商汤科技62篇论文入选CVPR 2019,多个竞赛项目夺冠
心心念念,人工智能从业者翘首以盼的CVPR 2019终于来了!
作为与ICCV、ECCV并称为计算机视觉领域三大国际会议之一,本届CVPR大会共收到5265篇有效投稿,接收论文1300篇,接收率为25.2%。
相比2018年,本届CVPR的论文提交数量增加了56%,但论文接收率却下降了3.9%,可见论文入选难度有很大提升,也可以看出AI学术会议的关注度也愈加火热。

再次突破,商汤62篇论文入选CVPR 2019
根据官网数据,商汤科技及联合实验室共有62篇论文被接收,其中口头报告(Oral)论文就有18篇。相比2018 CVPR共44篇论文入选,增幅超40%。
商汤科技CVPR 2019录取论文在多个领域实现突破,包括:高层视觉核心算法——物体检测与分割、底层视觉核心算法——图片复原与补全、面向自动驾驶场景的3D视觉、面向AR/VR场景的人体姿态迁移、无监督与自监督深度学习前沿进展等。这些突破性的计算机视觉算法有着丰富的应用场景,将为推动AI行业发展做出贡献。
值得一提的是,在CVPR 2019 Workshop NTIRE 2019视频恢复比赛中(包含两个视频去模糊和两个视频超分辨率),来自商汤科技、香港中文大学、南洋理工大学、中国科学院深圳先进技术研究院组成的联合研究团队获得了全部四个赛道的所有冠军,且大幅超越每个赛道的其他团队。
视频恢复不是图像恢复的简单应用,因为其含有大量的时空冗余信息可以利用。目前行业最好的图像超分辨算法是RCAN恢复,但使用EDVR算法视频超分辨率的结果能看到更多的细节,效果大幅提升。作者发明了一种新的网络模块PCD 对齐模块,使用Deformable卷积进行视频的对齐,整个过程可以端到端训练。而且在挖掘时域(视频前后帧)和空域(同一帧内部)的信息融合时,作者发明了一种时空注意力模型进行信息融合。此次比赛的EDVR算法代码已开源(https://github.com/xinntao/EDVR)。
另外,商汤科技还在AI CITY Challenge(CVPR 2019 Workshop)异常检测赛道中获得冠军。城市智慧交通面临数据质量差、标签数据少、缺乏高质量算法模型以及从边缘到云端的计算资源不足等挑战,该比赛更多地通过迁移学习、无监督和半监督的方法检测交通异常,如道路事故、车辆故障等,从而帮助城市交通变得更安全和智能。
兼容并包,持续推动开放学术交流
2000多年前,孔子曰:“三人行,必有我师焉”,其强调了开放交流,互相学习的重要性。1916年,蔡元培先生受命担任北京大学校长时也提出“思想自由,兼容并包”的办学方针。
连续数年在计算机视觉领域获得全球领先的科研成果背后,是商汤科技深厚的AI人才储备、科研底蕴和创新能力,更源于商汤对基础技术研发的高度重视,以及坚持开放学术交流的态度。
本届CVPR期间,商汤科技与香港中文大学多媒体实验室联合举办的“SenseTime PartyTime”活动,为计算机视觉领域的全球教授、研究人员和学生们提供了一个交流和分享的机会。
商汤科技联合创始人、港中文-商汤联合实验室主任林达华教授,分享商汤与学术界合作的主要成果,以及商汤科技的人才优势和战略、企业文化等。

Panel Discussion
在场学者们进行密切互动交流

CVPR 2019大会现场,商汤科技展台展示
的多项AI科技吸引了诸多与会者前来体验
Open-MMLab计划,推动学术生态建设
现代AI系统日趋复杂,涉及很多的关键细节,这些细节的优化和调节需要长时间的专注和积累。因此,AI研究的未来推进,也将需要越来越多不同研究背景的团队共同参与,让每个团队专注于某一个方面的开拓与探索。
在这样的背景下,商汤科技启动Open-MMLab计划,希望在一个统一的代码架构上,逐步开放实验室积累的算法和模型,为计算机视觉的研究社区贡献自己的一份力量。
目前,商汤科技和香港中文大学多媒体实验室(MMLab)联合开源了两个重要的纯学术代码库MMDetection和MMAction,推动AI行业更加深入和开放的学术交流。
MMDetection是一个基于PyTorch的开源物体检测工具包。该工具包采用模块化设计,支持多种流行的物体检测和实例分割算法,并且可以灵活地进行拓展,在速度和显存消耗上也具有优势。(https://github.com/open-mmlab/mmdetection)
目前已经支持单阶段检测器如SSD/RetinaNet/FCOS/FSAF,两阶段检测器如FasterR-CNN/Mask R-CNN,多阶段检测器如Cascade R-CNN/Hybrid Task Cascade等,另外支持许多相关模块如DCN/Soft-NMS/OHEM等,也支持混合精度训练。有很多最新的工作也在MMDetection上开源。
团队为之提供了完整的训练和测试框架,以及超过200个训练好的模型及其测试结果,希望能为社区提供统一的开发平台和测试基准,助力物体检测的相关研究。
MMAction是一个基于Pytorch的开源视频动作理解工具包,囊括了视频动作分类、时域动作检测(定位)、时空动作检测等视频理解的基础任务。(https://github.com/open-mmlab/mmaction)
目前已经支持双流、TSN、SSN等动作分类和动作检测框架和基于Fast R-CNN的时空动作检测基线模型,支持Plain 2D/Inflated3D/Non-local等流行的网络结构,支持UCF-101、Something-Something、Kinetics、THUMOS14、ActivityNet、AVA等视频数据集,并提供相关的预训练模型。
作为Open-MMLab系统开源项目的一部分,团队希望MMAction可以成为视频研究人员的测试平台,促进视频动作理解领域更上新台阶。
商汤及联合实验室CVPR 2019论文精选
下面,列举几篇商汤及商汤联合实验室入选CVPR 2019的代表性论文,从五大方向阐释计算机视觉和深度学习技术最新突破。
高层视觉核心算法——物体检测与分割
代表性论文:基于混合任务级联的实例分割算法
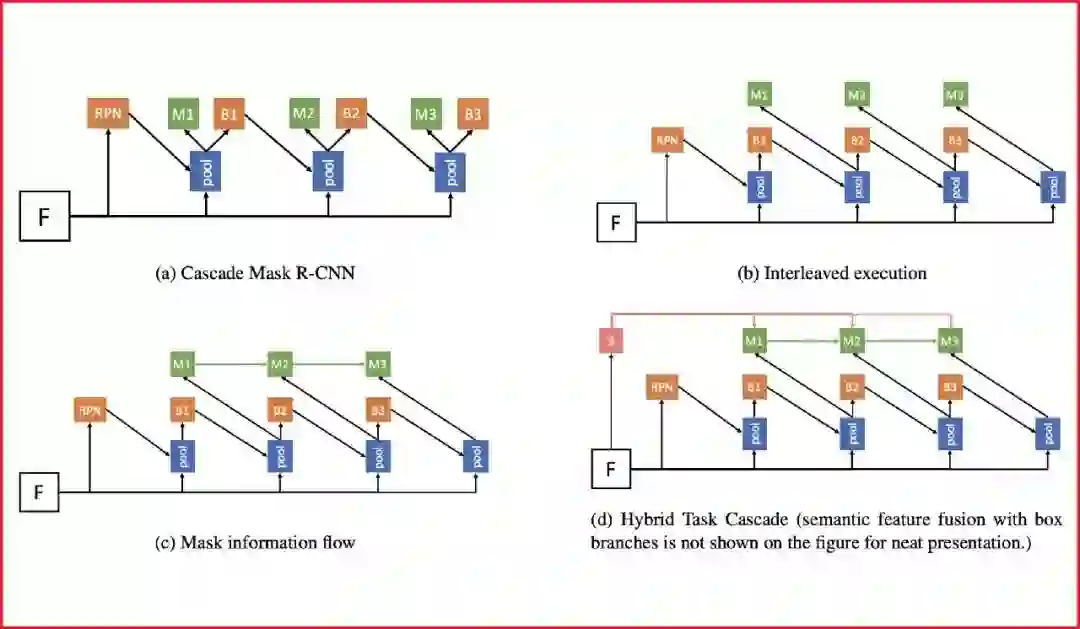
对于很多计算机视觉任务来说,级联是一种经典有效的结构,可以对性能产生明显提升。但如何将级联结构引入实例分割的任务仍然是一个开放性问题。简单地将物体检测的级联结构Cascade R-CNN与经典的实例分割算法Mask R-CNN进行结合,带来的提升比较有限。
在这篇论文中,我们提出了一种新的框架Hybrid Task Cascade (HTC)。该框架是一个多阶段多分支的混合级联结构,对检测和分割这两个分支交替地进行级联预测,除此之外,我们还引入了一个全卷积的语义分割分支来提供更丰富的上下文环境信息。HTC在COCO数据集上相对Cascade Mask R-CNN获得了1.5个点的提升。基于提出的框架,我们获得了COCO 2018比赛实例分割任务的冠军。
代表性论文:基于特征指导的动态锚点框生成算法
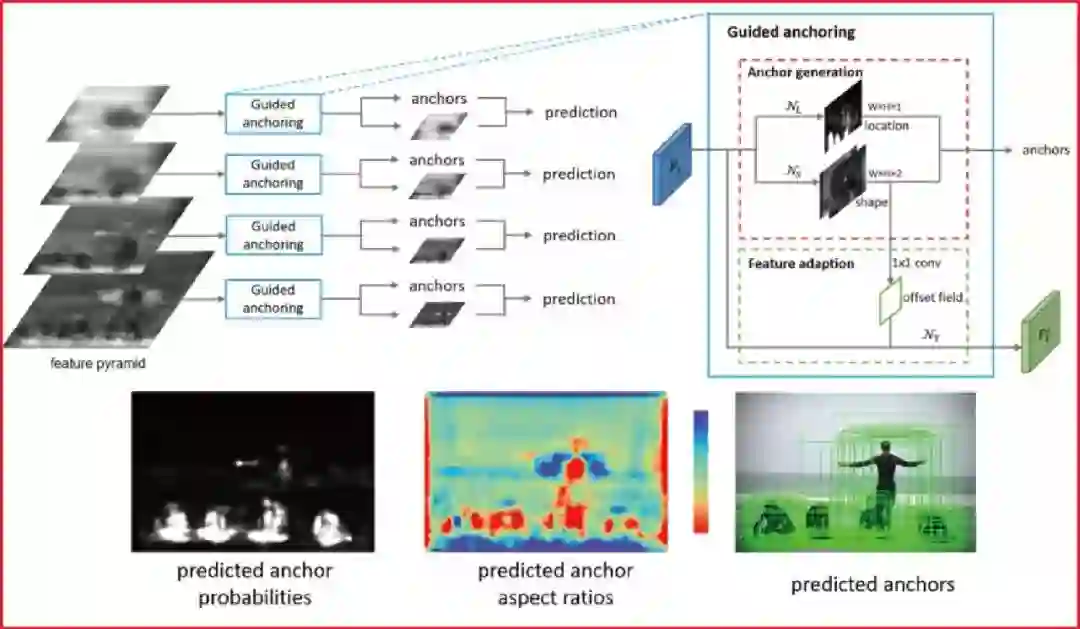
锚点框(Anchor)是现代物体检测技术的基石。目前主流的物体检测方法大多依赖于密集产生静态锚点框的模式。在这种模式下,有着预定义的大小和长宽比的静态锚点框均匀的分布在平面上。
本文反思了这一关键步骤,我们提出了一种基于特征指导的动态锚点框生成算法,该算法利用语义特征来指导锚点框生成的过程,具有高效率和高质量的特点。本算法可以同时预测目标物体中心区域和该区域应产生的锚点框的大小和长宽比,以及根据锚点框的形状来调整特征,使特征与锚点框相吻合,从而产生极高质量的动态锚点框。
本方法可以无缝使用在各种基于锚点框的物体检测器中。实验表明本方法可以显著提高三种最主流的物体检测器(Fast R-CNN, Faster R-CNN, RetinaNet)的性能。
底层视觉核心算法——图片复原与补全
代表性论文:基于网络参数插值的图像效果连续调节

图像效果的连续调节在实际中有着广泛的需求和应用, 但是目前基于深度学习的算法往往只能输出一个固定的结果,缺乏灵活的调节能力来满足不同的用户需求。
针对这个问题, 本文提出了一种简单有效的方式来达到对图像效果的连续光滑的调节,而不需要进一步繁杂的训练过程。该方法能够在许多任务上得到应用, 比如图像超分辨率,图像去噪,图像风格转换,以及其他许多图像到图像的变换。
具体地,我们对两个或多个有联系的网络的参数进行线性插值,通过调节插值的系数,便可以达到一个连续且光滑的效果调节。我们把这个在神经网络的参数空间中的操作方法称为网络参数插值。本文不仅展示了网络参数插值在许多任务中的应用,还提供了初步的分析帮助我们更好地理解网络参数插值。
代表性论文:基于光流引导的视频修复

本文关注视频中的修复问题,虽然近年来图片修复(Image Inpainting)问题取得了很大的进展,可是在视频上完成像素级的修复仍热存在极大的挑战。其困难主要在于:1)保证时序上的连续型;2)在高分辨率下实现修复;3)降低视频对于计算的开销。
本文致力于解决这三个问题,同时尽可能保证视频的清晰度。在研究中我们发现,保证视频的时序一致性,对于视频修复任务来说非常重要,这不仅仅保证了修复后的视频能够有良好的观看体验,同时还帮助我们从视频本身来抽取真实的像素块来实现更加高效地修复。
所以我们的框架主要由两部分组成,第一部分是通过深度神经网络实现光流的补全,之后通过补全的光流在整个视频间做像素的传导,从而形成一条在时序上保持一致的像素链。这样缺失的区域就可以通过它来实现修复,并且还能够保证视频的清晰度。
面向自动驾驶场景的3D视觉
代表性论文:PointRCNN: 基于原始点云的3D物体检测方法
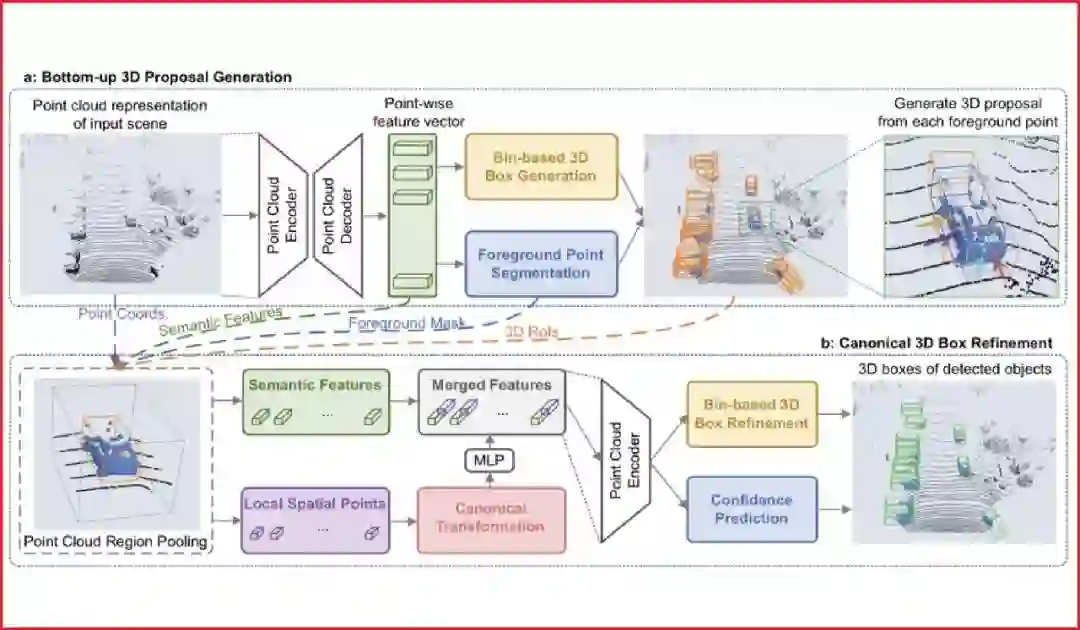
本文首次提出了基于原始点云数据的二阶段3D物体检测框架,PointRCNN。3D物体检测是自动驾驶和机器人领域的重要研究方向,已有的3D物体检测方法往往将点云数据投影到鸟瞰图上再使用2D检测方法去回归3D检测框,或者从2D图像上产生2D检测框后再去切割对应的局部点云去回归3D检测框。而这些方法中,前者在将点云投影到俯视图上时丢失了部分原始点云的信息,后者很难处理2D图像中被严重遮挡的物体。
我们观察到自动驾驶场景中物体在3D空间中是自然分离的,从而我们可以直接从3D框的标注信息中得到点云的语义分割标注。因此本文提出了以自底向上的方式直接从原始点云数据中同步进行前景点分割和3D初始框生成的网络结构,即从每个前景点去生成一个对应的3D初始框(阶段一),从而避免了在3D空间中放置大量候选框。
在阶段二中,前面生成的3D初始框将通过平移和旋转从而规则化到统一坐标系下,并通过点云池化等操作后得到每个初始框的全局语义特征和局部几何特征,我们将这两种特征融合后进行了3D框的修正和置信度的打分,从而获得最终的3D检测框。
在提交到KITTI的3D检测任务上进行官方测试时,我们提出的方法在只使用点云数据的情况下召回率和最终的检测准确率均超越了已有的方法并达到了先进水平。目前我们已将该方法的代码开源到了GitHub上。
面向AR/VR场景的人体姿态迁移
代表性论文:基于人体本征光流的姿态转换图像生成
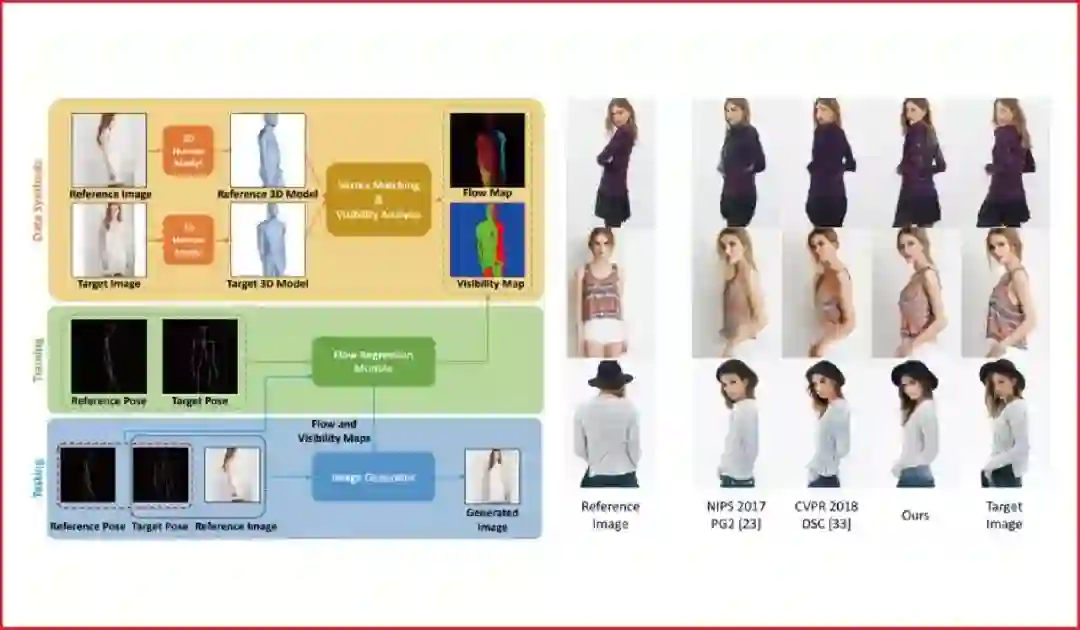
本文主要关注人体姿态转移问题,即在给定一幅包含一个人的输入图像和一个目标姿态的情况下,生成同一个人在目标姿态下的图像。我们提出利用人体本征光流描述不同姿态间的像素级对应关系。
为此,我们设计了一个前馈神经网络模块,以原始姿态和目标姿态作为输入,迅速对光流场进行估计。考虑到真实光流数据难以获取,我们利用3D人体模型拟合图像中的人体姿态,生成对应姿态变化的光流场数据,用于模型训练。
在该光流预测模块的基础上,我们设计了一个图像生成模型,利用本征光流对人体的外观特征进行空间变换,从而生成目标姿态下的人体图像。我们的模型在DeepFashion和Market-1501等数据集上取得了良好的效果。
无监督与自监督深度学习前沿进展
代表性论文:基于条件运动传播的自监督学习
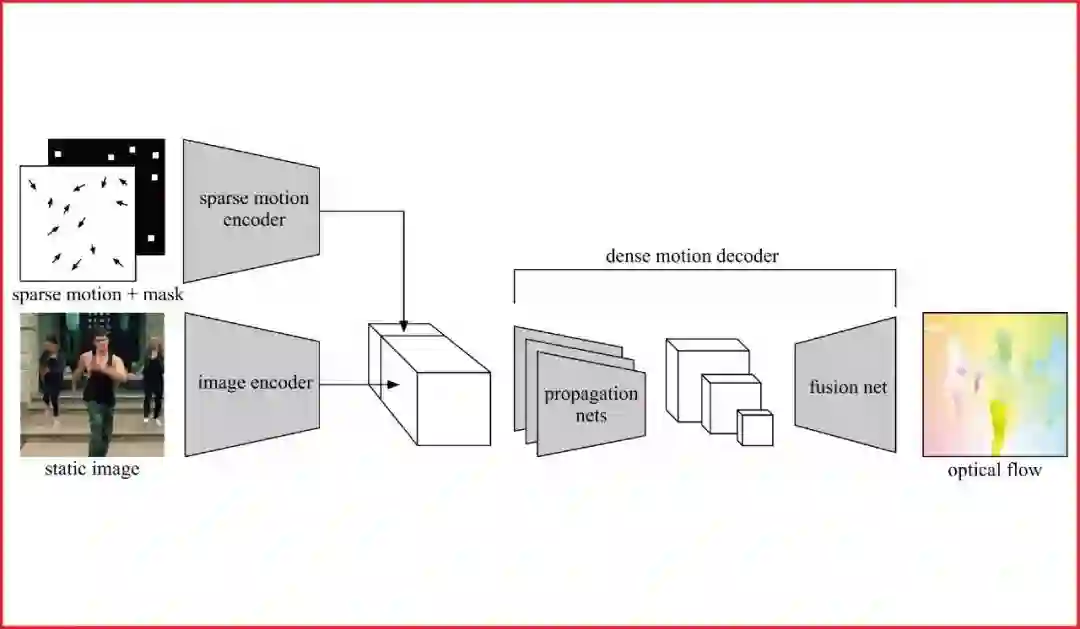
本文提出一种从运动中学习图像特征的自监督学习范式。1)在自然场景中,物体的运动具有高度的复杂性,例如人体和常见动物都具有较高的运动自由度。2)同时,从单张图片中推测物体的运动具有歧义性。现有基于运动的自监督学习方法由于没有很好地解决这两个问题,因而未能高效地从运动中学习到较好的图像特征。
为此,我们提出了条件运动传播这个自监督学习任务。训练时,我们将单张图像作为输入,将目标运动场中抽样出来的稀疏运动场作为条件,训练神经网络去恢复目标运动场。这样训练完的图像编码器可以用来作为其他高级任务的初始化。我们在语意分割、实例分割和人体解析等任务中相比以往自监督学习方法获得了较大提升。
经过分析,我们发现条件运动传播任务从运动中学习到了物体的刚体性、运动学属性和一部分现实世界中的物理规律。利用这些特性,我们将它应用到交互式视频生成和半自动实例标注,获得了令人满意的效果;而整个过程,没有用到任何人工的标注。