如何做个小冰那样成功的聊天机器人

每天都有成百上千的新机器人出现,似乎每个人都在探索聊天机器人的发展。事实上,聊天机器人的市场规模估计会从2016年的70330万美元增长到2021年的32亿美元。在不断扩大的的聊天机器人的海洋中,如何让你的聊天机器人脱颖而出?有49.4%的人说他们可以通过电话与商家联系,让他们将生产聊天机器人提上日程。这里有一些方法能让你的聊天机器人脱颖而出。
爱闲聊的机器人是最好的
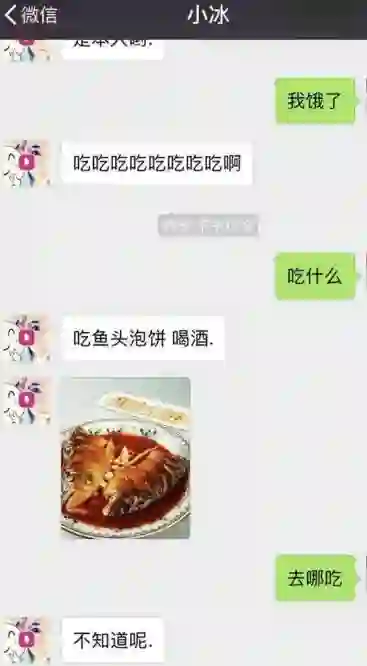
最好的聊天机器人会观察人类,人们偶尔会犯拼写错误——聊天机器人也是一样的。如果聊天机器人对于外界的每一种反应都是完美的,它的结构就会变得很复杂。可以给你的机器人加入容错机制,让他看起来带点随意的感觉,但要记住始终与之保持对话。最好的机器人可以从对话中学习然后将这些知识使用到与人类的交流中。
例如,佐治亚理工学院的教学助理聊天机器人Jill Watson,它建立在IBM watson平台的基础上,它从与数十个研究生的对话中进行学习。有了四个学期的数据和40000个问题和答案的支撑,Jill Watson可以阅读论坛和研究学生如何在对话中使用笑话和专业术语,最终,Jill Watson将学到的笑话应用于对话中,到了学期末,学生们甚至觉得Jill Watson就是一个真实的人,而不是聊天机器人。这个想法并不是要欺骗你的用户,而是要确保机器人能以对话的方式进行交流,并易于交互。
记忆促进交流
多亏了人工智能和机器学习,比如有了IBM Watson和其他工具,机器人才可以进行个性化对话并且帮助人们完成任务。聊天机器人能实现这些功能的关键是进行上下文存储。机器人应该记住用户是谁以及与以前用户发生的事情,使用连接到后端服务器的数据库很容易设置上下文存储。例如,如果你让机器人给你推荐一个餐厅,机器人可以根据你过去的喜好提出一个地点。当你问机器人“你为什么推荐这家餐厅?”机器人会回答你它是引用了你以前的偏好。人类的记忆容量为250万千兆字节,很快机器人的记忆容量也会达到这个数量级。
建立一个后果机制
在目前与聊天机器人进行对话时,大约70%的人类反应被误解了。例如,如果其他的用户问你的机器人一个在机器人存储的专业知识之外的问题,机器人应该有一个类似“我没有这些信息,点击这里来和人说话”的回答,而不是用“我不知道”或“我不明白”来回答;用户偶尔会拼写错误,或者使用不太标准的语法,在这种情况下,机器人就不会思考了,只因为在这里存在了错误。所以加入一个后果机制,而且可以从中学习是很重要的,机器人就可以返回到错误的数据产生的地方,并允许程序员对下一个交互进行更正。令人满意的是,仅仅在300人的注释解释后,大部分的客户服务的精确度可以达到80%到95%。
在构建机器人之前,请考虑用户界面
虽然你可能知道自己的机器人要做什么,但在开始编程之前,请考虑如何部署机器人。首先,你必须区分它是一个聊天机器人还是声音机器人,如果是一个聊天机器人,请考虑是要使用Facebook Messenger,Slack还是网站,每个平台都有独特的特点,通常服务于不同的用户。媒体会影响你使用这三种中的哪一种,所以了解你的用户以及用户最有可能在哪种情况下使用聊天机器人是很重要的。如果你的用户长时间使用其中一种,你将更好的与聊天机器人进行互动。
聊天机器人不仅仅是客户服务引擎
虽然大多数聊天机器人的开发都是基于客户服务领域,但新应用程序的潜力是无穷无尽的。聊天机器人目前被用于养成新习惯,导航美国的移民系统,甚至是筹款方面。有一个叫Yeshi的机器人,它生活在埃塞俄比亚,你可以通过Messenger和它进行交流,可以了解更多关于水危机的信息。这款机器人可以模拟人们为了找到干净的水而步行超过两个小时,并通过图像、GIF和视频来给人们展示它的日常生活。
随着每天数以千计的机器人的产生,聊天机器人的数量将继续扩大,并在不断发现新用例的情况下用在所有的行业里。机器人无处不在,所以你可以生产一个完全改变人们做事方式的机器人。







