MMDialog: 微软&北大发布首个百万量级多模态开放域多轮对话数据集


论文链接:
数据集链接:


研究背景

MMDialog数据集
2.1 数据统计

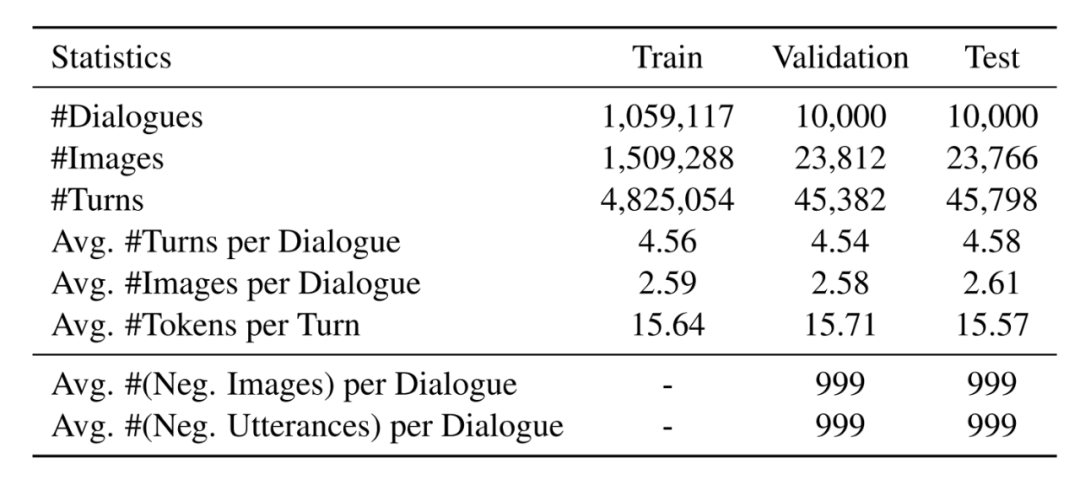
2.2 数据收集
为了保证数据质量,我们决定提取带有某种标签的对话(例如“#travel”、“#friends”、“#golf”),因为标签往往概括了文本话语和视觉媒体的主要主题。具体地,我们人工筛选出 4184 个流行的标签,且保证每个标签至少收集 1000 个对话,这样我们的数据集不仅满足开放域属性,而且可以确保较大的规模。
然后,我们利用以上标签集合作为种子来构建多轮对话。第一步,对于每个标签,我们抓取包含相应标签的 turn,并只保留那些包含至少一个图像的 turn 做为锚点;第二步,我们定位该锚点所在的整段对话;第三步,对于每个锚,我们查找所有其他相关 turn:i)从锚往下搜索直到叶节点,ii)从锚往上搜索直到根节点;iii)由于每个锚点都有可能包括多个回复,所以我们递归地跟踪每个 turn 链以恢复整个对话的树结构。

生成与检索tasks定义
由于目前对话系统的回复预测技术主要包括基于生成和基于检索方法。因此我们在将其调整为多模态场景时,定义了以下两项任务,这对于构建多模态开放域对话系统至关重要:
3.1 生成式多模态开放域对话
3.2 检索式多模态开放域对话
3.3 多模态回复的意图预测任务
3.4 MM-Relevance, 一种新的评价指标
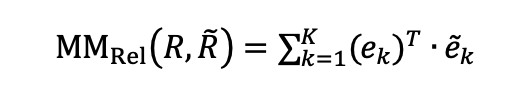
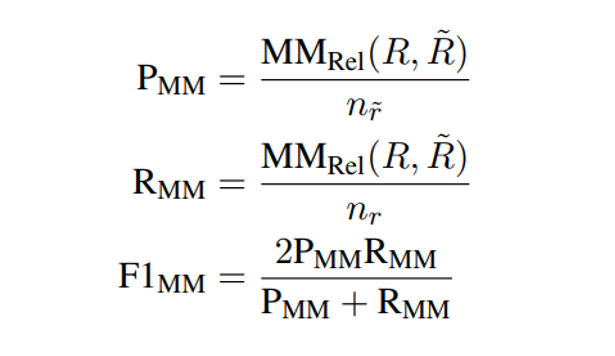

如下图所示,我们提供了两种基线模型来做为上文两种任务的初步解决方案。具体模型定义和实验细节请参考 MMDialog 论文。
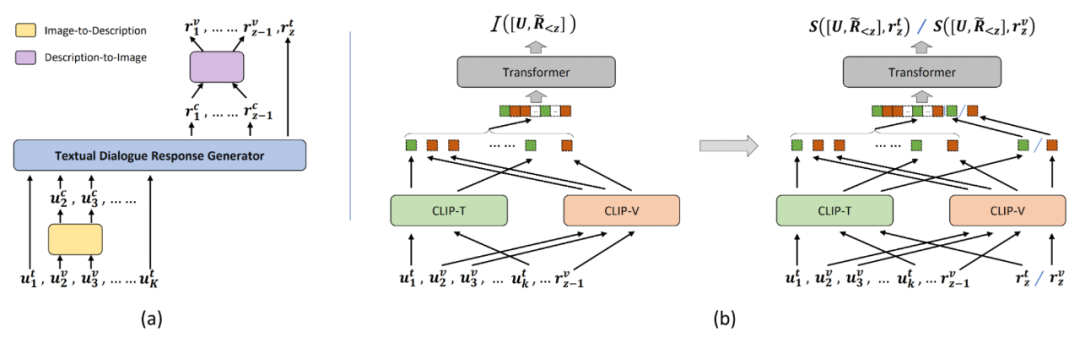
4.1 生成式基线模型
4.2 检索式基线模型
如上图(b)所示的多模态检索模型 DE++,我们复现并改进了 [6] 的图片分享算法,并将其扩展为同时具备判断模态意图与检索文本/图像的能力。


总结与展望
本文发布了首个百万量级的多模态开放域多轮对话英文数据集 MMDialog,并简要总结了多模态对话数据集的发展现状,紧接着我们详细介绍了 MMDialog 的相关信息,并据此提出了多模态开放域对话检索与生成的任务和初步解决方案,且提供了一种新的评价指标。接下来,我们将继续提升多模态开放域对话数据集的质量与规模,以及完善相应算法模型的效果,并希望与感兴趣的研究者们一起探讨交流,推动该领域的进一步发展。

参考文献
[2] Nasrin Mostafazadeh, Chris Brockett, Bill Dolan, Michel Galley, Jianfeng Gao, Georgios Spithourakis, and Lucy Vanderwende. 2017. Image-grounded conversations: Multimodal context for natural question and response generation. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, pages 462–472, Taipei, Taiwan.
[3] Kurt Shuster, Samuel Humeau, Antoine Bordes, and Jason Weston. 2020. Image-chat: Engaging grounded conversations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2414–2429, Online.
[4] Yinhe Zheng, Guanyi Chen, Xin Liu, and Jian Sun. 2022. MMChat: Multi-modal chat dataset on social media. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 5778–5786, Marseille, France.
[5] Shuhe Wang, Yuxian Meng, Xiaoya Li, Xiaofei Sun, Rongbin Ouyang, and Jiwei Li. 2021. Openvidial 2.0: A larger-scale, open-domain dialogue generation dataset with visual contexts. arXiv preprint arXiv:2109.12761.
[6] Xiaoxue Zang, Lijuan Liu, Maria Wang, Yang Song, Hao Zhang, and Jindong Chen. 2021. PhotoChat: A human-human dialogue dataset with photo sharing behavior for joint image-text modeling. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 6142 6152, Online.
[7] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763.
[8] Qingfeng Sun, Yujing Wang, Can Xu, Kai Zheng, Yaming Yang, Huang Hu, Fei Xu, Jessica Zhang, Xiubo Geng, and Daxin Jiang. 2022. Multimodal dialogue response generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2854-2866, Dublin, Ireland.
[9] Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. 2022. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In International Conference on Machine Learning, pages 23318–23340.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」



