论文推荐|[CVPR 2020]: 基于深度关系推理图网络的任意形状文本检测(有源码)

图像文本检测一种常用的思路就是,首先找出文字/文本的基本区域或部件,然后分析这些部件之间的相互关系,再利用知识规则或学习策略来连接这些部件,最后构造出所需要的文字/文本区域,完成文本检测与提取。这就是文本检测传统方法中基于文字/文本连通域分析的经典技术[1,2,3],也是文本检测深度学习方法中基于文字/文本组件连接的流行技术[4,5,6]。本CVPR 2020(Oral)论文(”Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection”)就是一种新的基于组件连接的文本检测技术[7],构建了深度关系推理图网络,有效地学习与推理文字/文本组件之间的连接及语义关系,高精度地检测复杂场景图像中的任意形状文本。
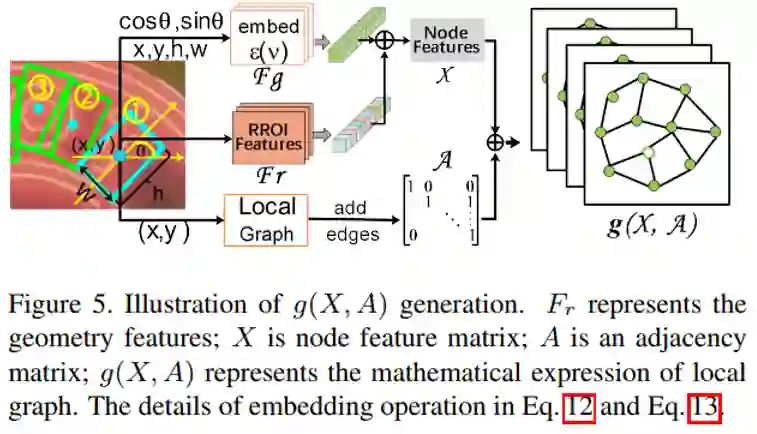
这篇CVPR 2020论文(”Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection”)提出了一种基于文字/文本组件连接的检测任意形状的方法,利用图卷积神经网络来进行组件之间的深度关系推理,有效地解决了复杂情况下文本组件的连接问题(如图1所示)。该方法将每个文本实例表示成许多个矩形的文本组件,然后把每个文本组件视为一个节点,通过该论文提出的局部子图(Local Graph)将同一张图中的文本组件节点划分成多个子图,每个子图包含一个中心节点和其二阶以内的邻居节点,最后通过一个图卷积神经网络模型进行学习和推理中心节点与其邻居节点的关系。同时,在局部子图的桥接下,文本组件预测模型(CNN)和关系推理模型(GCN)组合成了一个端到端可训练的任意形状文本检测系统。实验证明,该方法在多个场景文本检测数据集上达到了State-of-the-art的效果。
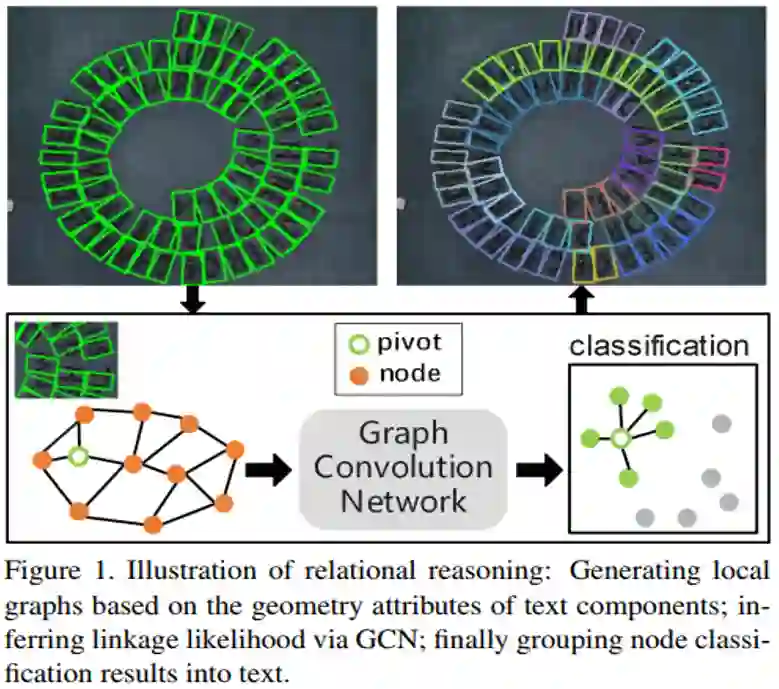
场景文本检测已广泛应用于各种应用程序中,例如在线教育、产品搜索、即时翻译和视频场景理解。随着深度学习的繁荣,业内很多文本检测算法在文本实例具有规则形状或长宽比受控的环境中取得了令人印象深刻的性能。但是,由于文本表示形式的局限性,这些方法往往无法检测复杂场景图像中具有任意形状的文本。当前,任意形状文本检测已经成为了文本检测一个研究热点。但是,由于场景文本的多样性和复杂性,任意形状文本检测仍然是一项具有挑战性的任务。
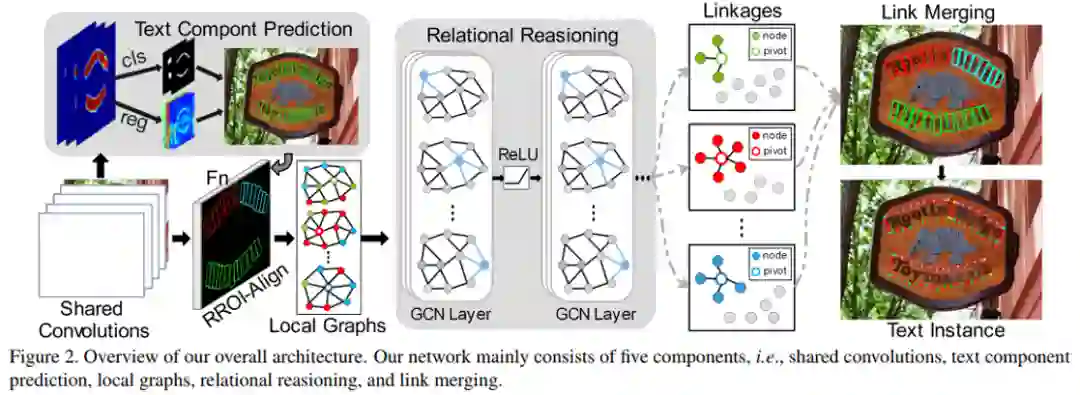
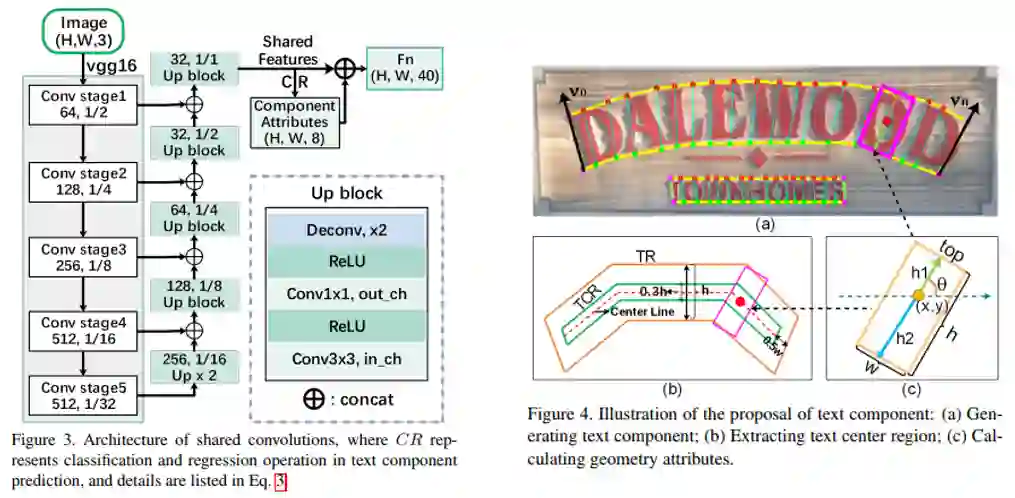
具体方法细节如图2所示,本文方法主要包含五个部分:共享卷积层(Shared Convolutions)、文本组件预测网络(Text Component Prediction)、局部子图(Local Graphs)、关系推理模型(Relational Reasoning)和组件的归并过程(Link Merging)。文本组件预测网络和深度关系推理网络共享卷积特征;共享卷积使用VGG-16加FPN结构作为主干网络(如图3所示)。文本组件预测网络使用共享的卷积,预测获取文本组件的几何属性(中心位置、宽、高和旋转角)。获得几何属性后,局部子图可以粗略地建立不同文本组件之间的关系,并将文本组件划分成多个局部子图。基于局部子图,关系推理网络将进一步推断中心节点与其邻居节点之间连接的可能性。最后,根据关系推理网络获得的推理结果将文本组件归并聚合为整体文本实例。
对于文本组件预测网络(如图4所示),每个文本组件需要获得其几何属性,包括中心坐标、宽、高和旋转角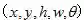
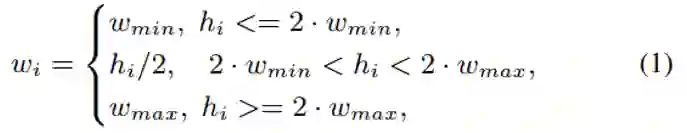
局部子图的建立依据空间相似度寻找中心节点的二阶邻阶(公式(10));为了避免局部子图的重复计算和减少计算量,局部子图的生成还需要满足公式(11)。
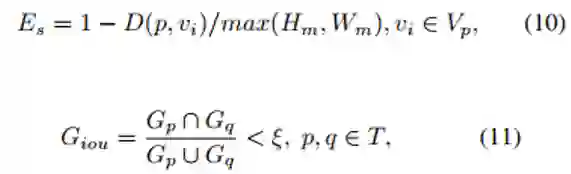
对于关系推理网络,我们采用了一个四层的图卷积神网络,具体结构如公式(15)和(16)所示,
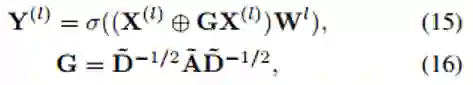
本文的方法采用完全端到端的训练方式,网络的损失函数包含三个部分,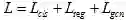
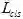
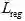
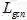
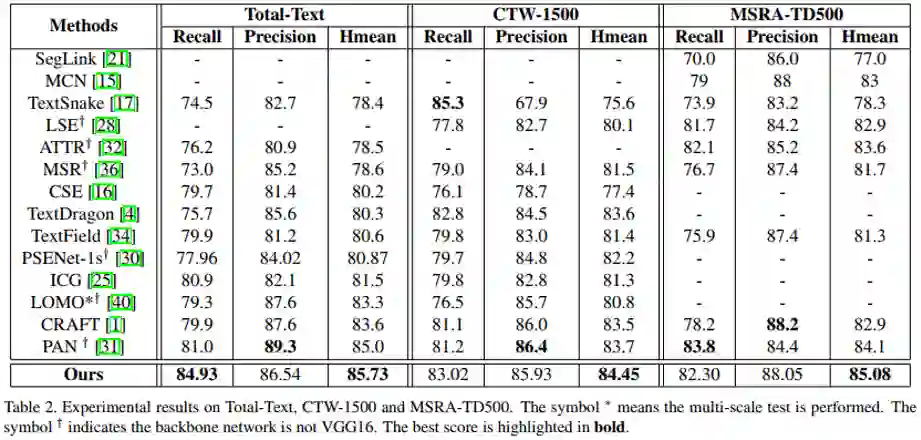
从表2来看,该文的方法在曲形文本数据集(Total-Text和CTW1500)以及多语言长文本数据集(MSRA-TD500)上都取得了State-of-the-art的检测效果。

图7展示了一些可视化的场景文本检测结果图。该方法能够较好地检测任意形状的场景文本,并且在长文本且字符间距较大的情况下也能取得很好的检测性能。
-
论文下载:http://arxiv.org/abs/2003.07493; -
代码链接:https://github.com/GXYM/DRRG;
原文作者:Shi-Xue Zhang (张世学), XiaobinZhu (祝晓斌), Jie-BoHou (侯杰波), ChangLiu (刘畅), ChunYang (杨春), HongfaWang (王红法), Xu-ChengYin* (殷绪成).
编排:高 学
审校:连宙辉
发布:金连文




