【深度】小数据,大任务!详解英特尔中国研究院的视频物体分割解决方案
来源:英特尔中国研究院
第 31 届 计算机视觉和模式识别大会(CVPR2018)于近日在美国盐湖城圆满落幕。作为计算机视觉、模式识别和人工智能领域的国际顶级会议之一,本次大会一如既往地吸引了大量学者和企业的关注。除了高水平的科研论文,大会期间的各项竞赛亦是吸睛无数。
来自英特尔中国研究院的团队首次参加了基于视频的物体分割竞赛(DAVIS Challenge on Video Object Segmentation),并在主竞赛“基于半监督的视频物体分割”(Semi-supervised Video Object Segmentation)中取得第四名。

物体分割是人工智能领域中一个基础而又艰巨的任务,在自动驾驶、智能机器人等行业都发挥着重要作用。物体分割是为了找到图像中目标物体的像素级区域。在本次DAVIS竞赛上,参赛者的任务是基于视频中第一帧图像上目标物体的人工标注,通过算法自动标注剩余视频帧上对应的物体。如下图所示,人工标注提供了第一帧上人和自行车的区域,参赛者则需提供算法在剩余所有帧上自动标注这两个物体对应的区域。

基于半监督的视频物体分割任务
近年来,基于大数据驱动的深度学习技术迅速发展,已成为包括物体分割等领域的主流技术。然而在DAVIS竞赛中,每个物体只有一张标注图像。此时若直接利用当下流行的深度学习算法,容易导致对第一帧图像过拟合,无法适应视频中背景和前景的多样变换。

针对该问题,我们的团队在此次竞赛中提出了基于在线生成数据的自适应视频分割方法。其基本思想如下图所示,首先利用基于大数据的深度学习网络获得关于每个物体的外观、形状等先验知识,并生成针对目标物体的候选训练样本,再从中挑选出正确的样本加入训练集。这些训练样本随着视频帧的增加而不断累积,用于更新每个目标物体的分割模型,使其更加精准。

基于在线生成数据的自适应视频分割方法的基本思想
该方法的核心在于:在线生成和累计训练数据用于优化分割网络,实现分割网络对视频中所有帧的逐步自适应。下图展示了该方法的系统框图,包含两个主要模块:物体分割模块和在线数据生成模块。物体分割模块(Instance Segmentation Module)包含一个或多个分割网络(Segmentation Net),分别用于对视频中的每个目标物体进行分割。在线数据生成模块 (Online Data Generation Module)包含三个不同的网络:通用知识网络(General Knowledge Net),跟踪网络 (Tracking Net),和再识别网络(Re-identification Net)。其中,通用知识网络用于提供每个目标物体可能的训练样本,跟踪和再识别网络用于找出正确的训练样本。
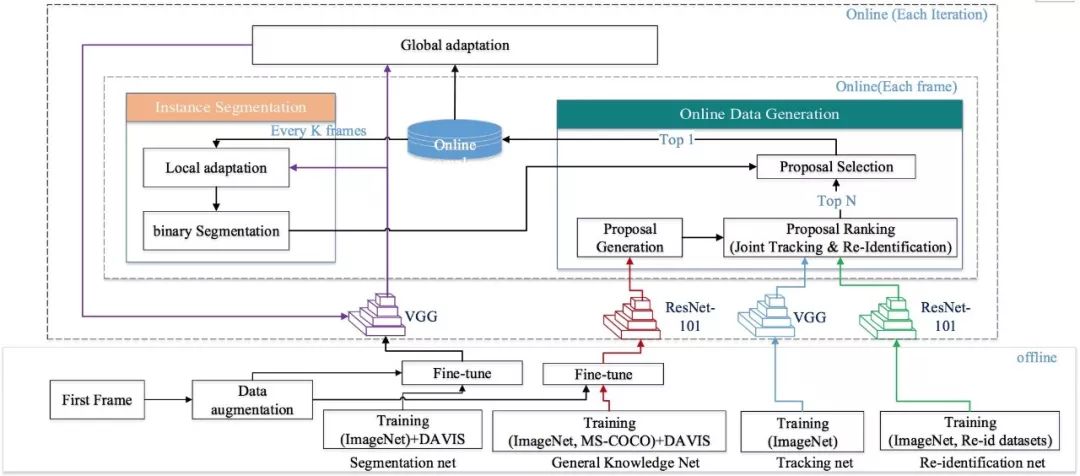
基于在线生成数据的自适应视频分割系统框图
该方法运行过程如下所示。为了保证在线样本的正确性,我们采用迭代方式逐步增加样本。每次迭代只收集当前模型可以确定正确的样本,随着迭代次数的增加,模型的精度不断提高,收集的样本也逐渐变多。在一次迭代过程中,我们对视频中的每一帧图像按先后顺序依次处理,首先利用分割网络对每个目标物体进行分割,同时将该图像输入到通用知识网络提取候选的训练样本。然后联合跟踪网络和再识别网络的结果,并将此结果与分割网络的结果进行一致性对比,来找到满意的训练样本(dt),并将其加入到训练样本集合D。
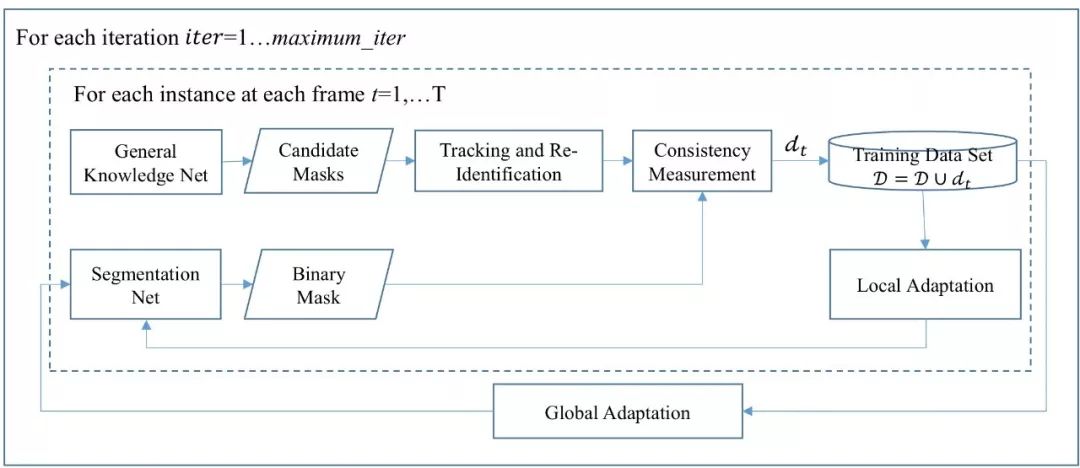
基于在线生成数据的自适应视频分割流程图
得到的训练样本用于对分割网络进行优化,从而实现对视频中不同内容的自适应。这个自适应过程分为两个层次进行,局部自适应(Local Adaptation)和全局自适应(Global Adaptation)。其中,局部自适应是在一次迭代过程中的每张图像上进行,而全局自适应则在每次迭代结束时在整体视频上进行,如下所示。
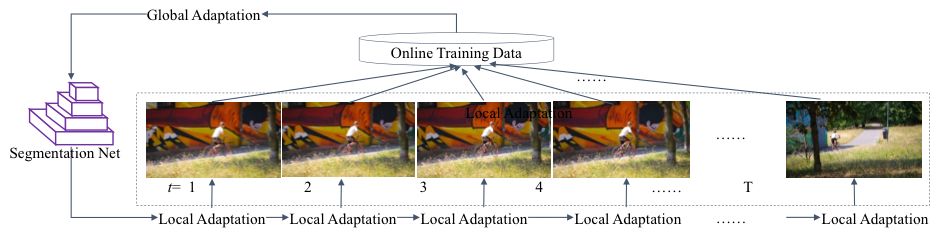
多层次的模型自适应过程
局部和全局自适应对训练样本采取不同的采样概率。局部自适应对最近几帧图像的训练样本使用较大的采样概率,对距离较远的帧所对应的样本使用较小的采样概率,其目的是挑选出与下一帧图像内容相近的样本,在下一帧上得到好的分割结果并收集正确的训练样本。全局自适应对所有训练样本进行均匀采样,从而使分割模型对变化的内容具有鲁棒性。这两层自适应过程相互交替,迭代进行,逐步实现分割网络对所有帧的自适应。

当前大多数深度学习算法都依赖大数据训练,而实际应用往往只能得到少量的训练样本。因此,我们提出的基于在线生成训练数据的方法可以在很多小数据的场景中发挥作用,通过在线收集样本来逐步完善网络的表达能力。目前,英特尔中国研究院的研究员们正基于这项技术,开发针对家庭服务机器人的自适应物体识别软件开发包。此类软件开发包将在智能机器人、智能家居,甚至自动驾驶等领域发挥作用。欢迎大家持续关注!
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】CVPR 2018 | 牛津大学&Emotech首次严谨评估语义分割模型对对抗攻击的鲁棒性
☞【学界】谷歌大脑提出自动数据增强方法AutoAugment:可迁移至不同数据集
☞【干货】DeepMind 提出 GQN,神经网络也有空间想象力

