大规模跨领域中文任务导向多轮对话数据集及模型CrossWOZ

本文包含以下内容
2020年刚出的大规模中文多轮对话数据集的介绍
多轮对话的一些常见任务
多轮对话的一些常见模型
基本概念
什么是对话?
我:你好!
机器人:你也好!
多轮对话呢?
我:你好!
机器人:你也好!
我:吃饭了伐?
机器人:当然没有
(来回好几回合)
任务导向多轮对话呢?
我:帮我订一张机票!
机器人:哪里呢?
我:北京的。
机器人:订好了。
(不是闲聊,有目的性的对话)
跨领域任务导向多轮对话呢?
我:帮我订一张机票!
机器人:哪里呢?
我:北京的。
机器人:订好了。
我:再在附近订个五星酒店。
机器人:北京饭店你看可以吗?
(用户有两个以上目的(订机票和酒店)要通过对话实现)
中文?突出中文是因为之前的大规模开源多轮对话数据集MultiWOZ是英文的。MultiWOZ在推动英文多轮对话诞生了很多研究。因此这次清华大学计算机系制作了中文的数据集以填补中文任务导向对话数据的空白。

论文地址:https://arxiv.org/pdf/2002.11893.pdf
数据集介绍
数据集参数
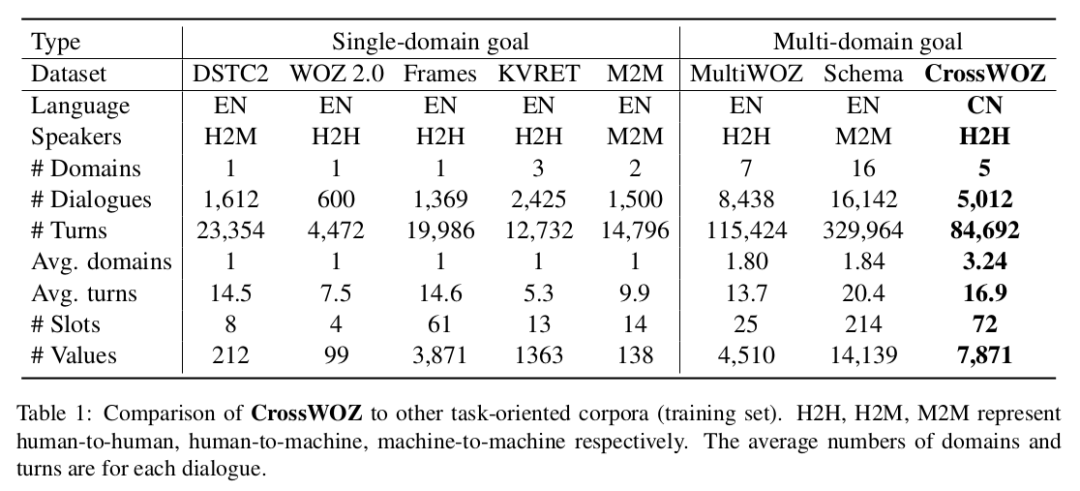
CrossWOZ包含 6K 个对话,102K 个句子,涉及 5 个领域(景点、酒店、餐馆、地铁、出租)。平均每个对话涉及 3.2 个领域,远超之前的多领域对话数据集,增添了对话管理的难度。
特点
用户在某个领域的选择可能会影响到与之相关的领域的选择,在跨领域上下文理解更有挑战。
第一个大规模中文跨领域任务导向数据集。
在用户端和系统端都有详细的对话状态记录,标注信息全面。
与其他数据集的对比
跨领域对话的数据样例

数据标注方法
基础数据库的构建。通过爬虫从网络上获取了北京市的酒店/旅游景点/饭店以及地铁和出租车信息。
比如说Attract景点有465个,景点有9个槽。Hotel和8+37个槽。比如是否要叫醒服务等。
目标构建。论文通过算法自动生成标注人员的对话目标。
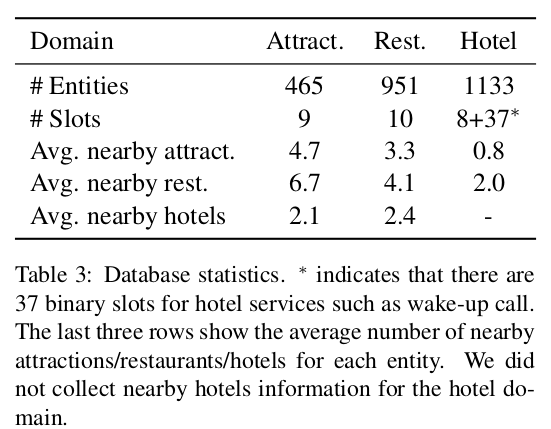 比如说Attract景点有465个,景点有9个槽。Hotel和8+37个槽。比如是否要叫醒服务等。
比如说Attract景点有465个,景点有9个槽。Hotel和8+37个槽。比如是否要叫醒服务等。 
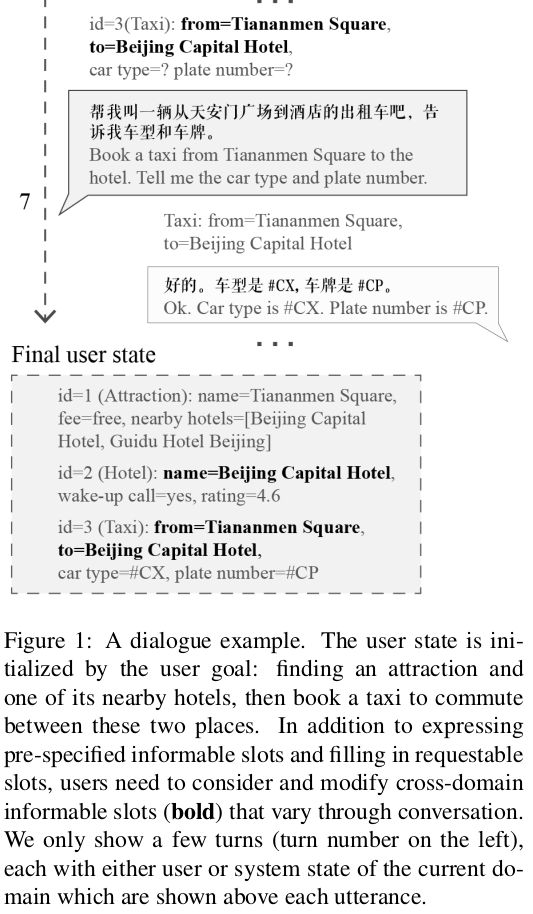
上面的id1,2,3就是自动生成的目标。标注人员要以完成这三个目标(寻找免费旅游景点和订附近酒店以及出租车)作为目的和系统进行对话。
3. 数据标注。论文雇佣大量工人分别充当用户和系统。用户向系统订酒店景点,然后系统回复用户预约的相关信息。所有的对话数据都是用户生成的。同时用户在对话过程中还需要对用户状态和系统状态进行标注。具体的过程如下图。

数据和模型下载地址:https://github.com/thu-coai/CrossWOZ
常见任务
有了多轮对话数据集,而且标注这么详细,我们就有研究多轮对话的条件了。
多轮对话有以下五个研究方向:
多轮对话下的自然语言理解(Natural Language Understanding)
对话状态追踪(Dialogue State Tracking)
对话策略学习(Dialogue Policy Learning)
自然语言生成(Natural Language Generation)
用户模拟器(User Simulator)
多轮对话下的自然语言理解(NLU)
多轮对话下的NLU通常是对用户的输入语句让模型填满这样一个四元组
(intent=Inform, domain=Attraction, slot=fee, value=free)
通过意图识别和ner我们就可以完成nlu。本文提出了一种BERTNLU-context的模型来做多轮对话下的nlu。BERTNLU不必多说,就是把bert作为encoder对输入文本进行编码。然后为了利用上下文信息,BERTNLU-context会把对话历史的之前三句话用sep分割作为文本输入另一个BERT模型,取出那个模型的cls位置变量作为上下文表征。然后把该上下文表征和用户输入的语句的特征向量一一concat再进行ner和文本分类,效果很好。
对话状态追踪(DST)
DST的目地是根据用户和系统的对话历史,动态识别出用户的目地,并转为预先定义好的格式。
本文介绍了两种方法做DST
RuleDST。设计一些规则动态识别用户状态,比如识别到用户说任意一个槽就给它填上。
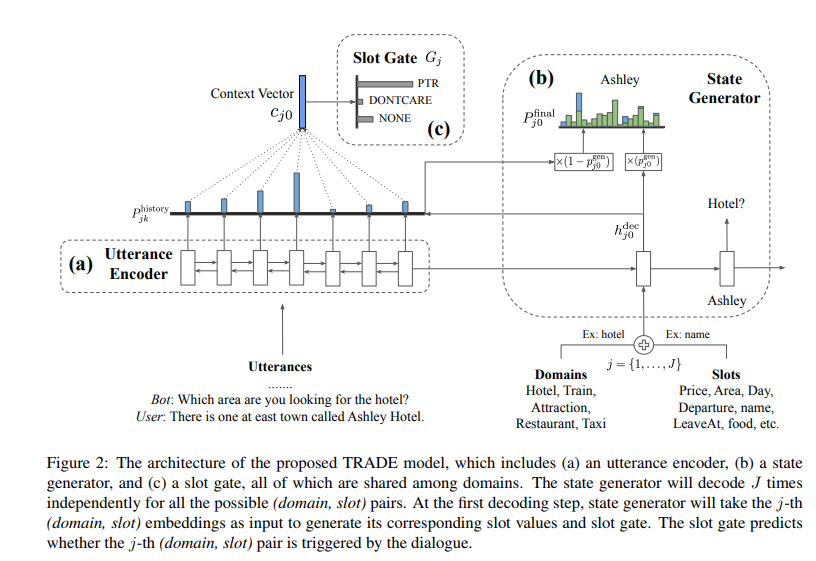
TRADE。TRADE模型需要专门的篇幅来介绍它。
对话策略学习(DPL)
DPL就是根据之前的对话状态和用户输入,生成一个系统action。在我们做传统的基于状态机的多轮对话中,对话策略通常是基于规则的。本论文介绍了ConvLab-2对话平台下使用SL polciy完成了监督学习下的对话策略学习模型。
自然语言生成(NLG)
我们有了用户和系统的状态和对话动作,同时又有用户生成的自然语言。那么便可以制作生成模型来生成灵活的系统回复语言。本文用两种方式做这个,一个是基于模板的TemplateNLG,一个是SC-LSTM。两个效果如下:
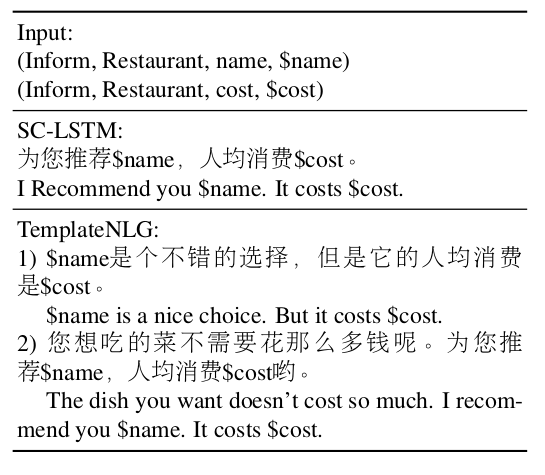
SC-LSTM模型参考地址:https://github.com/andy194673/nlg-sclstm-multiwoz
用户模拟器
用户模拟器是用来模拟用户说话的。最简单的模拟器就是规则型的比如约定第一句话说订酒店,第二句话说要五星的。
用户模拟器对多轮对话系统的自动化评估和对话策略学习都是很有帮助的。本文也构建了一种rule-based 用户模拟器。比如当用户的目标中有未填充的槽时,用户模拟器就会不断追问该槽值,直到所有目标的槽全部填充为止。
论文结果
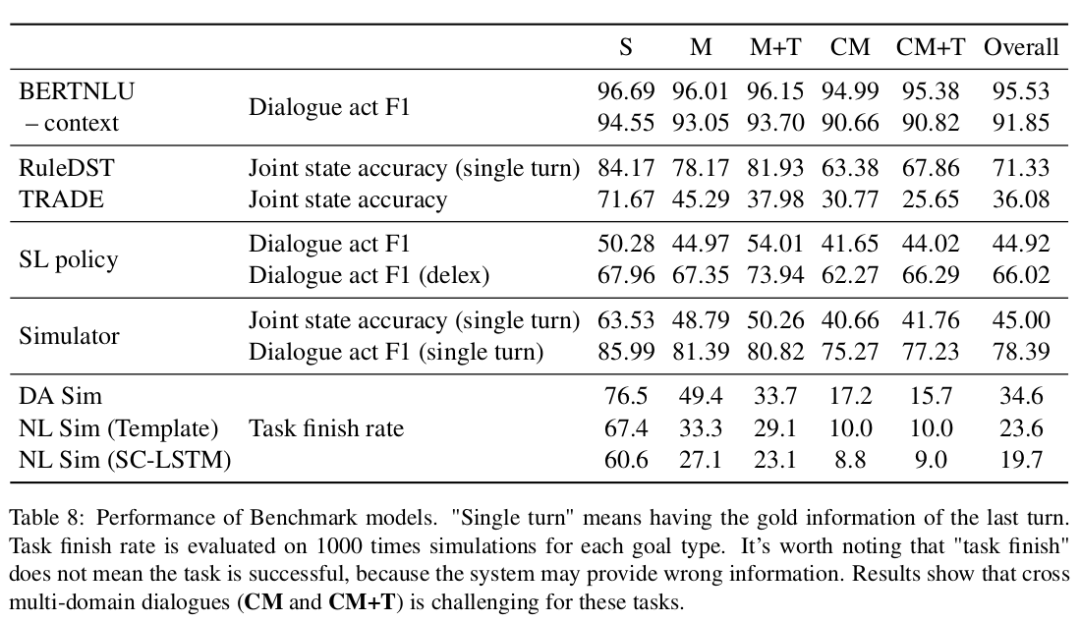
1 BERTNLU部分准确率都很高。
2 DST/SL policy准确率在80以下,具有很大提高空间。
3 越是跨领域,对话状态越难追踪。
推荐阅读
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




