![]()
作者:郁博文、戴音培、郎皓、蔡泽枫、高畅、傅浩敏、张业勤、赵英秀、刘澈、惠彬原、林廷恩、马文涛、曹荣禹、余海洋、黄非、李永彬
近日,自然语言处理领域的国际顶级会议EMNLP 2022录用结果出炉,达摩院Conversational AI团队10篇论文被EMNLP 2022录用,围绕着任务型对话、表格型对话、文档型对话、多模态对话、以及对话终身学习和对话表示学习等前沿方向全面开花。本文对这10篇论文的内容进行系统介绍,以此来总结达摩院Conversational AI团队面向对话智能前沿研究的思考和进展。
![]()
任务型对话主要指为满足用户某一目标需求而产生的多轮对话,面向垂直领域,帮助用户完成预定任务或动作, 例如预定机票、查询公积金等。当前任务型对话领域的研究缺乏面向真实人机对话系统的评测数据集,并且大多数研究工作在在封闭世界的假设下开展,在实际应用中并不成立。针对这两个问题,我们从更真实的数据集,和Out-of-Domain检测两个角度展开研究。
A Large-Scale Benchmark for Chinese Goal-oriented Dialog Evaluation
Yinpei Dai, Wanwei He, Bowen Li, Yuchuan Wu, Zheng Cao, Zhongqi An, Jian Sun and Yongbin Li
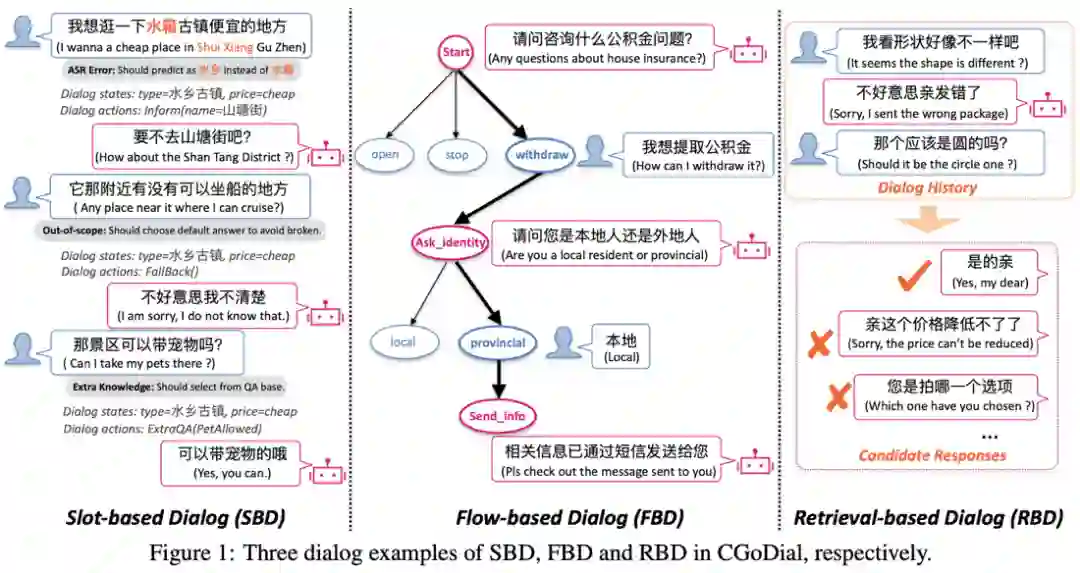
真实的人机对话系统面临着多样化的知识来源(如实体知识、预定义任务流和QA语料库等)和带噪的用户问题(用户语音提问在转话为文本过程中存在噪声)等挑战,然而目前的任务型对话数据集未能全面考虑这些问题。因此我们提出了首个大规模的中文任务型对话评估数据集CGoDial (Chinese Goal-Oriented Dialog)。CGoDial共计包含了96,763个对话,574,949轮次的对话内容,覆盖了以下3种主流的任务型对话类型:
1. 填槽式对话(Slot-based Dialog, SBD)
,即系统一般通过多轮交互获得实体属性并将合适实体告知给用户。我们在已有中文数据集RiSAWOZ的基础上进行改造,引入了基于QA pairs的外部知识、Out-of-scope的用户表述以及口语化噪音来从而得到SBD数据集;
2. 流程式对话(Flow-based Dialog, FBD)
,即系统一般根据一个树形结构的对话流来引导用户完成目标任务。我们构建了首个中文基于Flow的对话数据集,包含住保、交管、政务和高速收费4种场景37个domain,共计6786个对话2.6万轮次;
3. 检索式对话(Retrieval-based Dialog, RBD),
即系统根据用户问题在一个QA语料库中检索出对应回复。我们基于已有的淘宝电商对话数据集E-commerce Dilaog Corpus进行筛选和口语化特征改造,构建了RBD数据集;
![]()
在基线模型上,我们除了基于Chinese-T5,CDial-GPT等中文预训练模型提供了基线效果,还基于UniLM架构和1亿的论坛对话语料预训练了一个预训练对话模型,提供了更具有竞争力的基线。相关的数据集和代码均会在近期开源,以推进中文领域任务对话技术的发展。
Estimating Soft Labels for Out-of-Domain Intent Detection
Hao Lang,Yinhe Zheng,Jian Sun,Fei Huang,Luo Si,Yongbin Li
意图识别(intent detection)是任务型对话系统的重要能力。目前,大多数方法在封闭世界的假设下(closed-world assumption)都取得了较好的效果,即数据是静态的,且只考虑一个固定的意图集合。然而,这样的假设在实际应用中并不成立。我们通常会面对一个开放的世界(open-world),即未经过训练的未知意图可能在测试阶段出现。因此,我们需要赋予对话系统Out-of-Domain(OOD) 检测的能力,使之既可以正确分类出已知In-Domain(ID)的意图,又可以检测出未知OOD意图。OOD检测的一个主要技术挑战是缺点足够的OOD样本。在大多数应用中,在训练阶段从测试分布(test distribution)采样并标注OOD样本都是非常困难的。针对该问题,研究者提出了在训练阶段生成伪OOD样本的各种方法。主流的方法包括:1)Phrase Distortion,即对ID样本中的短语做选择性的扰动和替换;2)Feature mixup,即通过对ID样本的特征做混合生成OOD特征样本;3)Latent generation,即从ID样本的低密度空间(low-density area)采样OOD样本。这些方法的一个共同缺陷是都赋予生成的伪OOD样本one-hot硬标签,即完全属于OOD未知意图类别。然后,对于模型训练最有价值的OOD样本是一些“难”的OOD样本,即与ID样本分布最接近的一些OOD样本。我们注意到“难”OOD样本可能含有已知ID意图。因此,one-hot硬标签的设定会导致伪OOD样本与ID样本有交叉,导致训练效果下降。我们认为伪OOD样本的理想标签应该是软标签(soft labels),即赋予所有的意图类别都是非零概率(non-zero probabilities)。基于平滑假设(smoothness assumption),即空间中相邻的样本拥有相似的标签,我们计算伪OOD样本的软标签。具体地,我们先基于图平滑(graph-based smoothing)算法得到初始软标签,然后基于co-training优化算法进一步优化它们的软标签。实验表明,基于软标签的伪OOD生成算法在三个标准数据集都取得了新SOTA结果。
表格(Table)被广泛应用于存储和展示结构化数据。而表格的语义解析技术(Text-To-SQL)近些年来得到了学术界和工业界的广泛关注,其目的是在多轮交互(对话)中,围绕表格 / 数据库等二维结构化知识,自动地将用户的自然语言问句转换为 SQL 语句,执行后得到目标信息,从而大幅提升与数据库交互的效率和体验。Text-To-SQL模型需要一方面具备对用户提出的自然语言问句的精准理解,另一方面具备在结构化表格中根据需求查找答案的精准推理。然而在实际应用场景中,Text-To-SQL模型会遇到多种多样的用户问句,需要模型具有较强的的泛化能力和鲁棒性。面向这一挑战,我们从模型预训练和模型微调策略两方面展开研究
STAR: SQL Guided Pre-Training for Context-dependent Text-to-SQL Parsing
Zefeng Cai, Xiangyu Li, Binyuan Hui, Min Yang, Bowen Li, Binhua Li, Zheng Cao, Weijie Li, Fei Huang, Luo Si and Yongbin Li
![]()
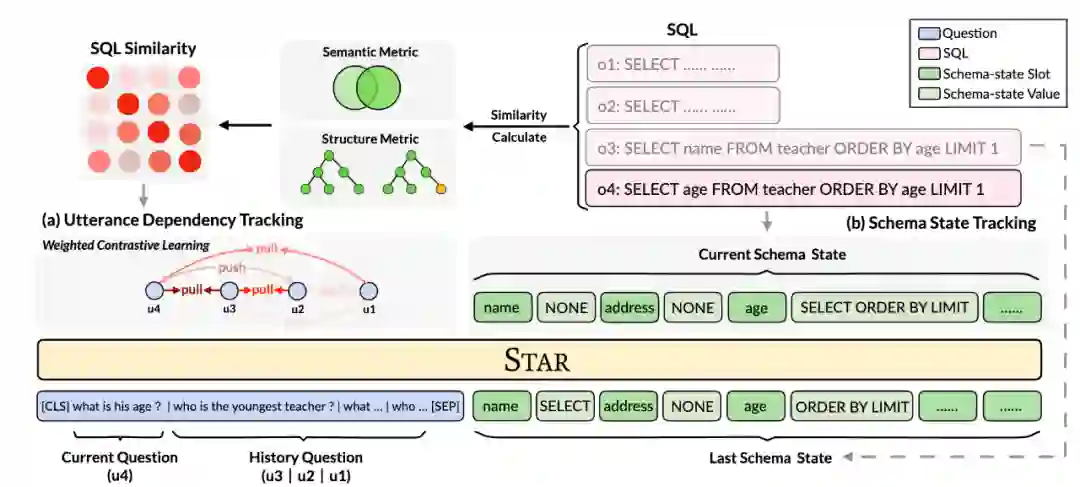
预训练模型最近几年在 NLP 的各种任务上大放异彩,但由于表格和自然语言之间内在的差异性,普通的预训练语言模型 (PLM,e.g. BERT) 在该任务上无法达到最优的性能 ,所以面向对话式语义解析的预训练表格模型(TaLM)应运而生。预训练表格模型(TaLM)需要处理两个核心问题,包括如何利用上下文 query 复杂依赖(指代、意图偏移)及如何有效利用历史生成的 SQL 结果。对此,我们提出了两个预训练目标: (1) 对于上下文 query 利用,提出了基于 SQL 相似度的对比学习任务 UDT (Utterance Dependency Tracking),我们的关键动机在于,类似的 SQL 对应的 query 在语义上更具相关性,因为 SQL 可以看作用户意图的高度结构化表示;(2) 对于上下文 SQL 问题,直接将 SQL 拼接到模型的输入容易引发长度、非语言等性问题,我们借助 SQL 定义 schema 在每一轮的具体状态(扮演什么样的关键词角色),提出了 SST (Schema State Tracking) 任务,最终利用类似状态追踪的想法进行训练。这两个任务都依赖 SQL 的引导,共同完成上下文的复杂建模,所以我们将最终的模型命名为 STAR: SQL Guided Pre-Training for Context-dependent Text-to-SQL Parsing。我们在对话式语义解析的权威 benchmark SParC 和 CoSQL 上进行了评估,在公平的下游模型对比下,STAR 相比之前最好的预训练表格模型 SCoRe,SParC 数据集 QM / IM 提升 4.6 / 3.3%,CoSQL 数据集 IM 显著提升 7.4% / 8.5%,而 CoSQL 相比 SParC 数据集,拥有更多的上下文变化,验证了我们提出的预训练任务的有效性。截至目前,STAR 仍然是两个榜单的 rank 1。
Towards Generalizable and Robust Text-to-SQL Parsing
Chang Gao, Bowen Li, Wenxuan Zhang, Wai Lam, Binhua Li, Fei Huang, Luo Si and Yongbin Li
![]()
除了模型预训练,我们还希望在模型微调阶段增强模型的鲁棒性。为此,我们提出一种让模型学习从简单到复杂的范式,称为TKK框架,它主要包含三个阶段:任务拆解、知识获取和知识组合(Task decomposition & Knowledge acquisition & Knowledge composition),这模仿了人类学习处理Text-To-SQL任务的过程。模型框架如图所示。在任务分解阶段,TKK将原始任务分解为多个子任务。每个子任务对应于将自然语言问题映射到SQL查询的一个或多个子句,这些任务包括SELECT、FROM、WHERE等子任务。之后,TKK采用基于提示词的学习策略,分别获取子任务的知识,并利用所学知识处理主要任务,即生成整个SQL查询。在知识获取阶段,TKK以多任务学习方式训练包含所有子任务的模型;在知识组合阶段,TKK模型在主任务上进行微调,以组合获得的子任务知识并学习它们之间的依赖关系。通过将Text-To-SQL的学习过程拆解成多个阶段,我们的框架提升了模型获取通用SQL知识的能力,而不是仅仅学习简单的模式,从而使得模型具有更强的泛化能力和鲁棒性。为了验证我们提出的TKK模型的泛化能力,我们在公开的三个Text-To-SQL数据集,Spider、SparC和CoSQL上进行实验,均获得了当时的SOTA结果,分别为75.6、66.6和58.3。另一方面,为了验证TKK模型的鲁棒性,我们在增加噪音的Spider-Syn和Spider-Realistic数据集上进行实验,相比于T5-3B模型,TKK模型分别提升2.6(59.4->63.0)和5.3(63.2->68.5)个百分点。总而言之,我们为了提升Text-To-SQL模型的泛化能力和鲁棒性,提出了一种包括任务拆解、知识获取和知识组合的三阶段框架,并且通过实验验证了该框架的有效性。
现代企业与组织在其日常经营活动中会产生大量的文档数据,它们通常都有着巨大的价值。当前,多数企业与组织仍在利用搜索引擎从这些文档中获取信息,这不仅要求用户给出较为精确的检索关键字而且很难处理某些复杂而抽象的信息查询请求。于是,越来越多的研究开始面向文档对话系统(document-grounded dialog system),它期望通过对话的方式来交互式的从文档中获取知识。
Towards Generalized Open Information Extraction
Bowen Yu, Zhenyu Zhang, Jingyang Li, Haiyang Yu, Tingwen Liu, Jian Sun, Yongbin Li, Bin Wang
![]()
开放信息抽取(OpenIE)希望从任意领域的文本中抽取不限定关系类型的三元组类知识,采用原始文本中的片段作为头实体、关系短语和尾实体,这样的开放知识能够在文档问答等知识问答任务中发挥重要价值。然而,当前OpenIE领域的工作往往采用独立同分布的评测方式,即训练集和测试集来源于分布类似的领域,这无疑违背了OpenIE希望从任意领域进行有效抽取的初衷。为此,我们首先人工标注了一个大规模多领域的OpenIE测试集 GLOBE,包含来自保险、教育、医疗等6个领域的两万多个句子,采用和当前最大的人工标注OpenIE数据集SAOKE相同的标注规范。在此基础上,我们构建了一个更贴近真实的OpenIE评测范式:在SAOKE上训练,在GLOBE上测试。先期实验发现,当前的SOTA OpenIE模型在新的评测范式下会出现高达70%的性能损失。进一步分析发现,SOTA模型需要构建包含O(n^2)条连边的图来表示包含n个片段的开放知识,任何一条连边错误都会导致错误的抽取结果,所以在领域变化导致抽取能力下降时不鲁棒。因此我们提出了一个图上最简的OpenIE表达形式:将开放知识表达成为有向无环图,复杂度由O(n^2)降低到了O(n)。实验结果表明,在原始的独立同分布评测范式下,本文提出的方法取得了3.6pt的性能提升。在新的out-of-domain评测范式下,性能提升进一步增加到了6.0pt,并且仅用10%的训练数据就可以获得和之前SOTA模型类似的效果。
Doc2Bot: Accessing Heterogeneous Documents via Conversational Bots
Haomin Fu, Yeqin Zhang, Haiyang Yu, Jian Sun, Fei Huang, Luo Si, Yongbin Li, Cam Tu Nguyen
现有的文档对话数据集主要关注文档中包含的纯文本内容,而忽略了文档中常见的标题,序号和表格等结构信息对于机器理解文档内容的重要性。因此,本文提出了一个中文大规模多领域文档对话数据集Doc2Bot。该数据集包括保险,医疗和科技等五个领域的10余万轮对话和与这些对话相对应的1500余份文档。该数据集不仅标注了每轮对话相应的对话状态和对话动作,还给出了结构化表示的文档数据。因此Doc2Bot数据集能够为对话状态追踪、对话策略学习以及回复生成提供全链路数据支持。针对以上三个任务,本文以常用的大规模预训练模型为基础,在Doc2Bot数据集上开展了若干实验。实验结果表明,对话状态信息和结构信息能够为对话策略学习任务分别带来约 8.5pt 和 10.3pt 的性能提升。同时,对话动作信息则能为回复生成任务带来约 1.3pt 的性能提升。这一结果说明了文档中存在的结构信息与对话状态信息一样,都对文档对话系统有着不容忽视的重要作用。
![]()
上图提供了一个文档对话数据示例。左侧为包含异质结构的文档,右侧为对话内容,其中U和A分别代表用户发言和系统发言。该对话可被自上而下地分为四个分段(以不同颜色标明),每个分段的对话分别对应了左侧 N1-4 的四个文档分段。
人们在日常对话的过程中,不仅依赖文字本身,还需要依赖人类的视觉信息和听觉信息,帮助理解对方的情绪、状态以及真实想要表达的意图,通过同时捕捉语言(文本)与非语言(声学, 视觉)等不同输入模态的特征,使得机器能够做出更准确的预测。
多模态情感分析(MSA)与对话情绪识别(ERC)是多模态对话中的重要课题。然而,现有工作将情感与情绪分开研究,忽略了两者间的相似性和互补性。从心理学的角度来看:(1)情感与情绪有相似的表达形式,例如情感-积极与情绪-高兴;(2)情感与情绪是互补的,情绪是一个人在短期内的感受或感觉的表达,而情感通常是经过长期所形成的。基于上述动机,我们提出了多模态情感知识共享框架 UniMSE,通过生成模型将 MSA 和 ERC 任务从模型架构、输入特征、到输出标签进行了统一。我们在句法和语义层面进行模态融合,并在模态和样本之间引入对比学习,以更好地捕捉情感和情绪之间的一致性和差异性。我们在多模态情感分析 MOSI、MOSEI 和对话情绪识别 MELD、IEMOCAP 等四个多模态数据集上进行实验;结果表明,我们所提出的 UniMSE 方法在四个数据集上皆取得了当前的最佳效果,与最先进方法相比取得了一致性的提升,证明了所提出方法的有效性,也为多模态情感研究开拓了新的研究方向。
前面介绍的对话系统都是在数据分布保持不变的假设下开发的。然而,当实际应用中部署的对话系统需要根据用户需求支持新的功能并提供更多服务时,重新训练整个系统会消耗过多的时间和计算资源。因而,构建具有终身学习能力的对话系统至关重要,即模型能够保留之前学习过的知识的同时不断地获取新知识。当模型序列化地学习具有不同数据分布的多个任务时,会遭受较为严重的灾难性遗忘问题,即模型无法维持旧任务的性能(遗忘了旧任务学到的知识)。面向这一问题,我们从改善生成重放方法,和更充分地利用无标数据两个角度展开研究。
Prompt Conditioned VAE: Enhancing Generative Replay for Lifelong Learning in Task-Oriented Dialogue
Yingxiu Zhao, Yinhe Zheng, Zhiliang Tian, Chang Gao, Bowen Yu, Haiyang Yu, Yongbin Li, Jian Sun and Nevin L. Zhang
生成重放方法是终身学习中解决灾难性遗忘问题的经典方法。在此方法中,模型通过生成旧任务的伪样本来近似旧任务的数据分布,并将生成的伪样本跟新任务的样本混合训练来避免遗忘。然而,大多数现有的生成重放方法仅使用单个任务特定的标记来控制其模型生成。然而由于这种标记中包含的信息不足,该方案通常不足以约束模型来生成质量高的伪样本。为此,我们设计了“基于提示的条件变分自编码器”,结合不同任务的统计信息来增强生成重放。具体来说,模型是用条件变分自动编码器捕获任务特定的分布,以自然语言提示为条件来指导伪样本生成。此外,它利用知识蒸馏来减轻伪样本中的噪声,从而进一步巩固过去的知识。我们在对话系统的自然语言理解任务(意图检测,槽值填充)进行了充分的实验验证,结果表明我们所提出的方法生成了更高质量的伪样本,并有效缓解了灾难性遗忘的问题。
Semi-Supervised Lifelong Language Learning
Yingxiu Zhao, Yinhe Zheng, Bowen Yu, Zhiliang Tian, Dongkyu Lee, Haiyang Yu, Jian Sun, Yongbin Li and Nevin L. Zhang
现有的自然语言领域的终身学习方法只关注于有监督的学习环境,而在现实世界的场景中,有标数据通常是昂贵且耗时的,无标数据却数量众多,容易收集,并携带着丰富的语义信息。在本文中,我们探索了一种新的设定,即半监督终身语言学习,其中每个顺序到达的语言任务都带有少量的标记数据和大量的无标数据。我们提出了一种无标数据增强的终身学习者来探索此设定。具体来说,我们为每个任务分配特定的参数来避免模型学习新任务时对旧任务所学过的参数造成干扰,从而缓解灾难性遗忘的问题。除此之外,该设定下存在两个挑战:(1)如何充分利用无标数据来提升每个到来的语言任务?(2) 如何利用无标数据来鼓励知识迁移到以前学习过的任务?我们设计了两个模块来应对:(1)我们在老师-学生框架上构建了用虚拟监督信号来增强的任务求解器,以挖掘每个任务无标数据中的潜在知识;(2) 我们建立了后向增强的学习器以鼓励知识从新到达任务的无标数据迁移到之前学习过的任务中。在此半监督持续学习的设定下,我们开展了的两种维度的实验(任务属于同一类别但是不同领域和不同类别的多个任务),实验结果和详尽的分析充分证明了我们的模型有效性和优越性。
在实际上线的对话系统中,不仅需要各类的对话服务,还需要以对话为中心的辅助功能,比如面向海量无标注对话的检索、聚类等,而这样的功能实现离不开对话语义理解。
dial2vec: Self-Guided Contrastive Learning of Unsupervised Dialogue Embeddings
Che Liu, Rui Wang, Junfeng Jiang, Yongbin Li and Fei Huang
![]()
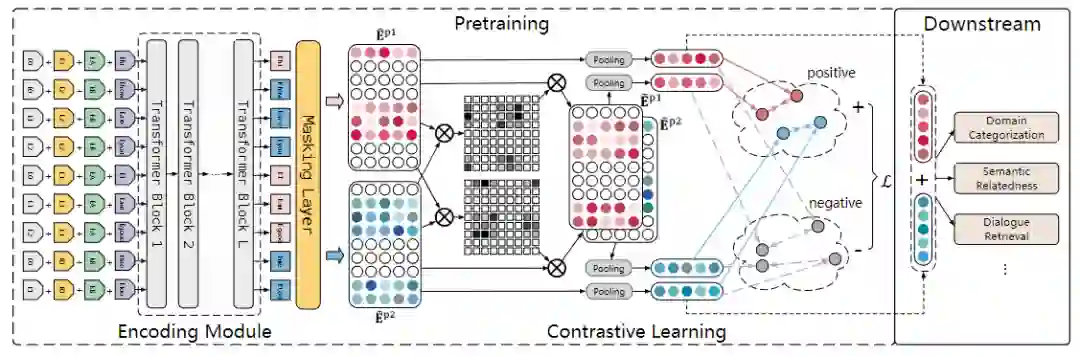
对话嵌入(dialogue embedding)任务的目标是将一段完整的对话映射为一个高维度的语义向量,对于对话级的语义理解至关重要,但相关研究甚少。我们首次提出无监督对话嵌入任务。首先收集了包括BiTod、Doc2dial、MetalWOZ、MultiWoz、SGD、Self-dialogue在内的6个具有代表性的对话数据集,并利用它们数据集本身所提供的对话标签(如类别标签)来为每个数据集分别构建了聚类、对话检索、对话语义相似性排序三个评估任务。紧接着,我们评测了多种可以应用于无监督对话嵌入的方法,如非深度学习方法(LDA)、向量池化方法(GloVe、Doc2Vec、SimCSE、DialogueCSE)、预训练语言模型(BERT、RoBERTa、T5)和对话式预训练语言模型(TOD-BERT、PLATO、BLENDER)。结果表明,由于这些方法或多或少忽略了发言者级别之间的语义交互,因此导致它们提供的对话向量的表现不够理想。因此,我们进一步提出dial2vec模型,来充分挖掘对话中蕴含的发言者级别的语义交互信息。dial2vec将一通对话视为一次发言者之间的信息交互过程,通过捕获发言者之间的语义交互模式,dial2vec以自我引导式的方式分别优化每个发言者的语义表示,最终将所有发言者的语义信息聚合后得到整通对话的嵌入表示。作为一种dialogue embedding的框架,dial2vec可以以任何预训练语言模型或对话式预训练语言模型作为底座来实现,且均能够取得显著的效果提升。在我们的实验中,我们发现使用PLATO作为底座能够取得最好的表现。这种设置下,dial2vec在聚类、对话检索、对话语义相似性三个任务的purity、Spearman's correlation、MAP指标上分别取得相比最强基线9.4pp、10.6pp和16.1pp的提升。进一步实验证明,在会话交互信息的指导下,dial2vec为每个发言者都学习到了信息丰富和具有区分度的对话语义表示。我们也研究了多发言者之间的语义融合策略,并提出了发言者级池化(interlocutor-level pooling)策略。这种策略能够进一步平衡各发言者的语义信息比例,并使得多发言者语义信息融合时取得超过直接进行平均池化的效果。
总的来说,在数据资源方面,Conversational AI团队在这次EMNLP会议中贡献了首个大规模的中文任务型对话评估数据集、首个多领域开放信息抽取泛化性评估数据集、首个带有文档结构信息的文档型对话数据集;在模型设计方面,Conversational AI团队重点关注对话模型的鲁棒性和持续学习能力,希望增强线上业务模型的效果,并在任务型对话、表格型对话、文档型对话等任务中展开了探索;此外,Conversational AI团队还积极探索了智能对话中的新任务,如多模态情感分析与对话情绪识别,和自监督对话表示学习,扩展了智能对话的研究领域。达摩院Conversational AI团队负责人李永彬表示,一方面研究要有长期主义精神,该团队从2014年开始做人机对话的研究和落地,已经在这个方向上深耕了8年多时间;另一方面研究要从业务中来再到业务中去,作为创始算法团队,打造了目前国内智能客服市场份额第一的阿里云智能客服。面向未来,团队将继续致力于打造有智商、有情商、可持续、多模态的类人对话系统,实现文本、音频、图像、视频多模态的全场景对话,并能在业务落地中持续进化。
后台回复 “达摩院智能对话” 可获得pdf版文章哦~
招聘信息:
阿里巴巴达摩院对话智能团队 (Conversational AI) 成立于2014年,专注于人机对话前沿研究和大规模应用。研究方面,围绕预训练对话模型、任务型对话、TableQA、KBQA、文档问答、多模态对话等方向发表多篇ACL/EMNLP/AAAI/SIGIR/KDD等顶会论文。研究方向(包括但不限于):1、面向对话的大规模预训练模型研究;2、新一代任务型对话系统研究;3、基于Table的多轮对话技术研究;4、基于文档的多轮对话技术研究;5、多模态对话系统研究。
岗位要求:1、自然语言处理、机器学习、人工智能、图像处理等相关专业的博士/硕士,可现场全职实习6个月及以上;2、具有较强的编程能力,熟练使用 Python/Java/C/C++之一;3、有 ACL、EMNLP、NAACL、AAAI、IJCAI 等相关顶会论文者优先;硕士生须有一篇一作顶会论文;
简历投递:ting-en.lte@alibaba-inc.com、yubowen.ybw@alibaba-inc.com
邮件及简历命名格式:
阿里达摩院-姓名-研究型实习生
工作岗位:研究型实习生 (Research Intern)
工作地点:北京-望京