最新综述:图像分类中的对抗机器学习

©PaperWeekly 原创 · 作者|孙裕道
学校|北京邮电大学博士生
研究方向|GAN图像生成、人脸对抗样本生成


引言
最近百度自动驾驶出租车 Apollo GO 服务在北京全面开放,可见 AI 的各类应用在我们的日常生活中的渗透的广度和深度。需要提高警惕的是根植于深度神经网络模型的一个安全 bug(对样样本)也会随着各类 AI 应用的广泛铺展增多起来,自然对对抗攻击的防御性手段需要格外重视。

论文贡献
-
更新一些现有的分类方法法,以便对不同类型的对抗样本进行分类 -
基于新分类法的对抗攻击防御的机进总结和分析 -
将现有关于对抗样本存在原因的文献进行汇总 -
提出了一些在设计和评估防御措施时应遵循的重要指导原则 -
对该领域未来研究方向的进行了探讨

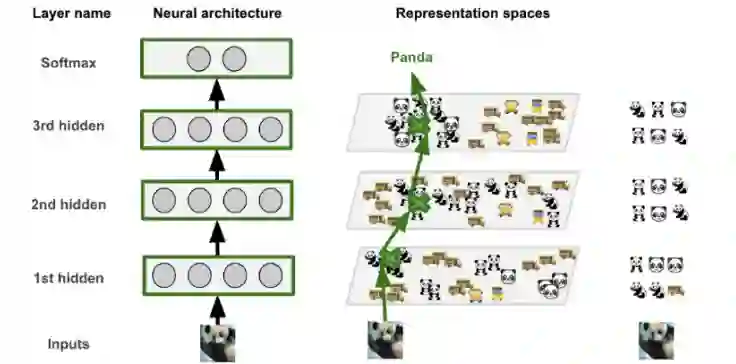
卷积神经网络简介
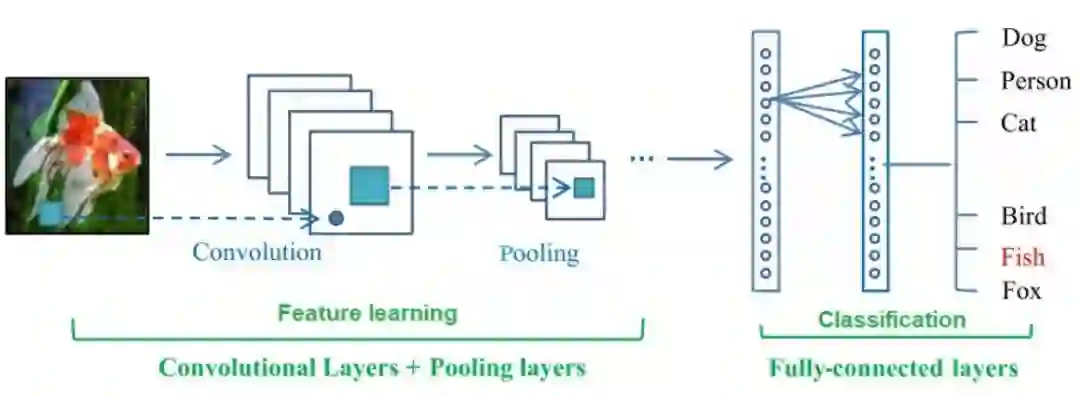
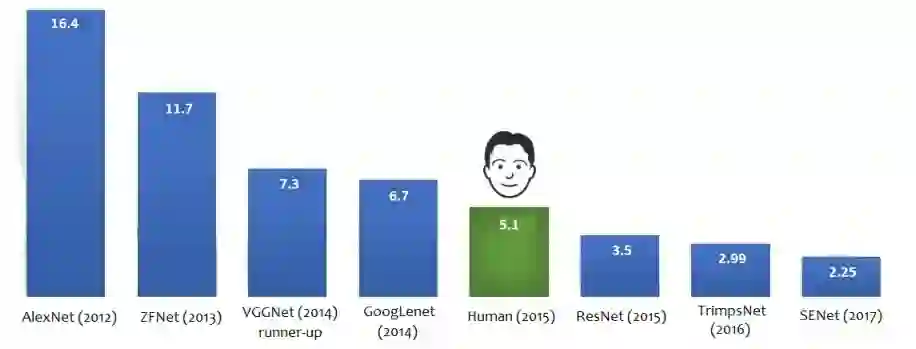

4.1 对抗攻击分类
4.1.1 对抗扰动范围
-
单个范围扰动:单个范围的扰动在文献中是最常见的,是针对于每一张输入图像进行对抗攻击。
-
通用范围扰动:通用范围扰动是图像无关的扰动,即它们是独立于任何输入样本而产生的扰动。然而,当它们被应用于一个合法的图像时,由此产生的对抗性示例通常会导致模型错误分类。通用扰动允许在实词场景中更容易进行对抗性攻击,因为这些扰动只需精心设计一次就可以插入到属于某个数据集的任何样本中。
4.1.2 对抗扰动的可见性
-
最优扰动:这些扰动对人眼来说是不可察觉的,但有助于导致深度学习模型的错误分类,通常对预测具有很高的可信度;
-
不可分辨的扰动:无法区分的扰动对人眼来说也是无法察觉的,但它们不足以愚弄深度学习模型;
-
可见扰动:当插入到图像中时,可以愚弄深度学习模型的扰动。然而,它们也很容易被人类发现;
-
物理扰动:扰动是否设计在像素范围之外,并实际添加到现实世界中的对象本身。尽管有些研究已经将物理扰动应用于图像分类,但它们通常都是针对涉及目标检测的任务。
-
愚弄噪声:使图像腐化到人类无法辨认的程度的扰动。然而,分类模型认为这些损坏的图像属于原始分类问题的一类,有时赋予它们对预测的高置信度。
-
普通噪声:与扰动的恶意性质不同,噪声是非恶意的或非最优的破坏,可能存在于输入图像中或插入到输入图像中。噪声的一个例子是高斯噪声。
4.1.3 对抗扰动的测量
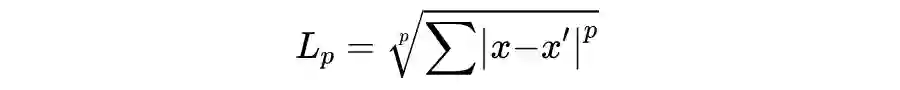
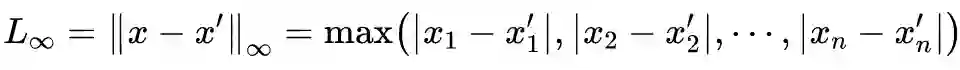
4.2 对抗攻击的分类
在安全的背景下,对抗性攻击和攻击者被归为威胁模型。威胁模型定义了防御设计的条件,在这种情况下,防御系统能够为特定类型的攻击和攻击者提供安全保障。
4.2.1 攻击者的影响力
-
中毒攻击:在中毒攻击中,攻击者在训练阶段会对深度学习模型产生影响。在这种类型的攻击中,训练样本被破坏或训练集被攻击者污染,以产生与原始数据分布不相容的分类模型;
-
规避或试探性攻击:与中毒攻击相比,在试探性攻击中,攻击者在推理或测试阶段对深层学习模型产生影响。规避攻击是最常见的攻击类型,攻击者会精心设计对抗样本,导致深度学习模型错误分类,通常对预测具有较高的可信度。规避攻击还具有探索性,攻击者的目标是收集有关目标模型的信息,例如其参数、体系结构、损失函数等。最常见的探索性攻击是输入/输出攻击,攻击者向目标模型提供由其生成的对抗样本。然后,攻击者观察模型给出的输出,并尝试重新生成一个替代或代理模型,以便可以模仿目标模型。输入/输出攻击通常是执行黑盒攻击的第一步。
4.2.2 攻击者的知识
-
白盒攻击:攻击者可以完全访问模型甚至防御的参数和架构。由于采取了保护措施(例如,用户控制),以防止未经授权的人员访问系统组件,这种攻击场景在真实应用程序中可能是最不常见的。相比之下,白盒攻击通常是最强大的对抗攻击类型,因此,通常用于评估防御和/或分类模型在恶劣条件下的鲁棒性。
-
黑盒攻击:攻击者既不能访问也不知道有关分类模型和防御方法的任何信息。黑盒攻击对攻击者施加了更多的限制,尽管如此,当针对部署的模型再现外部对抗性攻击时,黑盒攻击非常重要,而部署模型又能更好地代表真实世界的场景。尽管黑盒攻击的执行难度更大,但由于对抗样本的可转移性,攻击者仍然可以避开目标模型。利用这一特性,攻击者可以通过一个称为替代或代理模型的因果攻击创建一个经验模型,该模型的参数与目标模型的参数相似。
-
灰盒攻击:在灰盒攻击中,攻击者可以访问分类模型,但不能访问任何有关防御方法的信息。灰盒攻击是评估防御和分类器的一种中间选择,因为与黑盒攻击相比,灰盒攻击施加了更大的威胁级别,但在向攻击者提供有关防御方法的所有信息时(如在白盒场景中执行的),灰盒攻击不会给攻击者带来很大的优势。
4.2.3 安全入侵
-
完整性入侵:这是对抗攻击最常见的侵犯行为,当由某个攻击者生成的对抗样本能够绕过现有的防御对策并导致目标模型错误分类,但不会损害系统的功能时,完整性会受到影响;
-
可用性入侵:当系统功能受到破坏时,从而导致拒绝服务时发生。可用性入侵主要通过提高预测的不确定性来影响学习系统的可靠性;
-
隐私入侵:当攻击者能够访问有关目标模型的相关信息时发生,例如其参数、体系结构和使用的学习算法。深度学习中的隐私侵犯与黑盒攻击密切相关,在黑盒攻击中,攻击者查询目标模型,以便对其进行反向工程,并生成一个代理模型,从而对对抗样本更接近原始数据分布。
4.2.4 攻击的特异性
4.2.5 攻击方法
-
基于梯度的攻击:这种攻击方法在现在的研究中是使用最多的。基于梯度攻击的算法利用目标模型相对于给定输入梯度的详细信息。这种攻击方法通常在白盒场景下执行,当攻击者完全了解并访问目标模型时;
-
基于得分的攻击:这种攻击算法要么依赖于对目标模型使用的数据集的访问,要么依赖于它预测的分数来近似于一个梯度。通过查询目标深层神经网络得到的输出作为分数。然后将这些分数与训练数据集一起用于拟合一个代理模型,该模型将精心设计将插入到合法图像中的扰动。这种攻击方法通常在黑盒攻击中很有用;
-
基于决策的攻击:与基于梯度的攻击相比,它只需要很少的参数变化,因此被作者认为是一种更简单、更灵活的方法。基于决策的攻击通常查询目标模型的 softmax 层,并通过使用拒绝采样过程迭代计算较小的扰动;
-
基于近似的攻击:这种方法的攻击算法通常采用数值方法来逼近由不可微技术形成的目标模型或防御系统的梯度。然后利用这些近似梯度来计算对抗性扰动。
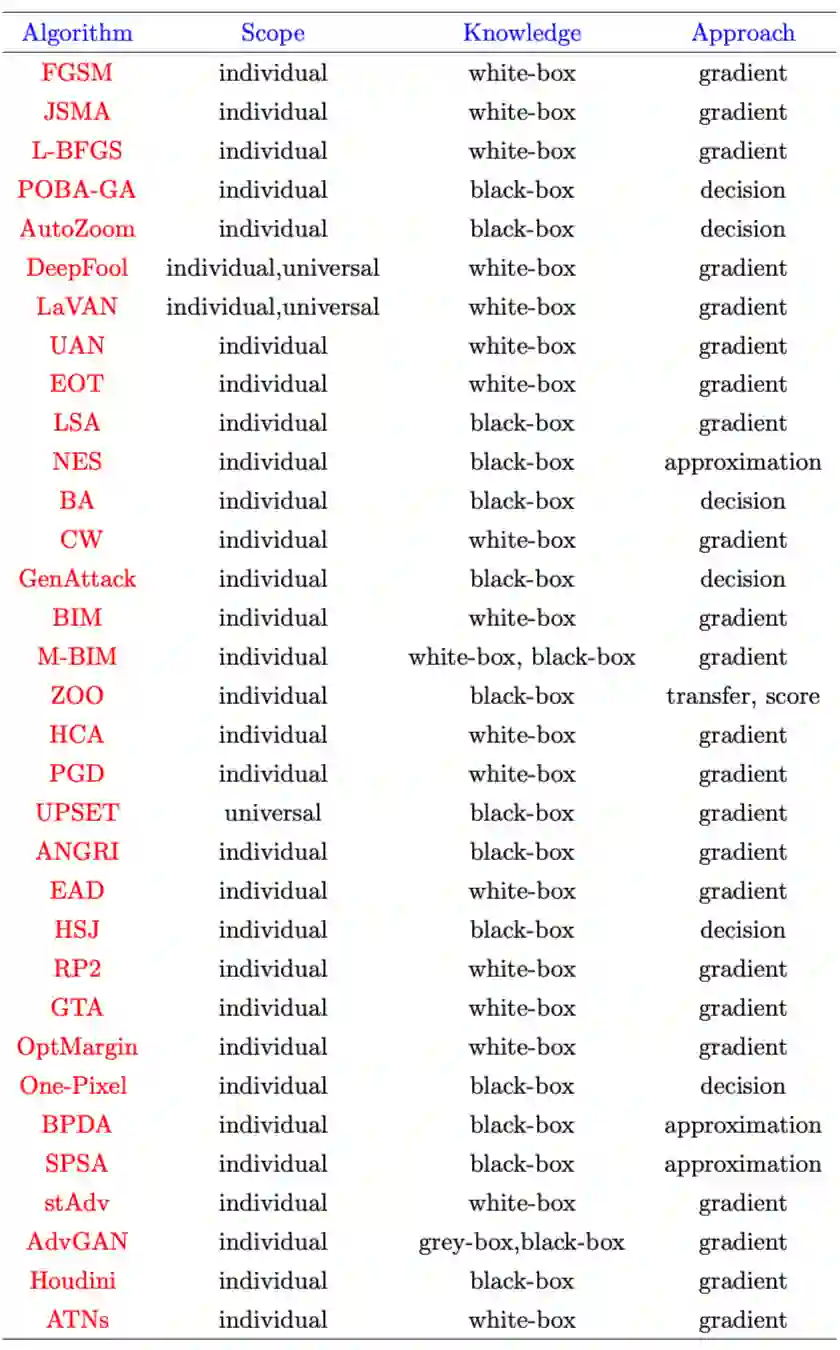
4.2.6 攻击算法分类一览
在计算机视觉中,用于产生对抗扰动的算法是一种优化方法,通常在预先训练的模型中发现泛化缺陷,以便在干净图像中生成对抗扰动。

5.1 防御目标
5.2 防御方法
5.2.1 梯度掩蔽
-
破碎梯度:通过不可微防御引起,从而引入不存在或不正确的坡度;
-
随机梯度:输入到分类器之前对输入进行随机预处理,这种梯度掩蔽策略通常导致对抗攻击错误估计真实梯度;
-
梯度爆炸/消失:由非常深的体系结构形成的防御引起,通常由神经网络评估的多次迭代组成,其中一层的输出作为下一层的输入。
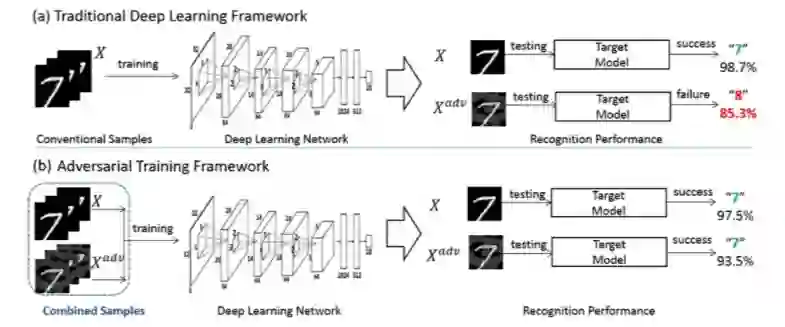
5.2.2 对抗训练
基于对抗训练的防御方法通常被认为是一种很简单粗暴的方法去防御对抗攻击。对抗训练的主要目的是通过在包含干净和对抗图像的数据集中训练,使分类模型更加健壮。
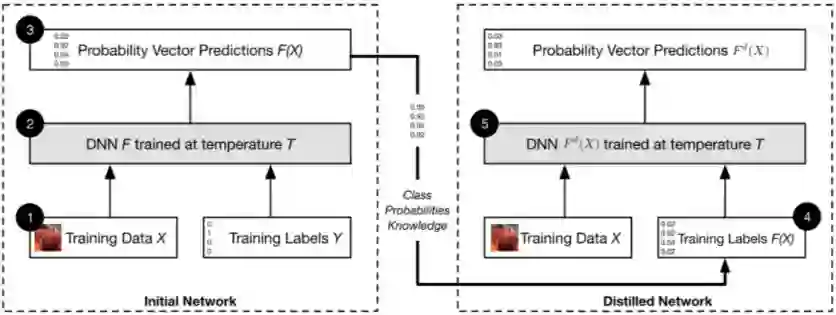
5.2.3 防御蒸馏
防御蒸馏是一种主动性防御。这个对策的灵感来自学习模型间知识转移的特性。在学习蒸馏中,复杂模型所获得的知识在使用确定的数据集进行训练后,被转移到更简单的模型上。
5.2.4 特征压缩
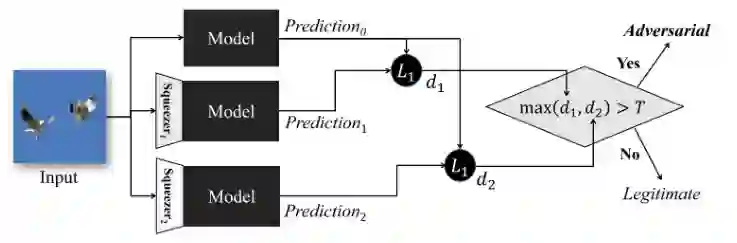
5.2.5 分类器集合
5.2.6 近邻测量
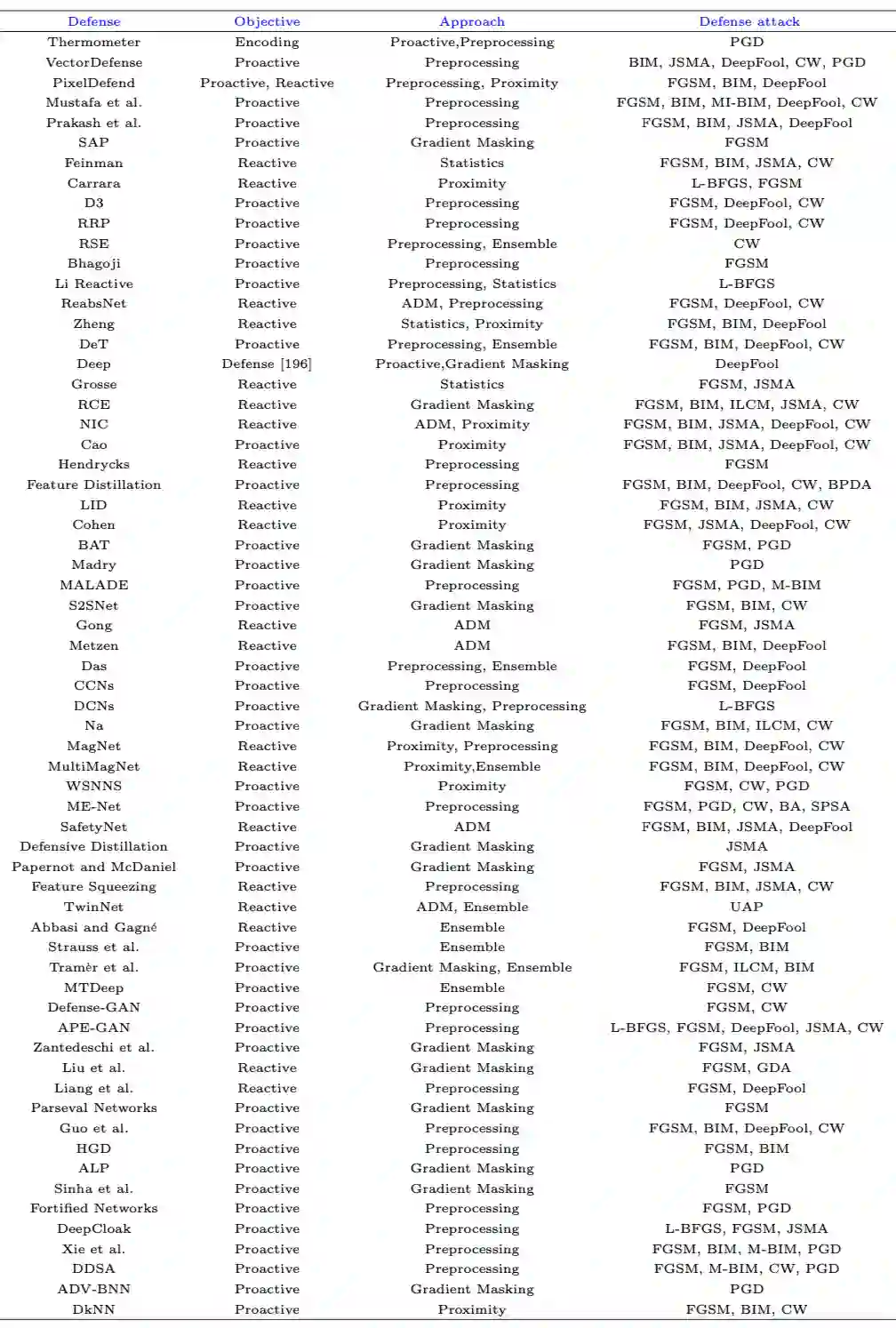
5.2.7 防御性算法一览

对抗样本存在性解释
通过推理对抗样本影响机器学习模型预测的原因,了解对抗样本的存在和性质,通常是在阐述对抗机器学习中攻击和防御时考虑的第一步。CNN 和其他机器学习算法在对抗性攻击的恶意影响之前所呈现的漏洞被普遍称为聪明汉斯效应。
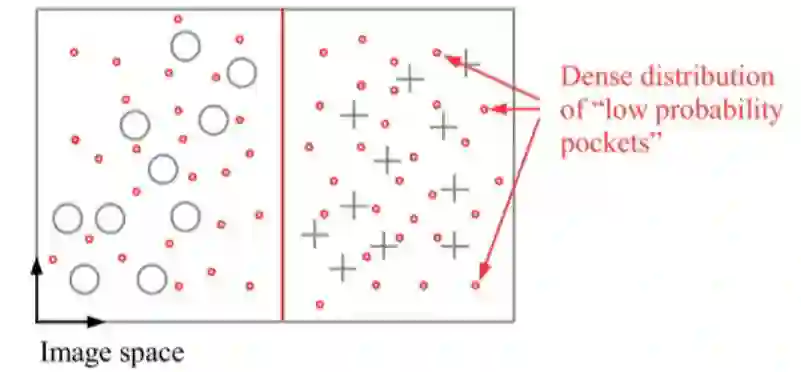
6.1 高度非线性化假设
6.2 线性化假设
Goodfellow 反驳了 Szegedy 等人的非线性假设。假设 DNN 有一个非常线性的行为,由几个激活函数引起,比如 ReLU 和 sigmoid,它们使微小的扰动输入保持在同一个错误的方向上。
6.3 边界倾斜假说
这种假设与 Szegedy 等人给出的解释更为相关,即学习的类边界靠近训练样本流形,但该学习边界相对于该训练流形是“倾斜”的。
6.4 高维流形
6.5 缺乏足够的训练数据集
6.6 非稳健特征假设
基于对抗扰动的存在并不一定意味着学习模型或训练过程的缺陷,而是图像的特征。通过考虑人类的感知,作者将特征分为鲁棒特征(使得模型即使在受到不利干扰时也能正确预测真实类)和非鲁棒特征(从数据分布模式中获得的具有高度预测性)。
作者提出利用训练 DNN 的 logits 层构造一个新的数据集,该数据集由包含鲁棒特征的图像组成,这些特征是通过训练 DNN 的 logits 层从原始输入图像中过滤出来的。然后,这个数据集被用来训练另一个用于进行比较研究的 DNN。

论文总结
自从 Szegedy 等人的工作首次发现这个问题以来,科学界一直在努力寻找其他方法来防御对抗攻击。但是在众多的防御方法中,虽然一开始很有希望,但已经证明所有的防御手段都是脆弱的,对阻止强大对抗攻击是无效的。
更多阅读



#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




