如何优化你的图像分类模型效果?

本文为 AI 研习社编译的技术博客,原标题 :
Boost your Image Classification Model
作者 | Aditya Mishra
翻译 | MichaelChen 编辑 | 邓普斯•杰弗、咩咩咩鱼
原文链接:
https://towardsdatascience.com/boost-your-image-classifier-e1cc7a56b59c
注:本文的相关链接请访问文末【阅读原文】
图像分类是一个认为几乎解决了的问题。有趣的是,你必须竭尽所能来提升额外的1%的准确率。当我参加“ Intel Scene Classification Challenge hosted by Analytics Vidhya(由Analytics Vidhya主办的英特尔场景分类挑战)”我非常喜欢这次比赛,因为我尝试从我的深度学习模型中榨干所有的潜力。下面的技术通常是可以应用到手头上的任何图像分类问题中去。
问题
下面的问题是把给定的图片分类到下面的6个类别中去。

数据类别
数据中包含25,000张自然风景的图片,这些图片来自世界各地。
渐进的(图片)尺寸调整
当训练CNN模型的时候,从小到大的线性调整图片尺寸是一项技术。渐进的尺寸调整在很赞的fastai课程中被描述为:程序员的深度学习实践。一种不错的方式是先用小的尺寸,如64 x 64进行训练,再用这个模型的参数,在128 x 128尺寸上进行训练,如此以往。每个较大的模型都在其体系结构中包含以前较小的模型层和权重。

渐进的尺寸调整
FastAI

fastai库是一个强大的深度学习库。如果fastai团队找到了一篇很感兴趣的论文,他们会在不同的数据集上进行测试,并实现调参。一旦成功,就会被合并到他们的库,并且对它的用户开放阅读。这个库包含了很多内置的先进的技巧。基于pytorch,fastai对于大多数任务都有很好的默认参数。部分技巧包括:
周期性学习率
一个周期的学习
结构化数据的深度学习
完整的权重初始化
在查看可用的标准数据集时,我偶然发现了Place365数据集。Place365数据集包含365种风景分类的1,800,000张图片。本次挑战赛提供的数据集与这个数据集很相似,所以在这个数据集训练的模型,具有一些学习的特征,与我们分类的问题是相关的。由于我们的问题中的类别是Place365数据集的子集,所以我使用了一个用Place365权重初始化的ResNet50模型。
这个模型的权重在“pytorch weights”中提供。下面使用的实用函数帮助我们正确地将数据加载到fastai的CNN学习器中。
混合增强
混合增强是一种通过对已有的两幅图像进行加权线性插值,来形成新图像的增强方法。我们取两张图像,然后使用这些图像的张量进行线性组合。

混合增强
λ是服从beta分布的随机采样。虽然论文的作者建议使用 λ=0.4,但是fastai的库默认值设为0.1。

fastai中的混合增强
学习率调优
学习率是训练神经网络中最重要的超参数之一。fastai有一种方法来找出合适的初始学习速率。这个技术被称作循环学习率,我们用较低的学习率进行试验,并以指数形式增加,记录整个过程的损失。然后我们根据学习率绘制损失曲线,并选择损失值最陡峭处的学习率。
fastai中的LR Ffinder
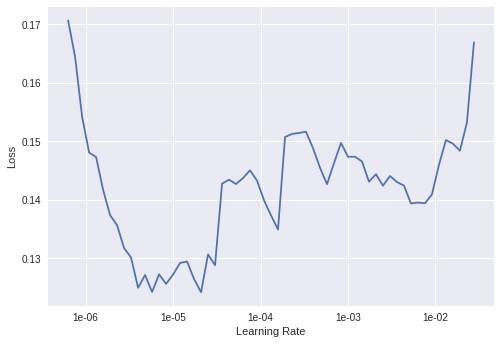
在学习率为1e-06时,损失最陡峭
这个库还为我们自动的处理带有重新启动的随机梯度下降(SGDR)。在SGDR中,学习率在每次迭代开始时会重新设置为原始选择的数值,这些数值会随着迭代减小,就像余弦退火一样。这么做的主要收益是,由于学习率在每次迭代的开始可以重置,因此学习器能够跳出局部极小值或鞍点。

fastai中带有重启的随机梯度下降
通用对抗网络
生成式对抗网络(GAN是Generative Adversarial Networks的缩写)在2014年被Ian Goodfellow提出,GANs是由两个网络组成的深层神经网络结构,它们相互竞争。 GANs可以模拟任何数据分布。他们可以学习生成类似原始数据的数据,而且可以是任何领域——图像、语音、文本等等。我们使用fastai的Wasserstein GAN的实现来生成更多的训练数据。
GANs包括训练两个神经网络,一个被称为生成器,它生成新的数据实例,另一个被称为判别器,它对它们进行真实性评估,它决定每个数据实例是否属于实际的训练数据集。你可以从这个链接查阅更多。
https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson7-wgan.ipynb

GAN生成样本图片
去除混淆的图像
训练神经网络的第一步不是写任何的神经网络的代码,而是彻底观察你的数据。这一步至关重要。我喜欢花费大量的时间(以小时为单位)浏览数千张样例,理解他们的分布,寻找他们的模式。——Andrej Karpathy
正如Andrej Karpathy所说,“数据调查”是一个重要的一步。关于数据调查,我发现很多数据包含不少于两种的类别。
方法-1
使用之前训练的模型,我对整个训练数据进行了预测。然后丢弃概率得分超过0.9但是预测错误的图像。下面这些图像,是模型明显错误分类的。深入观察以后,我发现这些图像是被人工错误分类了。

混淆的图像
有些图像的预测概率在0.5到0.6之间,理论上可能是这个图像表现出不止一个类别,所以模型给他们分配了相同的概率,我也把这些图像剔除了。观察这些图像,这个理论最终被证明是正确的。
方法 2
fast.ai提供了一个方便的插件“图像清理器插件”,它允许你为自己的模型清理和准备数据。图像清理器可以清洗不属于你数据集的图像。它在一行中呈现图像,使你有机会在文件系统中删除文件。
测试时间增加
测试时间的增加包括提供原始图像的一系列不同的版本,并把他们传递到模型中。从不同的版本中计算出平均值,并给出图像的最终输出。

fast.ai中测试时间的增加
之前提出的10-crop技巧跟此技巧类似。我首先在残差网络的论文中读到了10-crop技巧。10-crop技巧包括沿着四角和中心点各裁剪一次,得到五张图像。反向重复以上操作,得到另外五张图像,一共十张。测试时间增加的方法无论如何比10-crop技巧要快。
集成
机器学习中的集成是一种使用多种学习算法的技术,这种技术可以获得比单一算法更好的预测性能。集成学习最好在下面的条件下工作:
组成模型具有不同的性质。比如,集成ResNet50和InceptionNet要比组合ResNet50和InceptionNet有用的多,因为它们本质上是不同的。
组成模型的相关性较低。
改变模型的训练集,能得到更多的变化。
在本例中,我通过选择最大发生类来集成所有模型的预测。如果有多个类有最大出现的可能,我随机选择其中的一个类。
结果:
公开排行榜——29名(0.962)
私人排行榜——22名(0.9499)
结论
渐进的尺寸调整在开始时是一个好主意。
花时间去理解你的数据并且可视化是必须的。
像fastai这种具有出色的初始化参数的出色的深度学习库,确实有帮助。
只要有可能,就要尽量使用迁移学习,因为确实有用。最近,深度学习和迁移学习已经应用到了结构化数据,所以迁移学习绝对应该是首先要尝试的事情。
最先进的技术例如混合增强,测试时间增加,周期学习率将毫无疑问的帮助你将准确率提高1到2个百分点。
始终搜索与你的问题相关的数据集,并且把他们尽可能的用在你的训练数据集中。如果可能,深度学习模型在这些模型上训练之后,使用他们的参数作为你模型的初始权重。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1724











