抛弃 RNN 和 LSTM 吧,它们不好!
作者简介:Eugenio Culurciello是FWDNXT的CTO兼总裁,在神经网络领域(包括软硬件)有着近20年的从业经验。

长期以来我们迷恋循环神经网络(RNN)、长短期记忆(LSTM)及其所有衍生版本。现在是时候抛弃它们了!
2014 年,RNN和LSTM起死回生,打了场漂亮的翻身仗。我们都读过Colah的博文《了解LSTM网络》
(http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
和 Karpathy 对RNN大唱赞歌的文章《效果无比出色的循环神经网络》
(http://karpathy.github.io/2015/05/21/rnn-effectiveness/)
此后几年,RNN和LSTM是解决序列到序列学习(seq2seq)转换的方法,这还促使语音到文本理解方面取得了出色的成果,并直接促成了Siri、Cortana、谷歌语音助理和 Alexa大行其道。此外别忘了机器翻译或神经机器翻译,不仅能够将文档翻译成不同的语言,还能够将图像翻译成文本、将文本翻译成图像以及将视频翻译成自然语言等,RNN和LSTM的流行程度想必你也有数了。
在随后几年(2015年至2016 年),出现了ResNet:
(https://arxiv.org/abs/1512.03385)
和Attention:

(注意力,https://arxiv.org/abs/1502.03044)
我们因此有了更深入的认识,LSTM是一种巧妙绕过的技术。基于注意力的模型也表明,可以对受上下文向量(context vector)影响的网络求平均值(averaging),以此取代MLP网络。下文会详细讨论这方面。
才过了两年多的时间,现在我们可以肯定地说:
“抛弃你的RNN和LSTM吧,它们不好!”
不要只听我们的一面之词,不妨看看表明基于注意力的模型被谷歌、Facebook和Salesforce等巨头越来越多地使用的迹象。所有这些公司将RNN及衍生版本换成了基于注意力的模型,而这只是个开始。RNN在各种应用场景下时日无多,因为相比基于注意力的模型,RNN需要更多的资源来训练和运行。请参阅以下文章可了解更多信息。
(https://towardsdatascience.com/memory-attention-sequences-37456d271992)
但原因何在?
要知道,RNN、LSTM 及衍生版本使用的主要是顺序处理。参阅下图中的水平箭头:
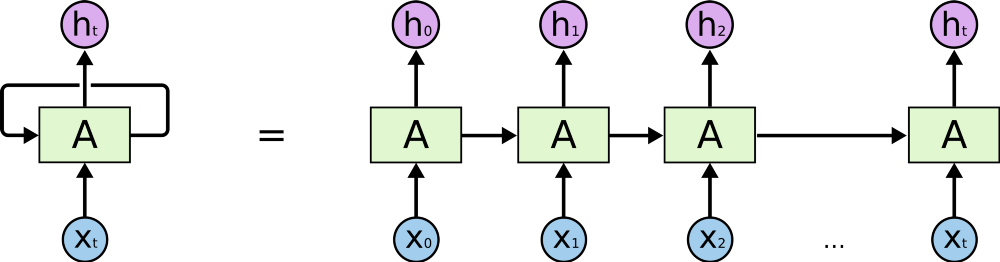
RNN中的顺序处理,来自http://colah.github.io/posts/2015-08-Understanding-LSTMs/。
这个箭头意味着,长期信息到达当前处理单元之前,要按顺序通过之前的所有单元。这意味着长期信息很容易因< 0的小数多次相乘而受到损坏。这就是梯度消失的根源。
为此,LSTM模块应运而生,如今可以将它视为多个转换门(switch gate)。有点像ResNet,它可以绕过一些单元,因而记忆更长的时间步。因此,LSTM有方法可以消除一些梯度消失问题。
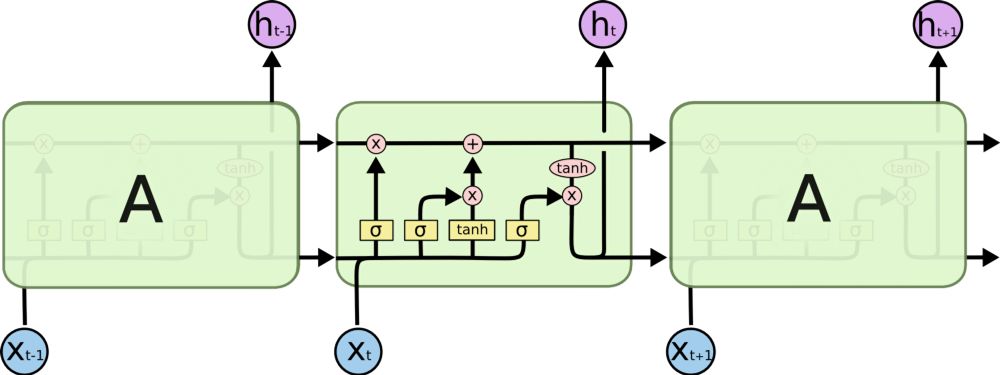
LSTM 中的顺序处理,来自http://colah.github.io/posts/2015-08-Understanding-LSTMs/。
但不能解决所有梯度消失问题,如上图所示。我们仍存在一条从旧的过去单元到当前单元的顺序路径。实际上,现在这条路径来得还要复杂,因为添加分支和遗忘分支连接在路径上。毫无疑问,LSTM、GRU及衍生版本能够学习大量的长期信息!参见此处的结果(http://karpathy.github.io/2015/05/21/rnn-effectiveness/),但是它们只能记住上百个字符,而不是上千或上万个字符。
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
RNN的一个问题是,它们很耗费硬件资源。容我解释一下:快速训练RNN需要大量的资源,而我们没有这这么多资源。在云端运行这种模型同样需要大量资源;考虑到市场对语音到文本的需求迅猛增长,云无法灵活扩展。我们需要在边缘处理,甚至直接在Amazon Echo端处理!
你该如何是好?
如果要避免顺序处理,那么我们得找到“向前预测”或“向后回顾”的单元,因为大多数时候我们处理的是实时因果数据:我们知道过去的情况,想要影响未来的决策。这与翻译句子或分析录制视频时不一样:我们拥有所有数据,可以对它推理多次。这种向前预测和后向回顾的单元是神经注意力模块,我们之前在此作过解释(https://medium.com/@culurciello/neural-networks-building-blocks-a5c47bcd7c8d)。
这时候,“层次型神经注意力编码器”应运而生,结合了多个神经注意力模块,如下图所示:
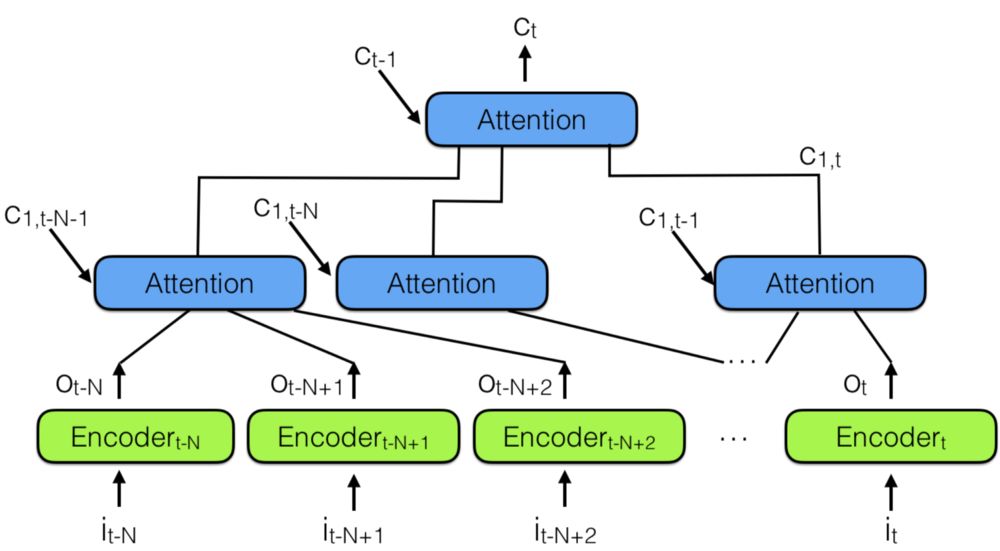
层次型神经注意力编码器
想了解过去,一种更好的方法是,使用注意力模块将所有过去的编码向量总结为上下文向量Ct。
请注意:这里有注意力模块的层次体系,非常类似神经网络的层次体系。这还类似时间卷积网络(TCN),文末附注3有介绍。
在层次型神经注意力编码器中,多层注意力模块可查看最近过去的一小部分,比如100个向量,而上面层可查看100个这样的注意力模块,实际上整合了100×100个向量的信息。这将层次型神经注意力编码器的能力扩大到10000个过去的向量。
这就是回顾更多过去信息、预测未来的一种方法。
但更重要的是看一下将表示向量传播到网络输出所需要的路径长度:在层次型网络中,它与log(N)成正比,其中N是指层次体系的层数。这与RNN需要执行的T步骤形成了对照,其中T是需要记住的顺序的最大长度,而T >> N。
如果你跳3次至4次,而不是跳100次,更容易记住顺序!
这种架构类似神经图灵机,但是让神经网络通过注意力决定从记忆中读取什么。这意味着,实际的神经网络将决定过去的哪些向量对未来的决策很重要。
但存储到记忆方面怎么样?不像神经图灵机,上面的架构将所有之前的表示存储在记忆中。这可能效率相当低:设想一下存储一段视频中每个帧的表示――大多数时候,表示向量并不逐帧改变,所以我们其实在存储太多的相同信息!我们能做的是,添加另一个单元以防止关联数据存储起来,比如不存储与之前存储的向量太相似的向量。但这其实是一种改动,最好的方法还是让应用程序指导哪些向量应保存、哪些不应保存。这是当前研究领域的重点。
所以总之,忘了RNN及衍生版本。使用注意力模块。你需要的其实是注意力模块!
把这告诉你的朋友们!让人非常惊讶的是,那么多公司仍在使用RNN/LSTM用于语言到文本的处理,许多公司没有意识到这些网络效率非常低下、无法灵活扩展。让他们有空读一读本文。
补充信息
关于RNN/LSTM训练:RNN和LSTM训练起来很难,因为是它们需要受内存带宽限制的计算,这对硬件设计师来说是最可怕的,最终限制了神经网络解决方案的适用性。简而言之,LSTM需要每个单元4个线性层(MLP层),以便每个顺序时间步运行一次。线性层需要大量的内存带宽才能执行计算;常常由于系统没有足够的内存带宽将数据馈送到计算单元,实际上它们无法使用许多计算单元。添加更多的计算单元很容易,但添加更多的内存带宽却很难(芯片上要有足够多的线路,从处理器到存储器要有长长的连线,等等)。因而,RNN/LSTM及衍生版本对硬件加速而言不是很搭,我们之前探讨过这个问题(https://medium.com/@culurciello/computation-and-memory-bandwidth-in-deep-neural-networks-16cbac63ebd5和https://towardsdatascience.com/memory-attention-sequences-37456d271992)。一种解决方案就是在存储器设备中执行计算。
附注
附注1:层次型神经注意力类似WaveNet中的想法。但我们不使用卷积神经网络,而是使用层次型注意力模块。
附注2:层次型神经注意力也可能是双向的。
附注3:这篇论文(https://arxiv.org/abs/1803.01271)比较了CNN和RNN。时间卷积网络(TCN)“在面对一系列广泛的任务和数据集时比典型的循环网络(比如LSTM)更胜一筹,同时展现了更出色的长期记忆。”

附注4:与这个话题有关的一点是,我们对人脑如何学记顺序信息知之甚少。“我们常常学记和回忆小片段的长顺序信息,比如将电话号码858 534 22 30分四个片段来记。行为实验表明,人类和一些动物在处理众多任务时采用这种策略,将认知或行为顺序分解成小块。”――这些小块让我想到了小型卷积或注意力网络处理小顺序信息,然后按照层次体系串联起来,就像层次型神经注意力编码器和时间卷积网络(TCN)中那样。更多的研究使我认为,工作记忆(working memory)类似使用循环真实神经元网络的RNN网络,它们的容量非常低。另一方面,皮质和海马让我们能够记住顺序很长的步骤(比如:5天前我将车子停在机场的哪个位置),这表明可能需要用到更多的平行路径才能记起顺序很长的步骤。

附注5:上述证据表明我们并不按顺序阅读,实际上我们将字符、单词和句子作为一组来解读。基于注意力的模块或卷积模块可以感知这个顺序,并将这种表示投射在大脑中。如果我们按顺序处理这些信息,就不会误读!我们会停下来,注意到不一致的地方!
欢迎加入行业交流群,群主微信:aclood(备注任职单位+职位,否则不予通过)
相关阅读:
神经网络、AI 很简单!所以......别再装逼、佯称自己是个天才!




