些文本检测系统引入RNN之后,检测前后的性能对比结果。
4. 将RNN的W*256输入到512维的fc层。
5. 然后将fc层特征输入到一个分类层和一个回归层中。第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符)。第一个 2k vertical coordinate 是用来回归 k 个 anchor 的位置信息。
2k vertical coordinate 表示的是bounding box 的高度和中心的y轴坐标(可以决定上下边界),这边注意,只用了3个参数表示回归的 bounding box,因为这里默认了每个 anchor 的 width是 16 ,且不再变化(VGG16的conv5的stride是16)。回归出来的 box 如图 3 中那些红色的细长矩形,它们的宽度是一定的,我们暂且把这些细长矩形叫做 fine scale text proposal 。

图3 :小尺度文本候选区域
6. 用简单的文本线构造算法,把分类得到的文字的fine scale proposal(如图3中的细长的矩形)合并成文本线。文本线构造算法(多个细长的proposal合并成一条文本线)。主要思想:每两个相近的proposal组成一个pair,合并不同的pair直到无法再合并为止(没有公共元素)。判断两个proposal,Bi和Bj组成pair的条件:
e'e'e'e'e'e
(1)Bj->Bi,且Bi->Bj。(Bj->Bi表示Bj是Bi的最好邻居)。
(2)Bj->Bi条件1:Bj是Bi的邻居中距离Bi最近的,且该距离小于50个像素。
(3)Bj->Bi条件2:Bj和Bi的vertical overlap大于0.7。在这里,score的阈值同样设置为0.7(+NMS)。

图4 :引入RNN前后,文本检测性能对比结果(图中上面部分是没有引入RNN的检测结果,下面部分是引入RNN之后的检测结果)
目前我们微信OCR的文本检测系统的技术性能大致如下,在 ICDAR2015 task2 的 text localization 任务中,我们的 Hmean 值是 82%,处于所有参赛队伍中等偏上水平。检测时,当输入图像最短边为 600,最长边不超过 1000,且在单核 cpu 的情况下,不采用外部加速优化库,基于 VGG16 模型的检测时间大约为 2-3s/img,基于 ResNet50 模型的检测时间大约是 1-2s/img ,检测速度和精度还在不断优化中。图5展示了一些我们微信 OCR 的文本检测技术在微信公众号图片中的性能结果。


图5 :微信OCR文本检测技术在微信公众号图片的检测结果
微信公众号的图文识别项目是微信OCR在自然场景的文本检测的一次尝试,在实践过程中把RNN引入检测问题(以前一般做识别)。在文本检测中,先用CNN得到深度特征,然后用固定宽度的anchor来检测text proposal(文本线的一部分),并把同一行anchor对应的特征串成序列,输入到RNN中,最后用全连接层来分类或回归,并将正确的text proposal进行合并成文本线。同时我们也在不断地优化文本检测的精度和速度,相信不久之后,微信OCR在自然场景的图像中的文本检测一定可以处于领先地位,欢迎各位技术同行与我们交流讨论。
感谢组内同事 winnyma 和 careyjiang 的指正和技术支持。

 微信ID:
微信ID:
 长按左侧二维码关注
长按左侧二维码关注
登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文