学界 | Science论文揭秘:Libratus如何在双人无限注德扑中击败人类顶级选手
选自Science
作者:Noam Brown、Tuomas Sandholm
机器之心编辑部
Libratus 提出了一种在大型状态空间、隐藏信息中有效地应对博弈论推理挑战的方法;它在 12 万手单挑无限注德州扑克比赛中击败了四个顶尖的人类选手,成功解决了处理不完美信息博弈的领先基准问题与长期存在的挑战。由于现实世界策略交互中的隐藏信息无处不在,因此 Libratus 引入的范式将在 AI 的未来发展和广泛应用中发挥重要作用。
近年来,人工智能已经取得了非常大的进步。很多情况下,这种进步体现在基准游戏中和人类表现的对比。目前 AI 程序已在跳棋、国际象棋和围棋等击败了人类顶尖选手。在这些完美信息博弈中,双方都知道博弈中每一个点的确切状态。相反在不完美信息博弈中,关于博弈状态的一些信息是隐藏的,即博弈中存在包含多个决策点的信息集或博弈者无法区分对手的一些行动。隐藏信息在现实世界策略互动中无处不在,这使得研究不完美信息博弈的技术更加重要。
由于多种原因,隐藏信息使博弈变得更加复杂。对于不完美信息博弈而言,AI 不是简单地搜索一个最佳行动序列,而是必须确定如何适当地行动,这样对手才不会过多地发现我方所拥有的私人信息。例如虚张声势是任何竞技性扑克都需要的技巧,但经常唬人就会被对方抓住特点而被击败。因此换句话来说,一个行动获得的价值取决于它出现的概率。
另一个关键点是博弈的不同部分不能独立地考虑。对于一个给定的情况,最佳策略可能取决于未发生情况下将执行的策略。因此,一个竞争性的 AI 总需要考虑整个游戏的策略。
扑克游戏作为理解隐藏信息的博弈有很长历史,而德扑是目前最受欢迎的扑克游戏之一。由于其庞大的规模和复杂的战略,单挑无限注德州扑克(HUNL)已经成为近年来不完美信息博弈研究的主要游戏和基准挑战问题。这个游戏中,之前没有 AI 击败过顶尖的人类玩家。
在本论文中,我们介绍了 Libratus,它采用了一种独特的方法来处理不完美信息博弈。该 AI 在为期 20 天、拥有 20 万奖金池、总数 12 万手的竞赛中,击败了 HUNL 顶尖选手。Libratus 中的技术并不是使用专家领域知识或人类数据,也不是专门针对扑克的,因此它们适用于大量不完美信息博弈。
论文:Superhuman AI for heads-up no-limit poker: Libratus beats top professionals

论文链接:http://science.sciencemag.org/content/early/2017/12/15/science.aao1733/tab-pdf
摘要:无限注德州扑克是最流行的扑克形式之一。尽管人工智能在完美信息博弈中取得了成功,但私人信息和大规模博弈树使得无限制博弈问题很难解决。我们提出了 Libratus,它在 12 万手单挑无限注德州扑克比赛中击败了四个顶尖的人类选手,解决了处理不完美信息博弈的领先基准问题与长期存在的挑战。我们的博弈论方法以独立于应用的技术为特征:一个算法用于计算总体策略的蓝图,另一个算法在博弈中求解并充实子博弈的具体策略,还有一个自提升算法用于修正可能存在的弱点,该弱点可能已经在对手的蓝图策略中得到了识别与针对。
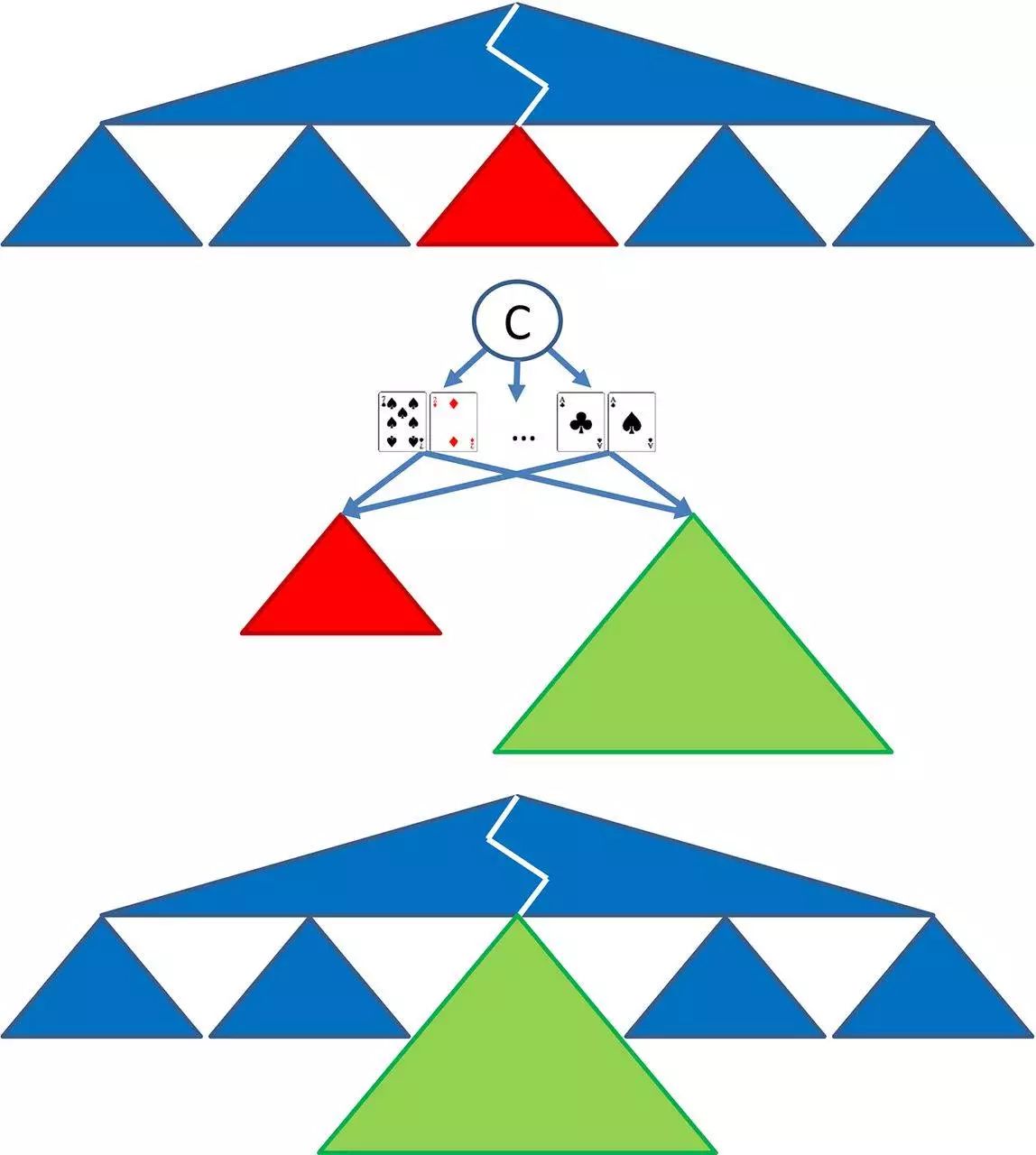
图 1:子博弈求解
上:博弈过程中出现了一个子博弈。中:通过求解一个增强子博弈,为该子博弈确定一个更加详细的策略,其中每次迭代中的对手持有一个随机牌组,并给出了策略选择,选择旧抽象(红色)的期待值,或选择新的细粒度的抽象(绿色,其中对弈双方的策略都是可变的)。这迫使 Libratus 将细粒度策略设置成至少和初始抽象(和所有的对手牌组对弈)一样好。下:新策略取代了原来的策略。

图 2:嵌套子博弈解决方案的 2A 可视化。每次在游戏中达到一个子博弈,就会为这个子博弈构建和解决一个更加详细的抽象,同时将其解决方案纳入整体蓝图策略之中。

图 3:Libratus 与人类顶级玩家的表现对比。上图给出了 2017 Brains vs. AI 的竞赛结果。其中 95% 的置信区间(如果手牌相互独立且分布相同)由虚线表示。
结论
Libratus 提出了一种在大型状态空间、隐藏信息中有效地解决博弈论推理挑战的方法。我们开发的技术在很大程度上是独立于领域的,因此可被应用于其他不完美信息的应用,包括非娱乐性应用。由于现实世界策略交互中的隐藏信息无处不在,我们认为 Libratus 引入的范式对 AI 的未来发展和广泛应用将非常重要。

Noam Brown、Tuomas Sandholm现身reddit问答,详细回答了Libratus的相关问题。
详情请查看reddit链接:https://www.reddit.com/r/MachineLearning/comments/7jn12v/ama_we_are_noam_brown_and_professor_tuomas/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论。



