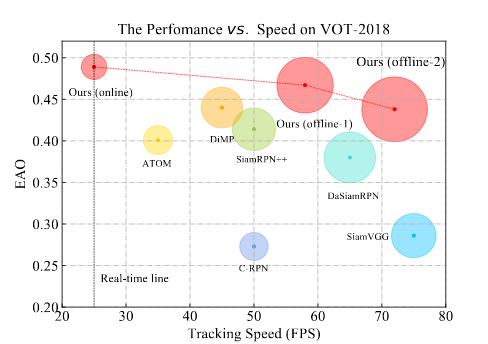
70+FPS!Ocean:Anchor-free实时目标跟踪网络 | ECCV 2020
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI深度学习视线 | 论文已上传,文末附下载方式
Ocean:目标感知的Anchor-free实时跟踪器,表现SOTA!
性能优于SiamRPN++、DiMP等网络,速度可高达70+ FPS!
论文链接:
https://arxiv.org/pdf/2006.10721.pdf
代码刚刚开源!
https://github.com/researchmm/TracKit
作者团队:中科院&微软
1
摘要

基于anchor的方法中的回归网络仅在正锚框中训练(即IoU≥0.6),该机制使得难以细化与目标对象重叠的anchor。
在本文中,我们提出了一个新颖的目标感知的anchor-free网络来解决这个问题:
首先,不完全参考anchor,而是以anchor-free方式直接预测目标对象的位置和比例。由于groundtruth框中的每个像素均受过良好训练,因此跟踪器能够在推理过程中纠正目标对象的不精确预测。
其次,引入特征对齐模块,以从预测的边界框中学习对象感知特征。目标感知功能可以进一步有助于目标对象和背景的分类。
此外,还提出了一种基于anchor-free模型的新型跟踪框架。
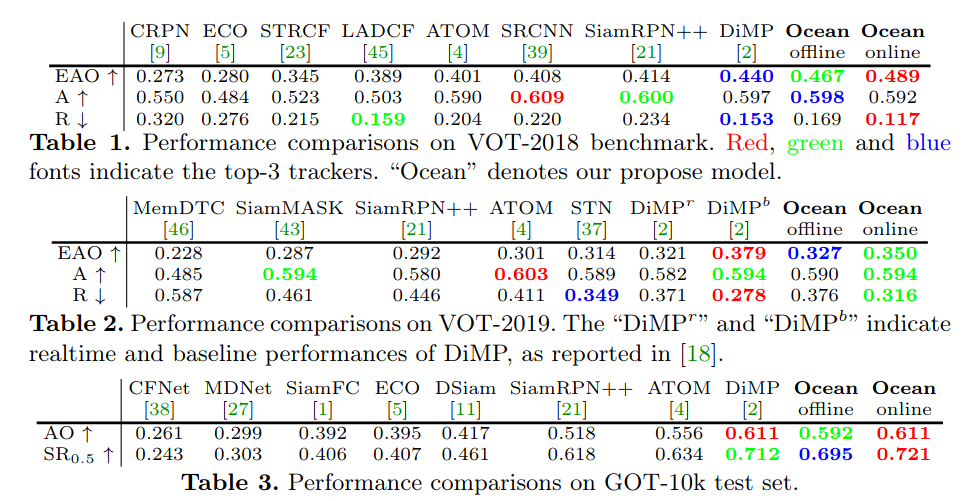
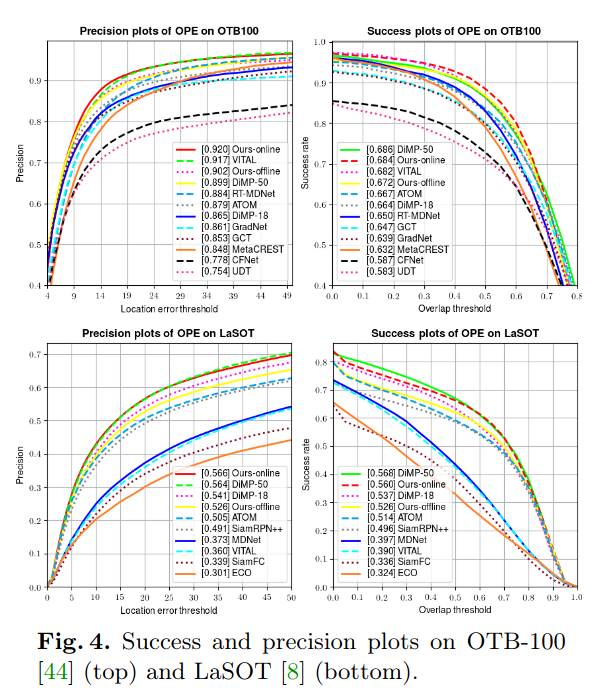
实验表明,我们的anchor-free跟踪器在五个基准上达到了最先进的性能,包括VOT-2018,VOT-2019,OTB-100,GOT-10k和LaSOT。
《Ocean: Object-aware Anchor-free Tracking》 其ECCV 2020论文名为:《Learning Object-aware Anchor-free Networks for Real-time Object Tracking》
2
主要思路
比较具有开创性的工作例如SINT[35]和SiamFC[1]使用Siamese网络学习目标和候选图像补丁之间的相似性度量,从而将跟踪建模为目标在整个图像上的搜索问题。大量的Siamese跟踪器被提出并取得了很好的效果。其中,被称为SiamRPN[22]的Siamese区域候选网络是其中的最具代表性的作品。SiamRPN引入了区域建议网络RPN[31],该网络由前景背景估计的分类网络和锚框优化的回归网络组成,即,学习预定义锚框的2D偏移量。这种基于锚的跟踪器在跟踪精度方面显示出了巨大的潜力。
缺点:
例如,由于跟踪误差的积累,对目标位置的预测可能变得不可靠。由于之前在训练集中看不到这种弱预测,回归网络无法对其进行修正。作为一个序列,跟踪器在随后的帧中逐渐漂移。
问题的提出:
人们很自然会提出这样一个问题:我们能设计一个具有纠正不准确预测能力的边界盒回归模型吗?
解决办法:
在这项工作中,我们证明了答案是肯定的:
我们的目标感知anchor-free跟踪器直接回归目标对象在视频帧中的位置,而不是预测锚盒的小偏移量!更具体地说,提出的跟踪器由两个部分组成:目标感知分类网络和边界盒回归网络。
当回归网络预测一个更准确的边界盒时(如校正弱的预测),相应的特征反过来有助于前景和背景的分类。我们使用预测的边界框作为参照来学习用于分类的对象感知特征。更具体地说,我们介绍了一个特征对齐模块,它包含一个二维空间变换,以对齐特征采样位置与预测的边界盒(即候选对象的区域)。该模块保证了采样在预测区域内,适应了目标尺度和位置的变化。因此,所学习的特征在分类时更具鉴别性和可靠性。
3
具体实现
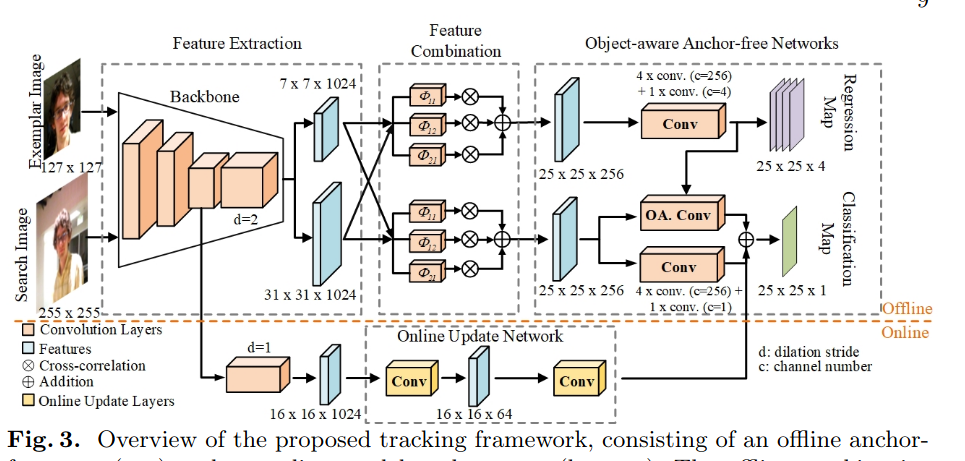
3.1 Object-aware Anchor-Free Networks
-
Anchor-free回归网络
为了解决当预测的边界盒变得不可靠时,跟踪器会快速漂移的问题,我们引入了一种新的无锚回归来进行视觉跟踪。它将groundtruth边界盒中的所有像素都作为训练样本。其核心思想是估计目标对象内每个像素到groundtruth边界盒的四个边的距离。其中,设
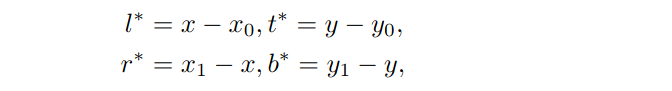
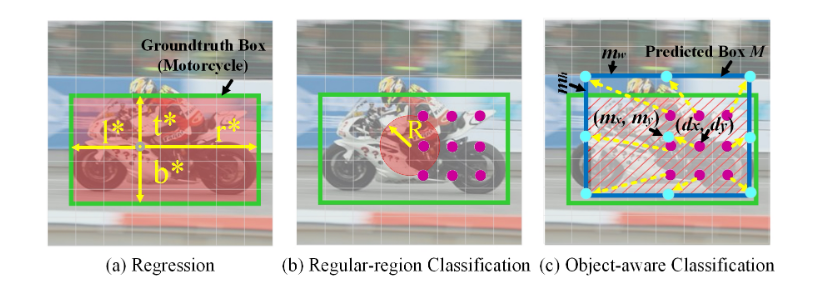
(b)正则区分类:靠近目标中心的像素,即红色区域,被标记为正样本。紫色点表示分数图中某个位置的采样位置。
(c)对象感知分类:预测盒和groundtruth盒的IoU,即训练时使用带有红斜线的区域作为标签。青色点代表提取对象感知特征的采样位置。黄色箭头表示空间变换产生的偏移量。
-
Object-aware Classification Network
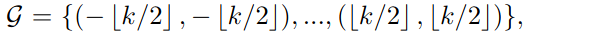
因此,我们提出在规则采样网格G上加一个空间变换T(图2C中的黄色箭头),将固定区域的采样位置转换为预测区域M。
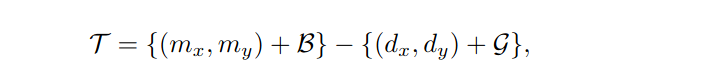
采样位置的转换可以适应视频帧中预测边界盒的变化。因此,所提取的目标感知特征对目标尺度的变化具有较强的鲁棒性,有利于跟踪过程中的特征匹配。此外,对象感知特征提供了候选目标的全局描述,使目标和背景的区分更加可靠。
Loss Function
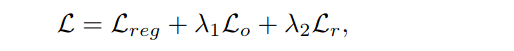
其中回归loss:
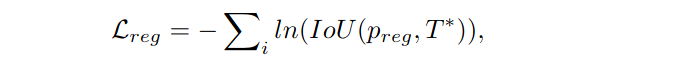
分类loss:
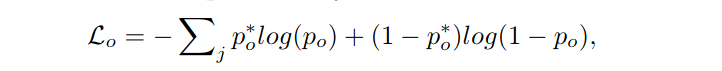
规则区域loss:
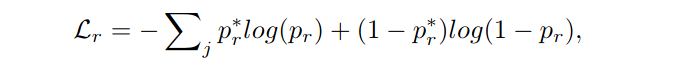
3.2 object-aware Anchor-Free Tracking
Framework
特征组合:
将提取的样本特征与搜索图像相结合,生成相应的相似度特征,用于后续的目标定位。与之前在多尺度特征上执行cross-correlationon的工作不同,我们的方法只在单一尺度上执行,即backbone的最后阶段。我们将单尺度特征通过三个平行扩张的卷积层[48],再将相关特征逐点求和融合,如图3(特征组合)所示。
目标定位:
这一步使用所提出的网络来定位搜索图像中的目标。分类网络预测的两个概率po和pr通过权重ω进行加权:
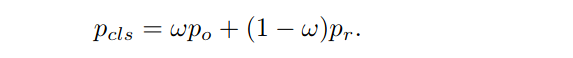
我们对尺度变化施加惩罚来抑制物体大小和高宽比的大变化,如下所示:
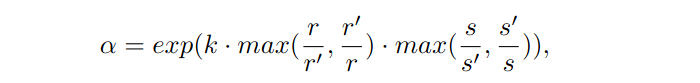
最终的目标分类概率计算
ˆpcl =α·pcl
-
Integrating Online Update
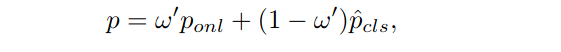
4
实验结果
下载
在CVer公众号后台回复:ECCV2020,即可下载上述内容
重磅!CVer-目标跟踪交流群成立
扫码添加CVer助手,可申请加入CVer-目标跟踪 微信交流群,目前已满1300+人,旨在交流语义分割、实例分割、全景分割和医学图像分割等方向。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标跟踪+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
点赞和在看!让更多CVer看见
