真实训练中Adam无法收敛到最佳位置?改进版 AdaX来拯救!


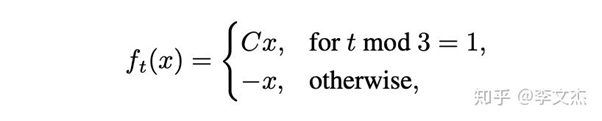
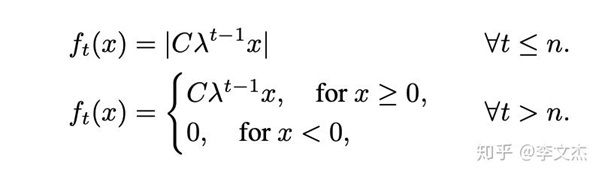

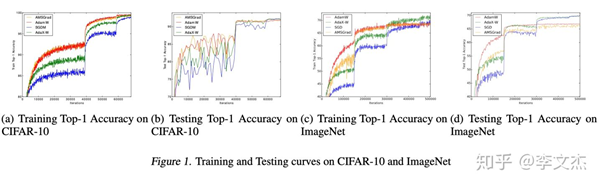
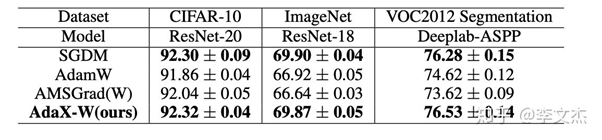
[2]. Zhou, Z., Zhang, Q., Lu, G., Wang, H., Zhang, W., and Yu, Y. Adashift:Decorrelation and convergence of adaptive learning rate methods. Proceedingsof 7th International Conference on Learning Representations (ICLR), 2019.
[4]. Luo, L., Xiong, Y., Liu, Y., and Sun, X. Adaptive gradi- ent methods withdynamic bound of learning rate. Proceedings of 7th InternationalConference on Learning Representations, 2019.

登录查看更多
相关内容
专知会员服务
54+阅读 · 2020年3月5日
Arxiv
7+阅读 · 2019年10月8日



相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年10月8日