![]()
过去几年,强化学习领域取得了令人印象深刻的进展,不仅可以下围棋,还可以玩 StarCraft、Dota 2等各种游戏,并且还获得了超越人类玩家的傲人成绩。
但强化学习本质上是由异构任务组成的,即便是目前最先进的分布式算法也无法有效地使用已有的计算资源来完成任务。大量的数据,和对资源的低效利用,使得实验的成本高得令人望而却步。由此一来,现在强化学习技术越来越多地被用来训练系统玩简单的游戏,这无疑与强化学习领域的上升发展是“背道而驰”的。
一种解决之道,便是采用分布式方法,将计算任务分散到不同的机器上。目前最为优秀的分布式强化学习是 DeepMind 于2018年推出的 IMPALA 架构,然而 IMPALA 存在着一系列的缺点,例如资源利用率低、无法大规模扩展等。
论文地址:
https://arxiv.org/abs/1910.06591
针对这些问题,谷歌在最新工作《SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference》(
为ICLR 2020 Oral 论文
)中,提出了一个能够扩展到数千台机器的强化学习架构——SEED RL(Scalable and Efficient Deep-RL,即可扩展且高效的深度强化学习),同时该架构还能够以每秒数百万帧的速度进行训练,计算效率显著提高。
谷歌研究者在 Google Research Football、DeepMind Lab等常用的强化学习基准上测试了SEED RL 的性能,结果非常令人惊喜。
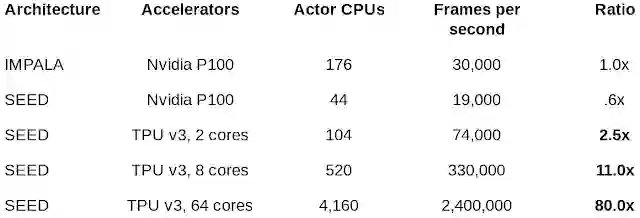
其中,在DeepMind Lab 基准上比较了SEED RL 和 IMPALA 的性能。
结果显示,SEED RL 使用64个 Cloud TPU 的计算速度达到了每秒240万帧,比当前最好的分布式强化学习架构 IMPALA 提高了 80 倍。在相同速度下,IMPALA 所需要的CPU 数量是SEED RL的 3 到 4 倍。
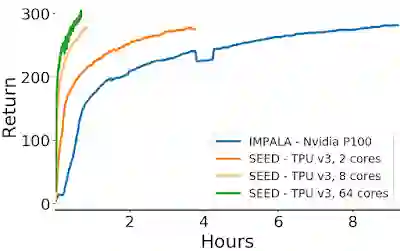
在训练时长上, SEED RL 相比IMPALA 也有非常显著的减少,如下图所示:
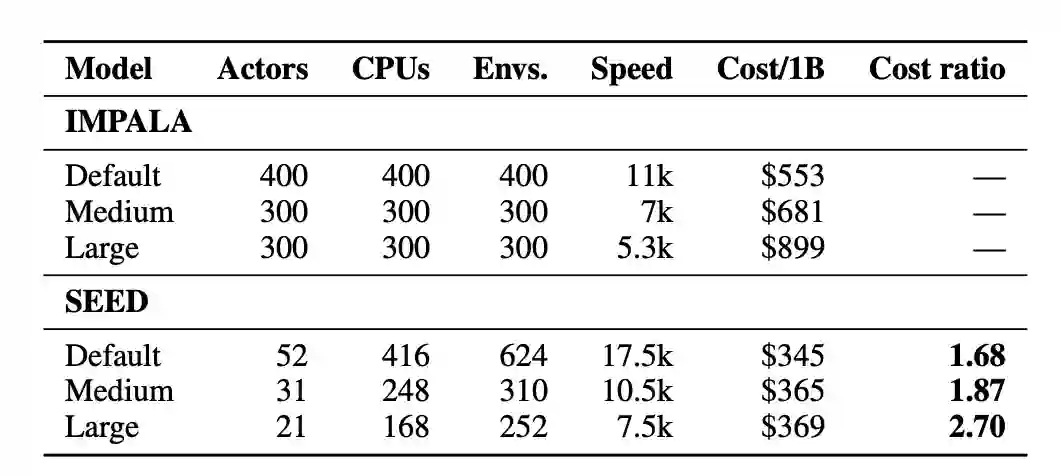
在 Google Research Football 基准上实验了不同架构在“复杂”任务上的得分情况:
结果显示,随着输入分辨率越高以及模型越大, SEED RL的得分就越高,而随着训练得越多,模型的性能也得到了显著提高。
当然,更重要的还是——省钱!如上图所示,在 Google Research Football 上训练 10亿帧,SEED 相比 IMPALA 要节省数百美元,而且模型越大,节省越多。
SEED RL 本质上是在 IMPALA 基础上的一个改进。因此我们先简单来看下 IMPALA是如何做分布式强化学习的。
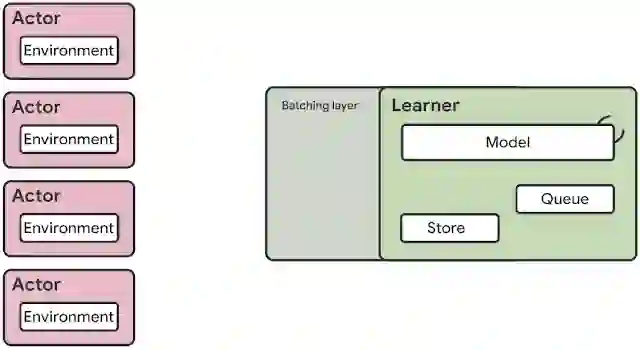
IMPALA 的
体系架构分为Actor 和Learner。其中actor一般运行在CPU上,它在环境中采取步骤,然后在模型上运行推断,进行迭代,然后预测下一个动作。Actor 会更新推理模型的参数,在收集到足够多的观察数据后,actor会将观察和动作的结果发送给learner,learner根据这些反馈结果进行优化。
![]()
IMPALA 架构
在这个体系结构中,learner运行在GPU上,它会综合来自数百台机器上的分布式推理输入,进行模型训练。随后将学习的模型参数传递给actor。
1、使用CPU进行神经网络推理。Actor通常是基于CPU的(有时会基于GPU,但仅限于要求比较苛刻的环境)。众所周知,CPU在神经网络的计算效率上是很低的;当模型的计算需求增加时,用于推理的时间会超过环境step计算。针对这个问题,解决方案是,增加actor的数量,但这除了会增加成本,也会影响收敛。
2、资源利用效率太低。Actor要在两个任务(环境步骤和推理步骤)之间进行交替,而事实上,这两个任务的计算需求是不匹配的,这就导致Actor的对资源的低利用率。举例来说,有些环境本身是单线程的,而神经网络则往往需要并行;
3、带宽需求。模型参数、递归状态和观测不断在actor 和 learner之间进行交换。观测数据的大小往往只占模型参数大小的百分之几。每秒发送100,000个观测数据(96 x 72 x 3个字节),轨道长度为20,模型大小为30MB,总带宽需求为148 GB/s。传输观测数据只需要2GB /s。
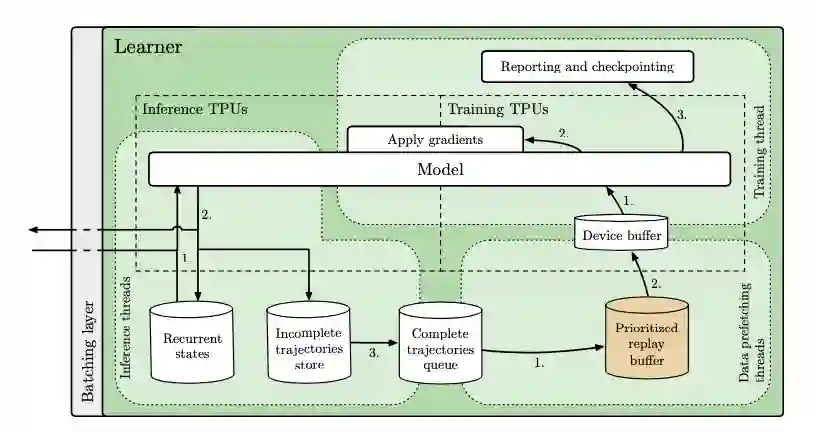
SEED RL框架同样是由 Learner和 Actor 两部分组成。
但不同的是,SEED RL 依托于一种通过中心化模型推理,并引入快速通信层来大规模利用加速器(GPU 或 TPU)的新型架构。
![]()
SEED RL架构一览。与 IMPALA架构不同,Actor 仅在环境中采取动作,而推理集中由Learner 使用来自多个Actor 的批量数据在加速器上执行。
其中,神经网络推理集中由 Learner在专用的硬件(GPU或 TPU)上进行,通过确保模型参数和状态不出本地,从而来加速推理,并避免数据传输的瓶颈。
当智能体在每一个环境步骤中将观察结果传送至 Learner时,基于具有异步服务器流RPC 的gRPC框架的高效网络库会将延迟维持在较低的频率。这样能够在一台机器上实现每秒一百万次的查询。Learner能够扩展到数千个核上(例如在Cloud TPU上可以扩展到2048个),与此同时Actor 的数量也可以扩展到数千台机器上,从而能够充分利用Learner,训练速度达到每秒数百万帧。
为了确保该框架顺利完成任务,SEED RL集成了两项最佳算法:
一个是 V-trace算法
,这是一种基于策略梯度的方法,最早是在 IMPALA中首次提出。一般而言,基于策略梯度的方法预测出一个动作分布并从中采样动作。然而,由于Actor和 Learner在SEED RL智能体中是异步执行的,Actor的策略稍后于Learner的策略,也就是说它们会变成异策略(off-policy)。而一般基于策略梯度的方法是同策略( on-policy),这就意味着Actor和 Learner都采取同样的策略,而在异策略中会遇到一致性和数值问题。V-trace算法是一种异策略方法,因而能在异步 SEED RL 架构中表现得很好。
另一个是 R2D2算法
,这是一种 Q-learning 方法,使用递归分布式重放基于该动作的预测未来值来选择动作。这种方法使得Q-learning算法能够进行大规模运行,同时还能使用递归神经网络,该网络能够根据情景中所有过去帧的信息来预测未来值。
实验的结果,我们在文章前面已经展示。这里总结一下谷歌这项工作的意义:
1、 相比 IMPALA,SEED RL 框架将推理部分转移到 Learner 中。这样调整后,Actor中就不再有任何关于神经网络相关的计算了。这样做的好处是,模型的大小不会影响Actor,于是便可扩大Actor的数量,做到可扩展。
2、在SEED RL的架构下,Learner(以GPU或TPU为主)可以专注于批量推理,而Actor(以CPU为主)可以更加适应多环境。整体来说,这种结构会降低实验成本。
3、涉及模型的所有内容都留在Learner本地,只有观测结果和动作会在Learner 和Actor之间进行传输,这可以将带宽需求降低多达99%。
4、使用了具有最小延迟和最小开销的 streaming gRPC,并将批处理集成到服务器模块当中。
据了解,目前SEED RL 框架已经开源,打包后可以非常容易地在Google Cloud 上运行。开源地址是:https://github.com/google-research/seed_rl
05. Spotlight | 华盛顿大学:图像分类中对可实现攻击的防御(视频解读)
4、Poster
![]()
![]() 点击“
阅读原文” 查看 ICLR 系列论文解读
点击“
阅读原文” 查看 ICLR 系列论文解读





 点击“
阅读原文” 查看 ICLR 系列论文解读
点击“
阅读原文” 查看 ICLR 系列论文解读

