【论文笔记】用于动作识别的空间残差层和密集连接块增强的时空图卷积网络
导读
近期的研究表明,利用图卷积网络(GCN)对人体的动态关节特征进行建模是基于骨骼的动作识别的一种开创性方法。然而,如何对相关骨架信息进行建模和综合利用仍然是一个悬而未决的问题。为了捕捉丰富的时空信息,更有效地利用特征,文中引入了空间残差层和密集块增强的时空图卷积网络,在降低复杂度的同时提取更精确、丰富的时空特征。
贡献
这篇文章的主要贡献如下:
1)文中提出了一个跨域空间残差层,可以有效的捕获时空信息;
2)提出了一种密集连接块用于ST-GCN学习全局信息,提高特征的鲁棒性;
3)空间残差层和密集连接块增强的时空图卷积网络在两个基准数据集上具有相当或优于最新方法的性能。
方法概述
准备工作
图的定义
在一个图G = (V,E)中,V是节点的集合,E是边的集合,连接相邻的节点。A是图的邻接矩阵。如果第i个与第j个节点间存在连接,则A_{i,j}=1,否则A_{i,j}=0.图G的归一化邻接矩阵定义为:
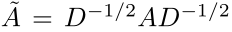
其中:
D是图G的度矩阵
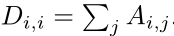
对于每一个骨架数据,整个人体骨架构成一个图形结构,其中骨架的关节和骨胳是图形的点和边,使用特征矩阵表示关节的坐标信息(可以是2D或3D坐标(x,y)或者(x,y,z)),特征矩阵表示为:
X∈R^{n*d*T}
其中:
n是一帧中的关节数
d是关节空间坐标的维度
T表示一个视频中的帧数
X_t = X_{:,:,t}是第t帧的关节位置信息
X^i_t = X_{i,:,:,t}是第i的节点的在第t帧的关节位置信息
时空图卷积网络
让X∈R^{n*d_in}为关节的输入特征,Y∈R^{n*d_out}为通过图卷积操作获得的输出特征,图卷积操作可以计算为:
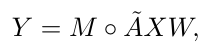
其中:
~A是归一化的邻接矩阵,可以计算为:
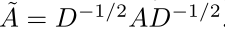
M∈R^{n*n}与W∈R^{n*d_out}是可训练权重表示边与节点的重要性
时空图卷积新的结构
基于原来的时空图卷积网络,文中提出了一个新的时空图卷积框架——空间残差层和密集连接块增强的时空图卷积网络(SDGCN)
空间残差层(SRL)
为了更有效地学习时空信息,文中在时空GCN层的输入和输出之间引入了一种二维空间残差结构(绿色块),如下图所示:
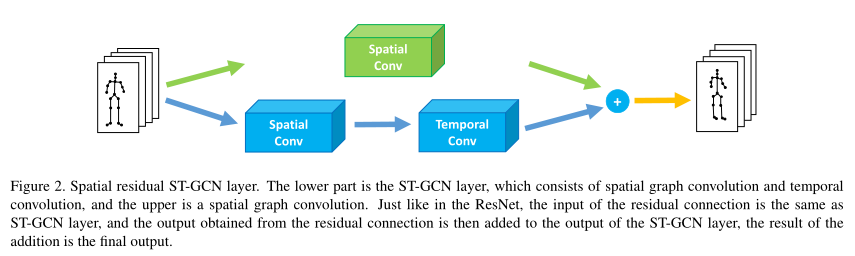
加入空间残差结构的时空图卷积可以计算为:
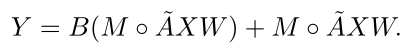
其中:
B表示时间卷积核
X表示输入特征
Y表示时空图卷积的输出特征
密集连接块(DBC)
从DenseNet中受到启发,文中在时空图卷积网络中引入了密集连接,下图为一个密集连接块的示例,每一个SRL层的输入特征都与先前的SRL层的输出特征有关。
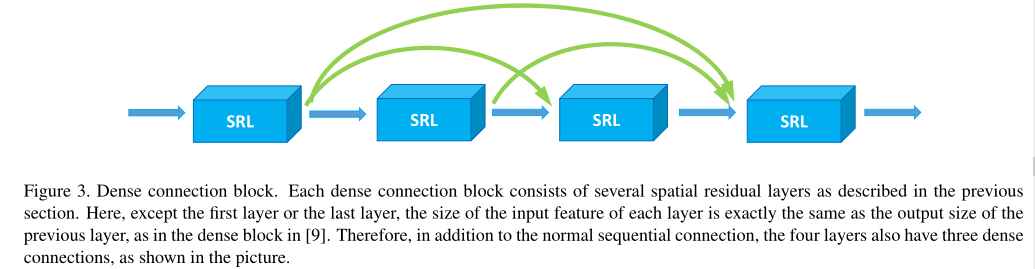
在每个密集连接块中,每一层都已连接到所有后续层,对于第l层,输出特征表示为:
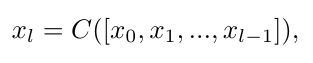
其中:
[x_0,x_1,.,x_{l−1}]是第0,1,.,l−1层的所有输出特征的串联
C是空间残差层(SRL)操作
模型框架
通过将空间残留层和密集连接块结合在一起,可以形成改进的时空图卷积的最终的体系结构,表示为SDGCN。如下图所示,几个空间残差层(图中的圆圈)组成一个密集连接块。
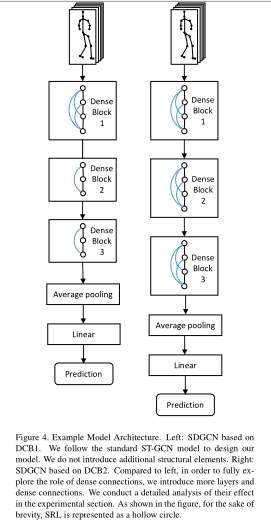
整个网络结构由3个密集连接块组成,并且文中设置了两中不同的框架,右侧框架(DCB2)中每个模块由三个密集连接块组成,每个密集连接包含四个空间残差层。而在左侧框架(DCB1)中,除了第一个连接块与右侧一致之外,之后两个块的层数都减少到了三层。
实验
数据集
1)Kinetics:是从YouTube收集的动作识别数据集,有400个类,并且划分为24万个训练样本和2万个验证样本。该数据集只包含视频数据,需要使用OpenPose工具箱来获取骨架数据,包含每帧图片的18个关节点的二维坐标和置信度分数
2)NTU-RGB+D:是由三台摄像机拍摄的56,800个动作样本,该数据包括,RGB视频、深度图序列、3D骨架和红外视频,3D骨架包括在视频的每帧中标记的25个关节点的空间位置的三维坐标。
实验结果
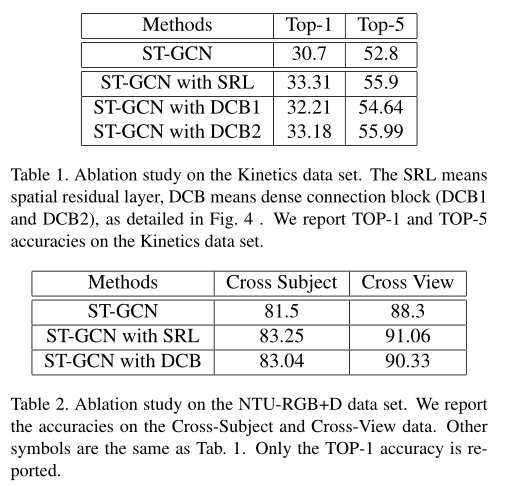
为了探索空间残差层与密集连接的效果,文中使用STGCN作为基准模型,分别在两个数据集上对比了只包含这两个模块的模型的结果,从表1与表2中我们可以得到与原始STGCN相比,空间残差层与密集连接对于动作识别的准确率都有所提升。
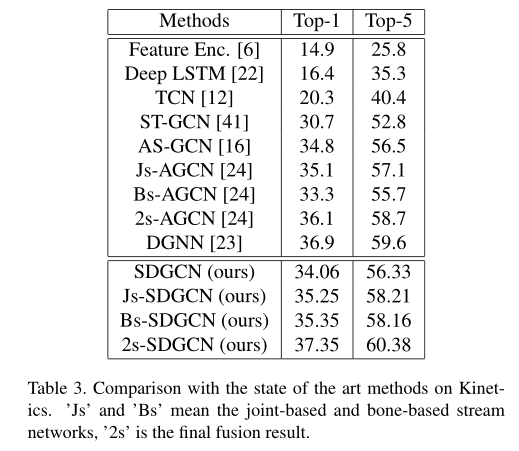
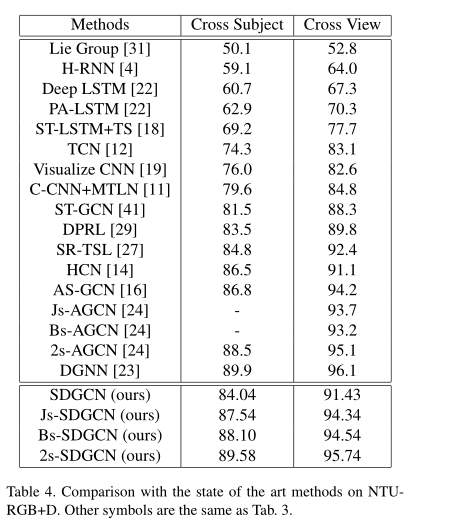
文中也在两个数据集上对比了SDGCN与其它基准模型的效果,如表3与表4所示,可以看到2s-SDGCN的性能优与大部分的基准模型。
结论
为了提高基于骨架的动作识别性能,文中提出了一种统一的时空图卷积网络框架SDGCN。该方法通过引入跨域空间图残差层和密集连接块,充分利用了时空信息。提高了时空信息处理的有效性。它可以很容易地并入主流的时空图网络。



