百万量级的多模态对话数据集来了,153万张图片4000多主题,已对学术圈开源|北大&微软新研究
羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
百万量级的多模态对话数据集来了!
MMDialog,这个由北大&微软最新发布的英文数据集,包含了108万个来源于真实世界的高质量对话。
其中包括非重复图片153万张,涉及4184个主题,还支持多种表情符号。
就像人在网上聊天时除了文字,还会发表情包、图片一样,多模态数据集正是旨在促进AI像人类一样交谈。
举个例子,下图是MMDialog收录的一段人类对话,可以看到,双方正在用文字、图片和表情符号谈论风景和野生动物。

目前,该数据集已对学术研究领域开源,可访问文末链接获取使用权限~
MMDialog优势在哪?
虽然目前开源的英文大规模图文数据集较为丰富,如Visual Dialog、Image-Chat、OpenViDial、PhotoChat等,但它们或多或少都存在一定的局限性。
比如Visual Dialog仅为针对特定图片内容的提问与解答,场景与任务的定义比较单一;
Image-Chat是从给定图像的对话中派生出来的,这种会话中讨论的主题通常只由给定图像触发和支撑,回复的内容也只有文本信息,这与人类日常对话的发散性并不完全一致;
PhotoChat则是由众包标注,尽管已比较接近于现实生活中的多模态对话,但仍然受到数据规模较小的限制。
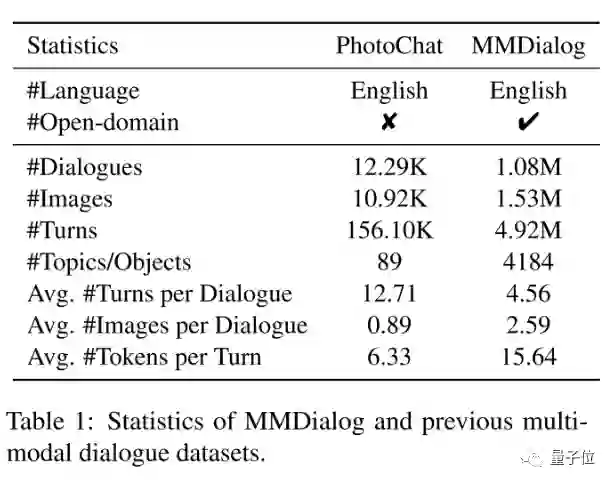
以下图为例,与PhotoChat相比,MMDialog拥有88倍的对话数量,47倍的主题丰富度,以及140倍的图片数量。
而且,每段对话平均包含2.59张图像,且可以位于对话过程的任何位置,更符合人类的交流习惯。
其次,MMDialog的另一大优势在于其包含了大量的话题,以推广开放域。
为了保证数据质量,研究人员选择在某英文在线社交平台提取带有某种标签的对话(例如“#travel”、“#friends”、“#golf”),因为标签往往概括了文本话语和视觉媒体的主要主题。
具体来说,他们人工筛选出4184个流行的标签,且保证每个标签至少收集1000个对话,这样MMDialog数据集不仅满足开放域属性,还可以确保较大的规模。
两种基线模型
为了用MMDialog数据集建立更真实的对话系统,本文还提出并规范了两个基于检索和生成场景的响应式生成任务。
此外,研究人员还为上述任务建立了两个基线:生成式基线模型、检索式基线模型,并报告了其实验性能。

生成式基线模型
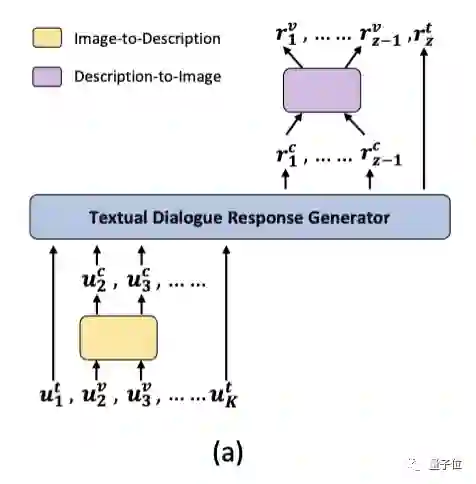
如下图所示,研究人员复现并改进了多模态回复生成的SOTA模型-Divter ,它包括两个主要部分:一个纯文本对话回复生成器G,以及一个文本描述-图像翻译器F。
具体来说,在输入端,G将对话历史U做为输入,然后生成一个文本序列,该序列可能包括:文本回复、图片的文本描述,或同时包括两者。
然后,图片翻译器F会将图片的文本描述翻译为图片回复 ,并将所有的文本回复与图片回复依次组合起来做为最后的多模态回复。
值得注意的是,在G的输入端,我们还需要一个图像-文本描述翻译模型 ,来将所有对话历史中的图像转化为对应的文本描述。
检索式基线模型
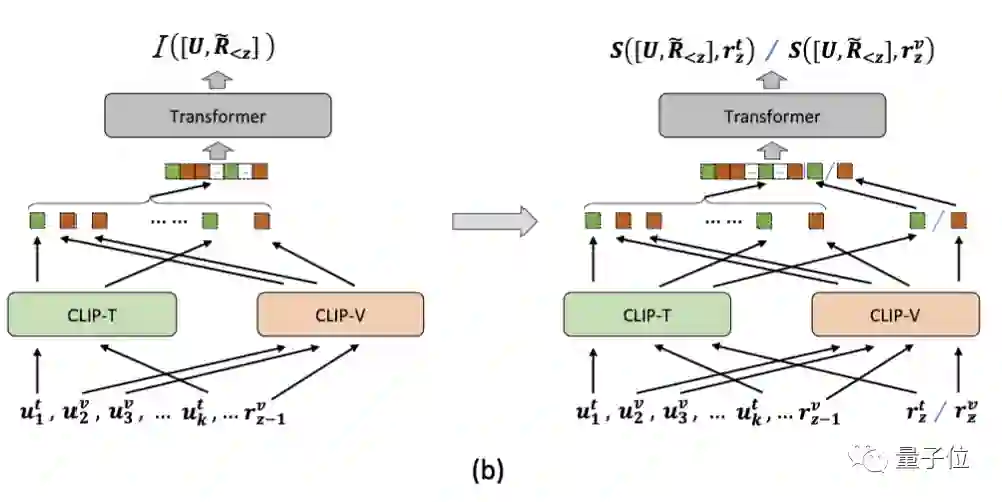
下图展示的是多模态检索模型DE++,研究人员复现并改进了PhotoChat的图片分享算法,并将其扩展为同时具备判断模态意图与检索文本/图像的能力。
简单来说,该模型包括一个回复模态意图预测模块和一个回复排序模块,它们具有相似的模型结构,并利用CLIP分别编码对话历史U以及回复候选集C中的文本和图像。
在模态意图预测模块做出下一个元素的模态预测后,排序模块会从C中选择与其相关性最高的作为多模态回复的组成部分,直到模态意图预测模块判定已被完整检索回为止。
研究团队
本篇论文的研究团队来自北大和微软。

其中一作冯家展,是北京大学智能学院的博士生,在MSRA实习期间完成本次研究。
论文和GitHub链接附在文末,如果你是硕士生/博士生/博士后/教职员工/研究型员工等,可以点击申请访问权限~
GitHub链接:
https://github.com/victorsungo/MMDialog
论文链接:
https://arxiv.org/abs/2211.05719
参考链接:
https://mp.weixin.qq.com/s/SArX84T1CDW6p2jWGxPc8A
— 完 —
MEET 2023 大会定档!
首批嘉宾阵容公布
量子位「MEET2023智能未来大会」正式定档12月14日!
首批嘉宾包括郑纬民院士、MSRA刘铁岩、阿里贾扬清、百度段润尧、高通Ziad Asghar、小冰李笛、浪潮刘军以及中关村科金张杰等来自产学研界大咖嘉宾,更多重磅嘉宾陆续确认中。
点击“预约”按钮,一键直达大会直播现场!
点这里关注我 👇 记得标星噢 ~




