比TD、MC、MCTS指数级快,性能超越A3C、DDQN等模型,这篇RL算法论文在Reddit上火了

作者:Jose A. Arjona-Medina、Michael Gillhofer、
Michael Widrich、Thomas Unterthiner、Sepp Hochreiter
来源:arxiv、机器之心
本文在 Reddit 上也引起了广泛而热烈的讨论,网友表示,论文中长达 50 页的附录令人感到惊艳,这样他们就不用绞尽脑汁去猜测作者们到底是怎么完成实验的。此外,虽然主要的实验结果仅针对两个简单的游戏,但其方法很有潜力,相当具备进一步探索的价值。
论文:RUDDER: Return Decomposition for Delayed Rewards

论文链接:https://arxiv.org/abs/1806.07857
摘要:我们提出了一种针对延迟奖励的有限马尔可夫决策过程(MDP)的新型强化学习方法。本研究证明了时间差分(TD)估计偏差的纠正速度仅在延迟步上出现指数级的减慢。此外,本研究还证明蒙特卡洛估计方差可以增加其他估计值的方差,使之在延迟步上出现指数级的增长。我们介绍了一种返回值分解方法(return decomposition method)RUDDER,该方法使用和原始 MDP 一样的最佳策略创建了一个新的 MDP,但是其再分配奖励的延迟已经大大降低。如果返回值分解方法是最佳策略,那么新的 MDP 不会有延迟奖励,TD 估计也不会出现偏差。在这种情况下,奖励追踪 Q 值,这样未来的期望奖励值就保持为零。我们通过实验确认了关于 TD 估计偏差和 MC 估计方差的理论结果。在不同长度的奖励延迟的任务中,我们展示了 RUDDER 的速度是 TD、MC 以及 MC 树搜索(MCTS)的指数级。在延迟奖励 Atari 游戏 Venture 中,RUDDER 仅学习了一小段时间,其性能就优于 rainbow、A3C、DDQN、Distributional DQN、Dueling DDQN、Noisy DQN 和 Prioritized DDQN。RUDDER 在更少的学习时间内显著提高了在延迟奖励 Atari 游戏 Bowling 上的当前最优性能。
引言
在强化学习中,为执行动作的接收奖励分配信度值是中心任务之一 [107]。人们认识到长期信度值分配是强化学习中最大的挑战之一 [91]。目前的强化学习方法在面对长期延迟的奖励时速度会显著降低 [84,86]。为了学习延迟奖励,有三个阶段需要考虑:(1)发现延迟奖励;(2)追踪延迟奖励相关信息;(3)学习接收延迟奖励并保存以备后用。近期成功的强化学习方法为以上三个阶段中的一个或多个提供了解决方案。最著名的方法是 Deep Q-Network(DQN)[71, 72],它结合了 Q-learning 和卷积神经网络用于视觉强化学习 [58]。
DQN 的成功归因于经验重放(experience replay)[64],其保存了观察到的状态奖励转换过程,然后从中采样。优先经验重放 [93,50] 促进了对重放记忆的采样。Ape-X DQN 的训练中,不同的策略并行执行探索,并共享优先经验重放记忆 [50]。DQN 被扩展为 double DQN(DDQN)[113,114],其降低了过高估计的偏差,从而有助于探索。Noisy DQN [21] 通过策略网络中的一个随机层进行探索(详见 [40, 94])。Distributional Q-learning [8] 可以从噪声中获益,因为有高方差的平均值更可能被选择。对抗(dueling)网络架构 [117,118] 可以分别估计状态值和动作优势,从而可以帮助在未知状态中的探索。策略梯度方法 [124] 也通过并行策略进行探索。A2C 通过 IMPALA 的并行 actor 和对 actor、学习器之间的策略滞后的修正得到改进。结合异步梯度下降的 A3C [70] 和 Ape-X DPG [50] 也依赖并行策略。近端策略优化(PPO)通过代理目标和由截断(clipping)或 Kullback-Leibler 惩罚 [96] 实现的置信域优化扩展了 A3C。
近期出现的方法希望能解决延迟奖励带来的学习问题。如果和奖励相关的状态和很多步之前遇到的状态很相似,则价值函数的函数逼近或 critic [72,70] 可以填补时间间隔。例如,假设一个函数学习预测一个 episode 结束时的大奖励值(如果其状态具备特定的特征)。该函数可以将该相关性泛化到 episode 的起点,并为处理相同特征的状态预测已经很高的奖励值。多步时间差分(TD)学习 [105,107] 可以改善 DQN 和策略梯度 [39, 70]。AlphaGo 和 AlphaZero 使用蒙特卡洛树搜索(MCTS)可以达到比人类职业选手更好的围棋和国际象棋水平。MCTS 从一个时间点开始模拟博弈,直到博弈结束或到达一个评估点,因此 MCTS 能够捕捉到长期延迟奖励。近期,使用进化策略的世界模型很成功 [36]。这些前向方法在具备状态转换高分支因子的概率环境中并不可行。后向方法追溯已知的目标状态 [18] 或高奖励状态 [30]。然而,我们必须一步一步地学习后向模型。
我们提出后向的学习过程,且这是基于前向模型构建的。前向模型预测返回值,而后向模型分析确认导致返回值的状态和动作。我们使用长短期记忆网络(LSTM)来预测一个 episode 的返回值。LSTM 已经在强化学习中的优势学习(advantage learning)[4] 和学习策略 [37,70,38] 中得到了应用。然而,通过「模型中的反向传播」进行的敏感度分析 [75,87,88,5] 有严重的缺陷:局部极小值、不稳定性、世界模型中的梯度爆炸或消失问题、恰当的探索、动作仅通过敏感度进行分析而不是基于它们的贡献(相关性)[40,94]。
由于敏感度分析极大地阻碍了学习,我们对反向分析使用了贡献分析,例如贡献传播 [60]、贡献方法 [81]、excitation 反向传播 [127]、层级相关度传播(LRP)[3]、泰勒分解 [3,73] 或集成梯度(IG)[103]。使用贡献分析,预测的返回值可以沿着状态-动作序列分解为贡献。通过用实际返回值替代预测,我们得到了一个再分配奖励,进而获得一个新的 MDP,其最优策略和原始 MDP 相同。再分配奖励和奖励塑造(reward shaping)[76,122] 是很不同的,其将奖励变为状态的函数而不是动作的函数。奖励塑造和「回溯建议」(look-back advice)[123] 都保持了原始奖励,即仍然可能存在较长的延迟,从而导致学习过程指数级变慢。我们提出了 RUDDER,其通过返回值分解来执行奖励重分配,从而克服 TD 和 MC 因为延迟奖励而遇到的问题。RUDDER 可以极大地减少 MC 的方差,并极大程度地避免 TD 的指数级缓慢的偏差修正(对于最优的返回值分解,TD 甚至是无偏差的)。
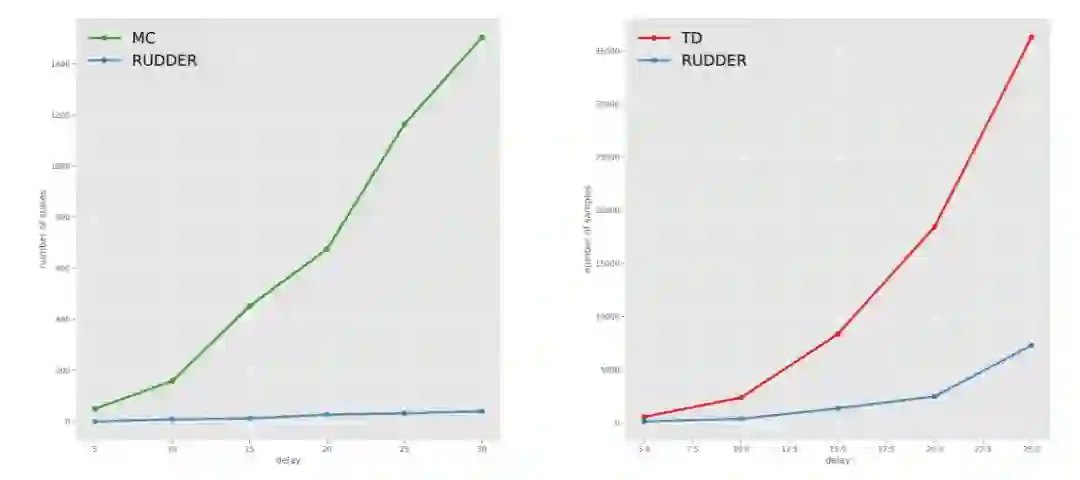
图 1:在 Grid World 上对不同 Q 值 estimator 的偏差和方差的实验评估结果。左:高方差影响的状态数量随着延迟步数的增加呈现指数级的增长。右:不同延迟上将偏差减少 80% 的样本数量。
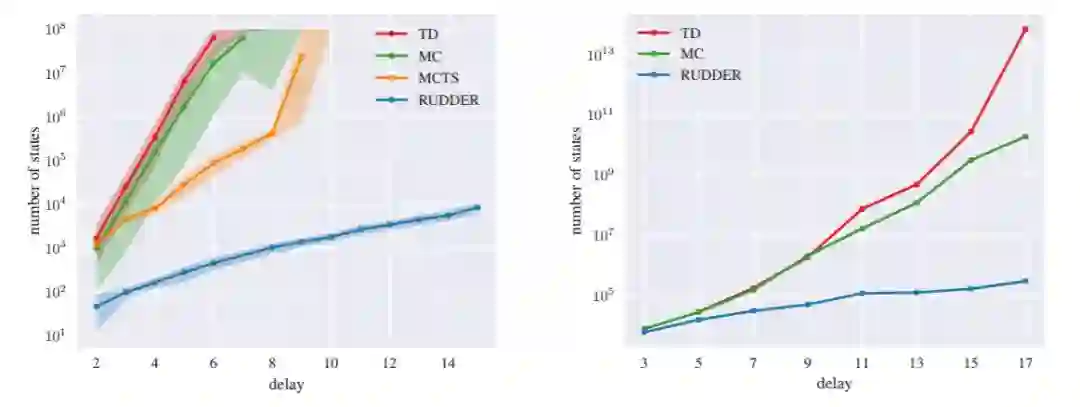
图 2:不同方法在不同延迟下学习达到 90% 返回奖励的最佳策略的观察状态数(对数坐标)。我们对比了由 Q 学习实现的时序差分(TD)、蒙特卡洛(MC)、蒙特卡洛树搜索(MCTS)和 RUDDER。左:Grid World 环境。右:Charge-Discharge 环境。RUDDER 和其他方法所需状态的差距随着延迟步数的增加呈现指数级增长。
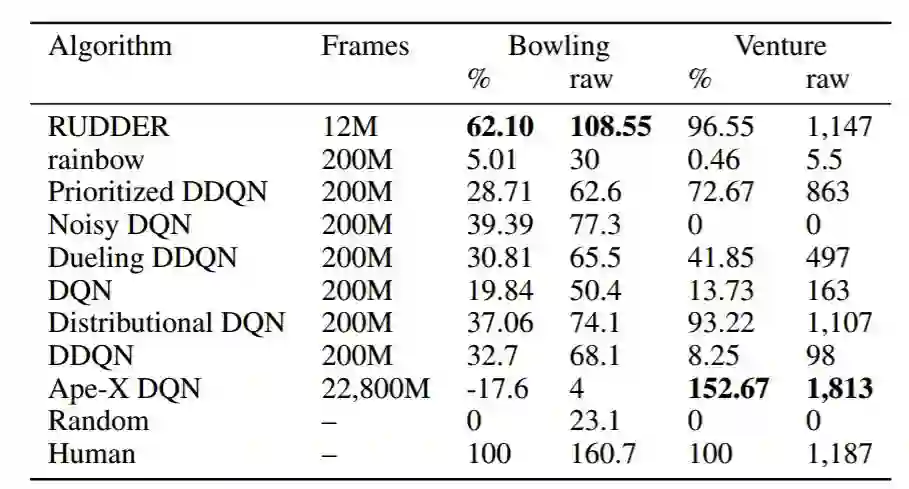
表 1:RUDDER 和其他方法在学习 Atari 游戏 Bowling 和 Venture 时的结果。在无操作指令开始条件下,各个方法在超过 200 个测试游戏中的归一化人类得分和原始得分:A3C 得分未报道,因为其在无操作指令开始条件下无法获得。其他方法的得分来自于之前的研究 [8, 39]。我们选择了仅基于 12M 帧训练损失的 RUDDER 模型。
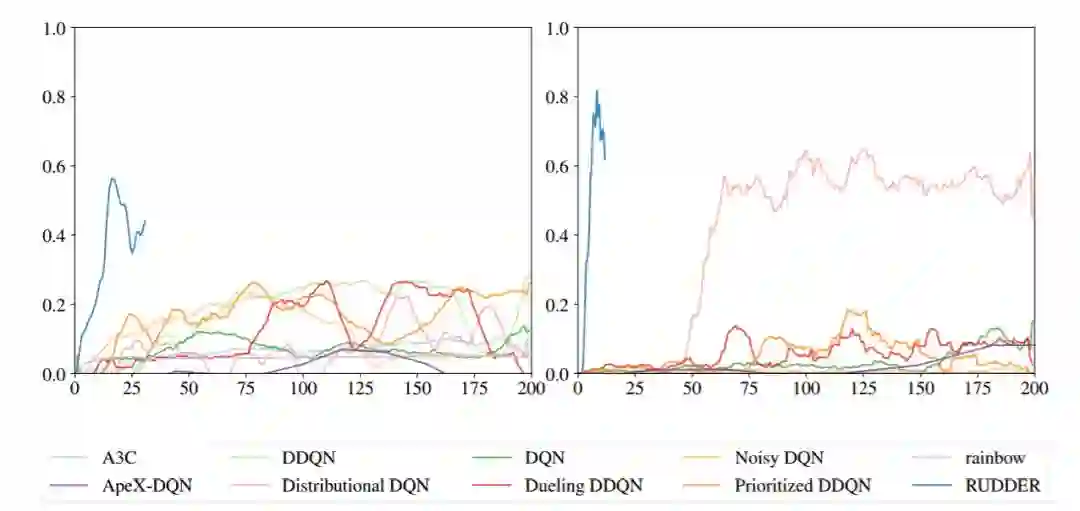
图 3:RUDDER 学习 Atari 游戏 Bowling 和 Venture 的延迟奖励的速度比其他方法快。左图是 Bowling 游戏训练过程中各个方法的归一化人类得分,右图是 Venture 游戏训练过程中各个方法的归一化人类得分,其中学习曲线来自于之前的研究 [39, 50]。RUDDER 在 Bowling 游戏上达到了新的当前最优性能。
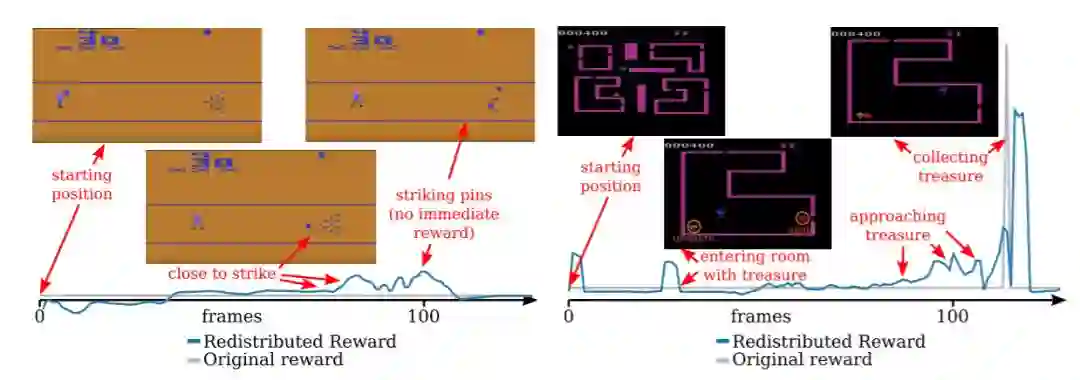
图 4:RUDDER 在具备较长延迟奖励的两个 Atari 游戏中的返回值分解示意图。左:在 Bowling 游戏中,仅在一个 turn(包含多次滚动)后给予奖励。RUDDER 识别引导球沿着正确方向击中瓶子的动作。一旦球击中瓶子,RUDDER 随即检测与击中瓶子相关的延迟奖励。图中只展示了 100 帧,但是整个 turn 的长度超过 200 帧。在原始游戏中,奖励是在 turn 结束时才给予。右:在 Venture 游戏中,只在收集到宝藏后才给予奖励。RUDDER 通过奖励再分配引导智能体(红色)前往宝藏处(金色)。奖励在进入有宝藏的房间时进行再分配。此外,随着智能体离宝藏越来越近,再分配奖励逐渐增加。为简洁起见,图中绿色曲线展示了在使用 lambda 之前的再分配奖励。环境仅在收集宝藏结束时才给予奖励(蓝色)。
源代码:https://github.com/ml-jku/baselines-rudder
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习


