【泡泡点云时空】面向大规模点云的全卷积网络(ECCV2018-8)
泡泡点云时空,带你精读点云领域顶级会议文章
标题:Fully-Convolutional Point Networks for Large-Scale Point Clouds
作者:Dario Rethage, Johanna Wald, Jürgen Sturm, Nassir Navab, and Federico Tombari
来源:ECCV 2018
播音员:Sara
编译:廖康
审核:郑森华
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

简介

本文提出了一个能有效处理大规模3D数据的全卷积网络——FCPN,该网络将无规则的3D输入数据比如点云,转换为内部有序的数据结构,然后再使用3D卷积进行处理。与输入输出结构一致的传统方法相比,FCPN具有在高效存储输入数据中操作的优点,同时利用自然结构的卷积运算以避免对冗余空间信息的计算与存取。该网络消除了对原始数据预处理和后处理的需求,加之全卷积结构的特点,使其能够端到端处理大规模空间的点云数据。FCPN另一个优点是能够直接从输入点云生成有序的输出或者预测图,因此使其能够作为很多3D任务的通用点云描述器。通过在语义体素分割、语义部分分割和3D场景描述相关评估实验,本文展示了网络有效学习低级特征以及复杂组合关系的能力。
网络架构
FCPN网络架构如下图所示,是一个标准的encoder-skip connection-decoder结构,主要包括了抽象层(Abstraction Layers)、特征学习层(Feature Learners)、加权平均池化层(Weighted Average Pooling)以及合并阶段(Merging)。在S1阶段,使用PointNet作为低层特征描述子并应用均匀采样方法,将无序的输入数据转化为内部有序的数据,随后(包括S2和S3阶段)用3D卷积进行不同尺度的成分关系学习。
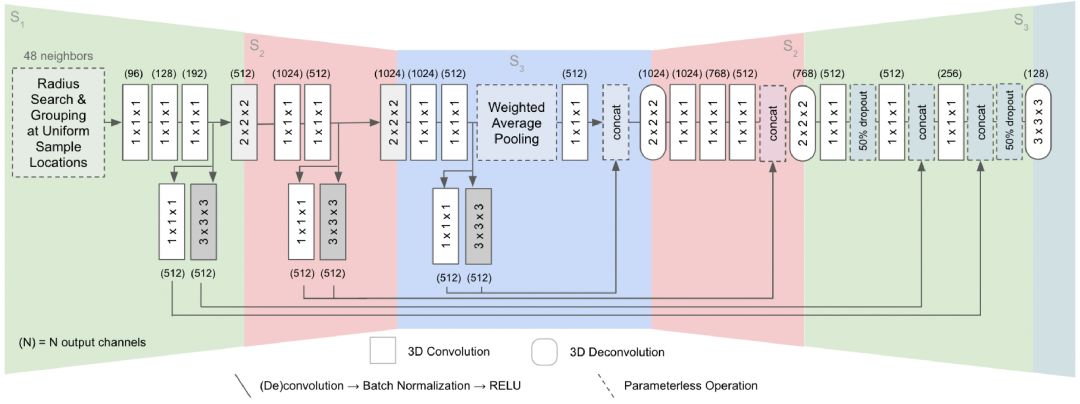
图1 FCPN网络架构
实验结果

图2 在ScanNets测试序列中的语义体素分割结果。(a)输入点云,(b)FCPN分割结果,(c)Ground Truth

图3 部分分割结果

图4 场景描述结果。第一列为输入点云数据,第二列为点云对应场景的RGB图像,下面的句子为FCPN对场景进行描述的结果。
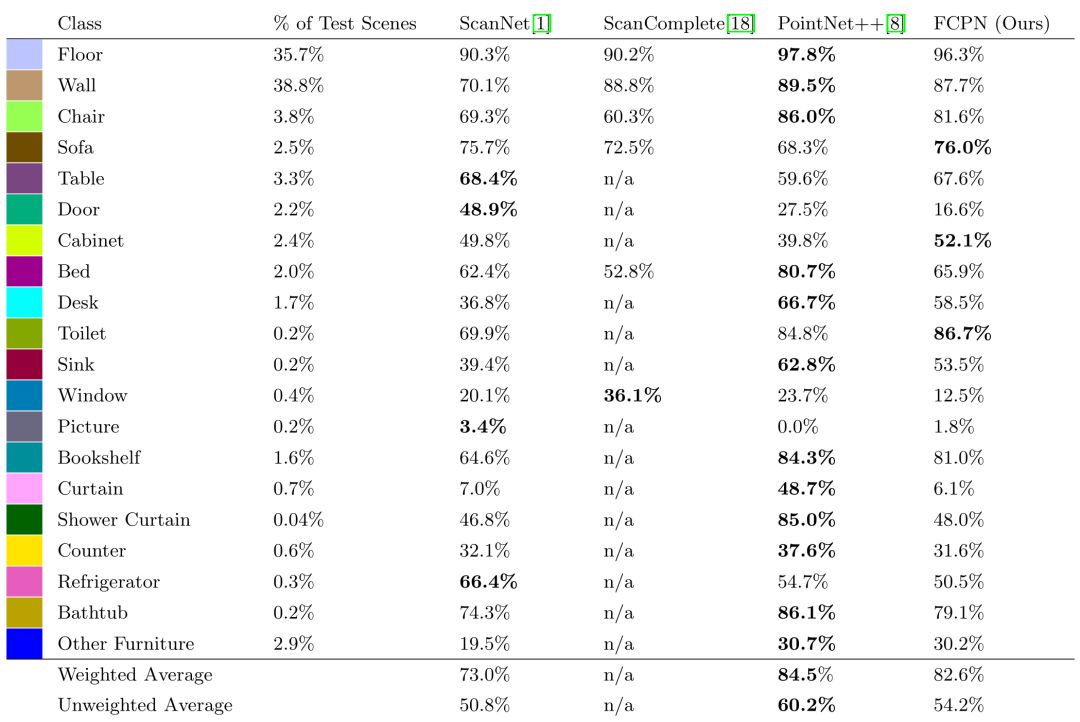
图5 FCPN在ScanNet测试集上与其他方法比较的语义体素分割准确度结果。

Abstract
This work proposes a general-purpose, fully-convolutional network architecture for efficiently processing large-scale 3D data. One striking characteristic of our approach is its ability to process unorganized 3D representations such as point clouds as input, then transforming them internally to ordered structures to be processed via 3D convolutions. In contrast to conventional approaches that maintain either unorganized or organized representations, from input to output, our approach has the advantage of operating on memory efficient input data representations, while at the same time exploiting the natural structure of convolutional operations to avoid the redundant computing and storing of spatial information in the network. The network eliminates the need to pre- or post process the raw sensor data. This, together with the fully-convolutional nature of the network, makes it an end-to-end method able to process point clouds of huge spaces or even entire rooms with up to 200k points at once. Another advantage is that our network can produce either an ordered output or map predictions directly onto the input cloud, thus making it suitable as a general-purpose point cloud descriptor applicable to many 3D tasks. We demonstrate our network’s ability to effectively learn both low-level features as well as complex compositional relationships by evaluating it on benchmark datasets for semantic voxel segmentation, semantic part segmentation and 3D scene captioning.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



