手把手解释实现频谱图卷积
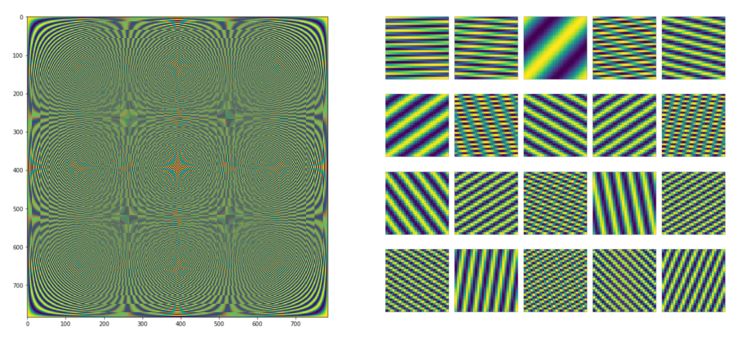
图1:左边的傅里叶基(DFT矩阵),其中每列或每行是基向量,重新整合成28×28(如右边所示),即右边显示20个基向量。傅里叶基利用计算频谱卷积进行信号处理。如图所示,本文采用的正是拉普拉斯基方法。
先来回顾一下什么是图。图G是由有向或无向边连接的一组节点(顶点)组成的。在这篇文章中,我将假设一个带有N个节点的无向图G。图中的每个节点都有一个C维特征向量,所有节点的特征表示为N×C维矩阵X⁽ˡ⁾。图的一侧表示为N×N矩阵A,当在其中输入Aᵢⱼ,表示节点I是否与节点j相连时,该矩阵称为相邻矩阵。
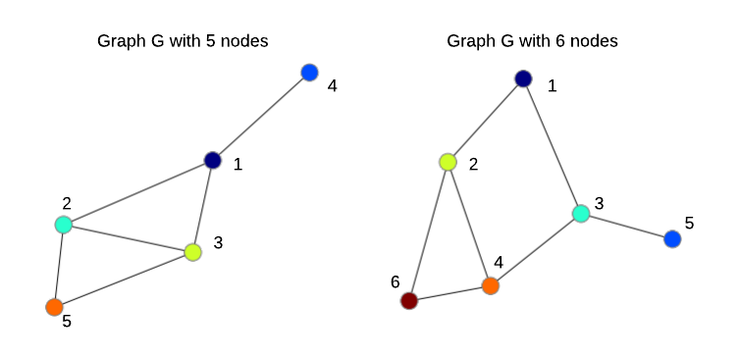
图2:在N=5和N=6节点的无向图中节点的顺序是任意的。
对于图的频谱分析对于图聚类、社区发现和无监督学习任务等方面都是有用的。在这篇文章中,我主要描述了Bruna等人在2014年,ICLR 2014的工作中,他们将频谱分析和卷积神经网络(ConvNets)相结合,产生了频谱图卷积网络,可以有监督的方式进行训练,用于图的分类任务中。
尽管与空间图卷积方法相比,频谱图卷积目前还不太常用,但了解频谱图卷积的工作原理仍有助于避免产生和其他方法同样的问题。 另外,在结论中我提到了我最近在做的一些工作,能使频谱图卷积更具优势。
1. 拉普拉斯基以及一些物理学原理
虽然“频谱”听起来可能很复杂,但我们只需要知道它是将信号/音频/图像/图分解成简单元素(微波、图)的组合就够了。为了在分解过后得到一些好的性质,这些简单元素通常是正交的,就是与相互线性无关,因此就形成了一个基。
当我们讨论信号或者图像处理中的“频谱”时,指的是傅里叶变换,它为我们提供了不同频率的正弦波和余弦波的特定基 (DFT矩阵,例如Python中的scip.linalg.dft),这样我们就可以将信号或是图像表示为这些波的总和。但是当我们讨论图和神经网络图(GNN)时,“频谱”意味着拉普拉斯图L的特征分解,你可以认为拉普拉斯图L是一种特殊的相邻矩阵A,而特征分解就是为了找到构成我们的图基本正交分量的一种方法。
拉普拉斯图直观地显示了当我们在节点I中放置一些“潜在元素”时,“能量”在图上的传播方向和扩散程度。在数学和物理学中,拉普拉斯基的一个典型应用是解决信号(波)如何在动态系统中传播。如果相邻的值没有突然的变化,那扩散就是很平滑的,如下面的动图所示。
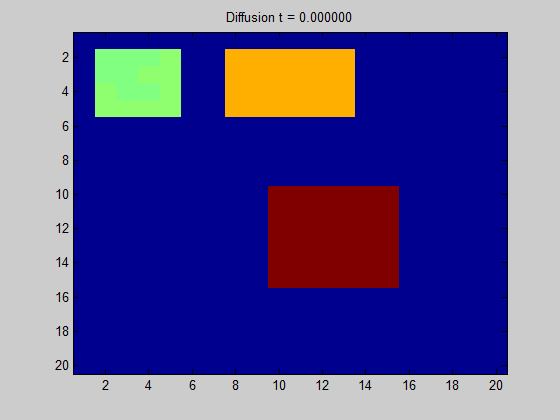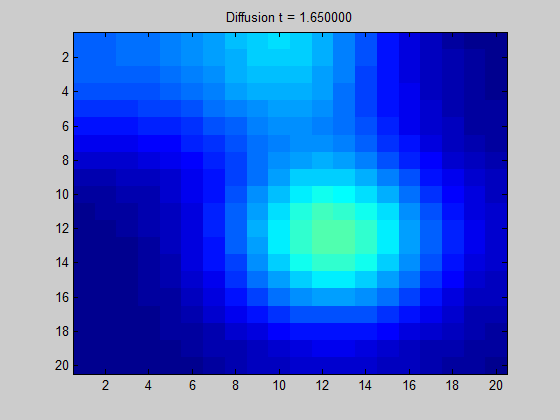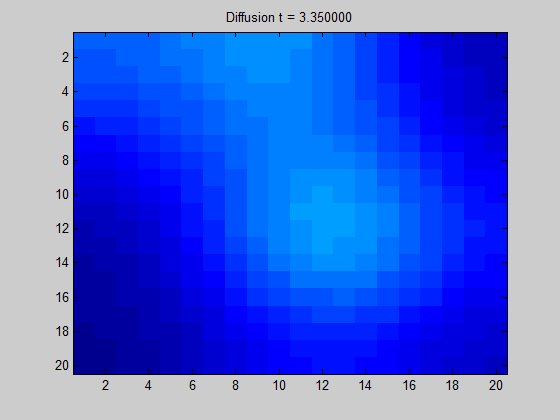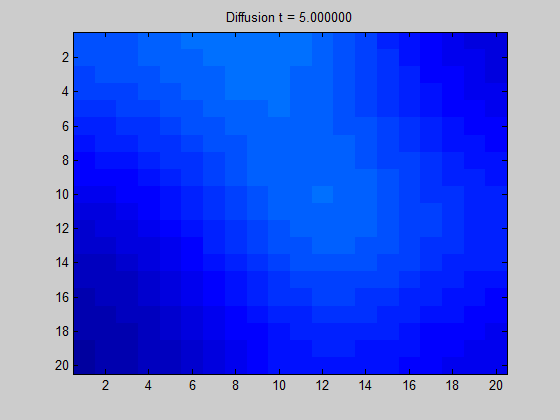
图3:基于拉普拉斯图的规则,网格图中某些信号的扩散。基本上,计算这些动力需要节点(像素)中的拉普拉斯算子和初始值,即与高强度(热)对应的红色和黄色像素相对应。
在后面的文章中,我将假设“对称归一化拉普拉斯算子”,它经常用于图神经网络中,因为它是规范化的,所以当你叠加许多层图时,节点特征会以一种更平滑的方式传播,不会造成数据爆炸,特征值或梯度也不会消失。原因是它是基于图的相邻矩阵A进行计算的,可以在几行Python代码中完成,如下所示:

图4
我们假设A是对称的,即A=Aᵀ,并且我们的图应该是无向的,否则节点都不能明确的定义,在计算拉普拉斯算子时必须做一些假设。相邻矩阵A的一个性质是ⁿ(矩阵乘积取n次)暴露了节点之间的n-hop连接。
我们生成了三个图,接下来可以观察它们的相邻矩阵,拉普拉斯算子以及它们的功率。
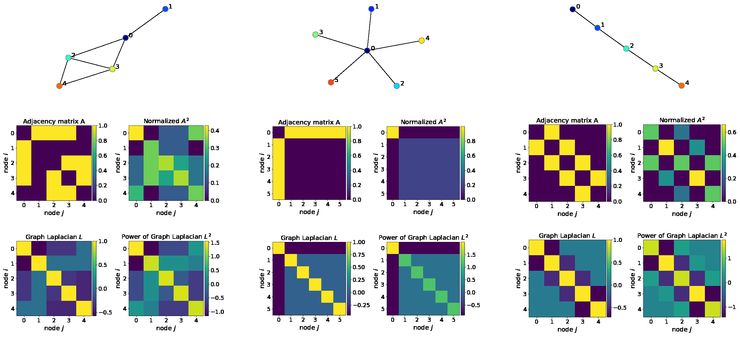
图5:相邻矩阵,拉普拉斯算子及随机功率图(左),“星状图”(中间)和“路径图”(右)。我将A 2规范化,使得每行之和等于1,从而得到了一个关于2-hop连接的概率解释。注意,拉普拉斯算子及其功率是对称矩阵,这使得特征分解更容易,并且便于在深度图网络中进行特征传播。
例如,假设中间的星状图是由金属制成的,这样它就能很好地传递热量。然后,如果我们开始加热节点0(深蓝色),热量将以拉普拉斯算子定义的方式传播到其他节点。在所有的边都相等这种星状图的特殊情况下,热量会均匀地扩散到所有其他节点,但由于结构不同,并不适用于其他图。
在计算机视觉和机器学习的背景下,拉普拉斯图定义了如果我们叠加多个图神经层,该如何更新节点特征。类似于我的教程的第一部分,为了从计算机视觉的角度理解频谱图卷积,我将使用MNIST数据集,它在28×28的规则网格图上定义图像。
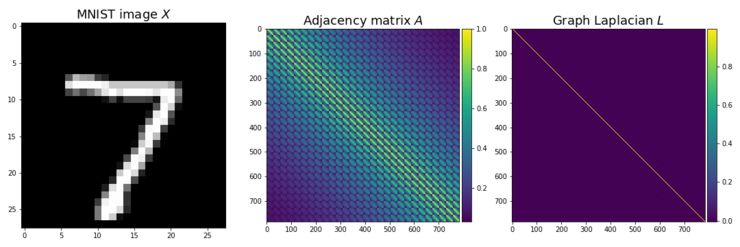
图6:MNIST图像定义了28×28的规则网格特征X(左)、相邻矩阵A(中间)和拉普拉斯算子(右)。拉普拉斯图看起来像一个单位矩阵的原因是该图有相当多的节点(784),因此在归一化之后,对角线外的值比1小得多。
2. 卷积
在信号处理中,可以看出空间域中的卷积是频域的乘积。(也称为卷积定理)同样的定理也适用于图。在信号处理中,为了将信号转换到频域,我们使用离散傅里叶变换,它基本上是信号与特殊矩阵(基,DFT矩阵)的矩阵乘法。由于是在这样的基础上假设了一个规则的网格,
所以我们不能用它来处理不规则图,这是一个典型的例子。相反,我们使用了一个更通用的基,即拉普拉斯图L的特征向量V,它可以通过特征分解得到:l=VΛVᵀ,其中Λ是L的特征值。
PCA与拉普拉斯图的特征分解。在实际计算频谱图卷积时,只需使用与最小特征值相对应的几个特征向量。乍一看,它似乎与计算机视觉主成分分析(PCA)中常用的策略相反,在PCA中,我们更擅长处理最大特征值对应的特征向量。然而,这种差异仅仅是因为计算上述拉普拉斯算子采用了反证法,因此用PCA计算的特征值与拉普拉斯图的特征值成反比(正式分析见本文)。还请注意,PCA应用于数据集的协方差矩阵,目的是提取最大的异常因子,也就是数据变化最大的维度,比如特征面。这种变化是由特征值来测量的,因此最小的特征值实际上对应于噪声或“假”特征,这些特征在应用中被认为是无用的,甚至是有害的。
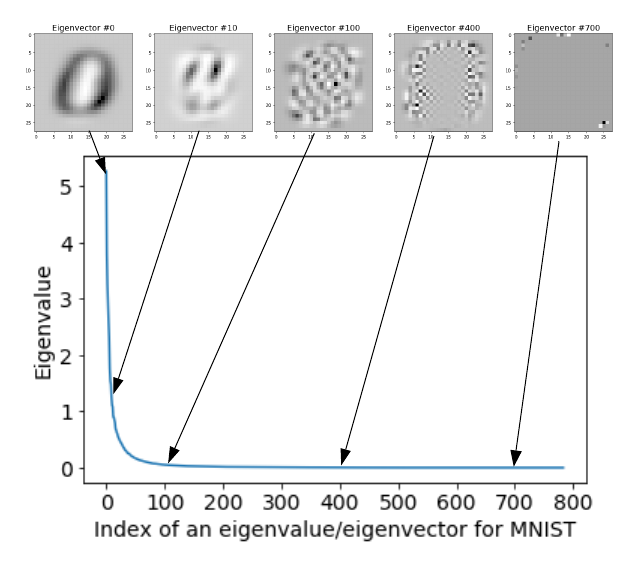
图7:MNIST数据集的特征值(降序)和对应的特征向量。
将拉普拉斯图的特征分解应用于单图,提取节点的子图或集群(群落),特征值告诉我们许多关于图连通性的信息。在下面的例子中,我将使用对应20个最小特征值的特征向量,假设20比节点N的数量小得多(在MNIST情况下,N=784)。为了求左下的特征值和特征向量,我使用了一个28×28的正则图,而在右边我按照Bruna等人的实验,在28×28的规则网格上的400个随机位置上采样构造不规则图(详见他们的论文)。
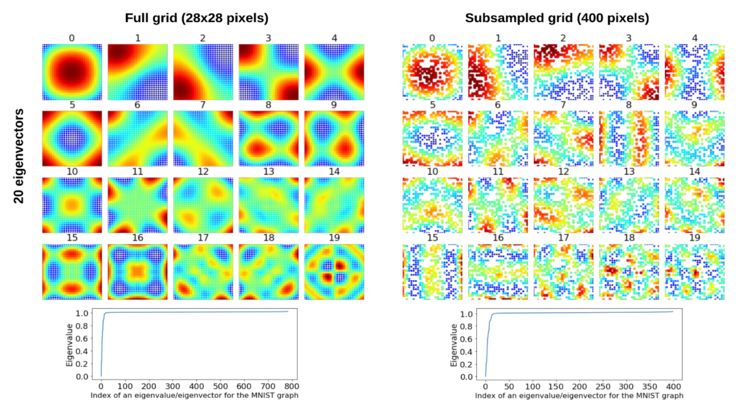
图8:拉普拉斯图 L的特征值Λ(底部)和特征向量V(顶部)。根据Bruna等人2014年在ICLR 2014(右)的实验,对一个规则的28×28网格(左)和400个点进行随机采样。给出了对应于20个最小特征值的特征向量。特征向量在左侧为784维,右侧为400维,V分别为784×20和400×20。在左侧的20个特征向量中,每个特征向量被重新更改为28×28,而在右侧,将400维特征向量更改为28×28,为缺失的节点添加白色像素。因此,每个特征向量中的每个像素对应于一个节点或一个缺失节点(右侧为白色)。这些特征向量可以看作是我们分解图形的基础。
因此,给定拉普拉斯图L,节点特征X和滤波器W频谱,在Python频谱卷积图上看起来非常简单:

图9
公式:
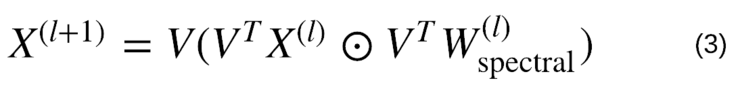
图10:频谱图卷积,其中⊙表示按元素方向乘积
假设我们的节点特征X⁽ˡ⁾是1维的,例如MNIST像素,但是它可以扩展到C维:我们只需要对每个维度重复这个卷积,然后在信号或图像卷积中对C求和。
公式(3)实质上与使用傅里叶变换在规则网格上对信号进行频谱卷积基本相同,因此给机器学习带来了一些问题:
可训练权重(滤波器)W频谱的维数取决于图中节点N的数量。
W频谱也取决于以特征向量V编码的图形结构。
这些问题让我们很难把这个方法用在具有可变结构的大规模图数据集中。下文总结的重点在于解决这些问题和其他可能出现的问题。
3. 频谱域中的“平滑”扩散

图11:频谱域中的平滑扩散会有点不同
Bruna等人是最早通过应用频谱图分析学习卷积滤波器从而解决图分类问题的研究者之一。使用上述公式(3)学习的滤波器作用于整个图,也就是说它们具有了整体的技术支持。在计算机视觉环境中,这与在MNIST上训练的28×28像素的卷积滤波器是一样的,即滤波器的大小与输入数值相同(请注意,我们滤波器仍然会滑动,只是表现在零填充的图像上)。对于MNIST来说,我们实际上可以训练这样的滤波器,但人们普遍认为应该避免这一点,这样会加大训练的难度,主要是因为参数的潜在数据爆炸以及训练大型滤波器带来的困难。虽然这些滤波器确实具有可以捕获不同图像之间相同有用特征的能力。
实际上,我使用PyTorch和我的GitHub的代码成功地训练了这样一个模型。你应该使用mnist_fc.py-模型conv运行它。经过100次的训练后,滤波器看起来更像是数字的混合体:
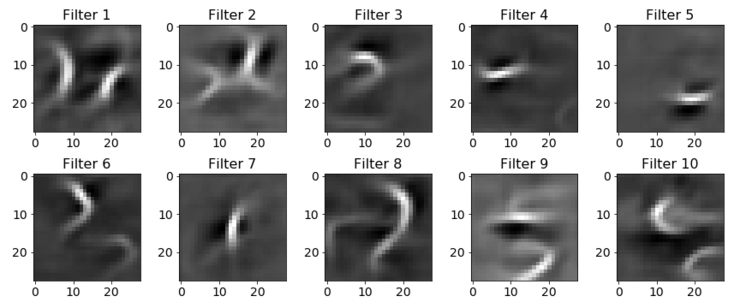
图12:具有技术支持的滤波器通常是用于频谱卷积。在这种情况下,这些是使用带有单个卷积层的ConvNet学习的28×28滤波器,其后是ReLU,7×7 MaxPooling和完全连接的分类层。 为清楚起见,由于零填充,卷积层的输出仍为28×28。 令人惊讶的是,该网络在MNIST上达到了96.7%。 这可以通过数据集的简单性来解释。
重申一下,我们通常希望滤波器更小、更局部化(这与我下面要指出的情况不完全相同)。
为了实现这一点,他们提出在频谱域中滑动滤波器,从而使它们在空间域上更符合频谱理论。我们的想法是,你可以将公式(3)中的滤波器W频谱表示为?预定义函数(如样条)的总和,而不是学习W的N值,我们要学习这个和的K系数α:
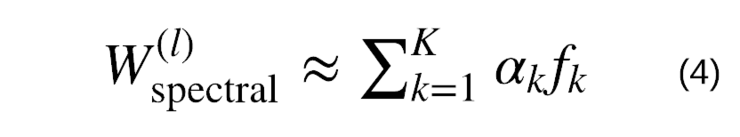
虽然fk的维数取决于节点N的个数,但这些函数是固定的,因此我们不必学习它们。我们需要学到的唯一东西是系数α,所以W频谱不再依赖于N,对吗?

图14:样条基用于在频域中滑动滤波器,从而使滤波器更加局部化。样条函数和其他多项式函数都是有用的,因为我们可以将滤波器表示为它们的和。
为了使公式(4)更加合理,我们希望K<N能将可训练参数的数目从N减少到K,更重要的是它能从N中分离出来,以便我们的GNN能够消化任意大小的图。我们可以使用不同的基来执行这种“扩展”,这取决于我们需要的属性。例如,上面所示的三次样条函数被称为平滑函数(也就是说,你不能看到节点,就是分段样条多项式各个部分相交的位置)。我在另一篇文章中讨论的Chebyshev多项式,在近似函数之间具有有最小的?∞距离。傅里叶基是变换后保留大部分信号能量的基。大多数基是正交的,因为具有可以彼此表达的项是多余的。
AI科技评论提示,滤波器W频谱仍然和输入的数值一样大,但是它们的有效宽度很小。对于MNIST图像,我们将使用28×28滤波器,其中只有一小部分值的绝对值大于0,这些数值是无限接近的,即滤波器是在局部有效的,实际上很小,如下所示(左第二):
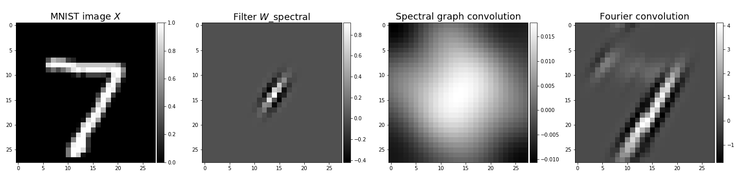
图15:从左到右:(1)输入图像。(2)有效宽度小的局部滤波器,多数数值值无限接近于0。(3)数字7的MNIST图像与滤波器的频谱图卷积结果。(4)利用傅里叶变换进行频谱卷积的结果。这些结果表明,频谱图卷积对图像的应用是非常有限的,这可能是由于拉普拉斯基相对于傅里叶基的空间结构较弱所致。

图16:仅用V:X‘=V VᵀX的M分量对MNIST图像进行傅里叶和拉普拉斯图的重建。我们可以看到,基压缩了图像中不同的模式(傅里叶情况下的定向边缘和拉普拉斯情况下的全局模式)。这使得上述卷积的结果不同。
总之,在频谱域中进行平滑处理使Bruna等人了解了更多的局部滤波器信息。这种滤波器的模型可以获得与模型相似的结果,无需平滑化,但可训练参数却少得多,因为滤波器的大小与输入图的大小无关,这对于将模型缩放到大型图的数据集是很重要的。然而,学习的滤波器W频谱仍然依赖于特征向量V,这使得将该模型应用于可变图结构的数据集具有很大的挑战性。
总结:
尽管原始频谱图卷积方法存在诸多不足,但由于频谱滤波器能够更好地捕捉图中全局的复杂模式,因此在某些应用中依然非常具有竞争力,而GCN(Kipf&Wling,ICLR,2017)等局部方法不能在深层网络中叠加。例如,Liao等人发表的两篇ICLR 2019论文。 “LanczosNet”和Xu等人在“微波神经网络图”的基础上,解决了频谱图卷积存在的一些不足,在预测分子性质和节点分类方面取得了很好的效果。Levie等人2018年在“CayleyNets”上的另一项研究发现,它在节点分类、矩阵完成(推荐系统)和社区检测方面表现出了很强的性能。因此,根据你的应用程序和基础设施,频谱图卷积可能是一个不错的选择。
在我的关于计算机视觉及其他图神经网络教程的另一部分(文章链接:https://towardsdatascience.com/tutorial-on-graph-neural-networks-for-computer-vision-and-beyond-part-2-be6d71d70f49)中,我解释了由Defferrard等人在2016年提出的Chebyshev频谱图卷积,它直到现在还是一个非常强大的基线,它有一些很好的特性,而且很容易实现,正如我用PyTorch演示的那样。
原文链接:https://towardsdatascience.com/spectral-graph-convolution-explained-and-implemented-step-by-step-2e495b57f801
更多内容
「LSTM之父」 Jürgen Schmidhuber访谈:畅想人类和 AI 共处的世界 | WAIC 2019
历年 AAAI 最佳论文(since 1996)
一份完全解读:是什么使神经网络变成图神经网络?
点击 阅读原文 查看 用 Excel 来阐释什么是多层卷积

