一文告诉你Adam、AdamW、Amsgrad区别和联系,助你实现Super-convergence的终极目标
序言:Adam自2014年出现之后,一直是受人追捧的参数训练神器,但最近越来越多的文章指出:Adam存在很多问题,效果甚至没有简单的SGD + Momentum好。因此,出现了很多改进的版本,比如AdamW,以及最近的ICLR-2018年最佳论文提出的Adam改进版Amsgrad。那么,Adam究竟是否有效?改进版AdamW、Amsgrad与Adam之间存在什么联系与区别?改进版是否真的比Adam更好呢?相信这篇文章将会给你一个清晰的答案。
Adam Roller-Coaster
Adamoptimizer的发展历程就像坐过山车一样。Adam最先于2014年提出,其核心是一个简单而直观的想法:当我们知道某些参数确实需要比其他参数移动地更快时,为什么要对每个参数都使用相同的学习速率呢?由于最近的梯度的平方告诉我们可以从每个权重得到多少信息,我们可以除以这一点,以确保即使变化最缓慢的权重也能获得发光的机会。Adam借鉴了这个思路,在标准方法里面加入了动量,并且(通过一些调整来保持早期Bathes不被biased)就是这样!
Adam首次发布后,深度学习社区在看到原始论文中的效果图(下图)之后,非常的兴奋:
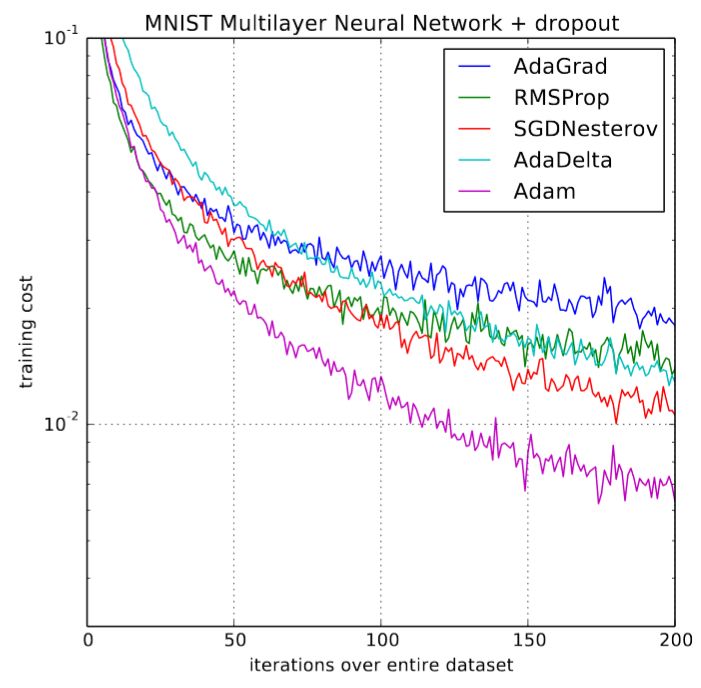
Adam和其他optimizer之间的比较
训练速度加快了200%!“总的来说,我们发现Adam非常强大,非常适合解决机器学习的各种非凸优化问题” 论文总结道。但是,那是三年前了,是一个深度学习发展的一个黄金epochs。但也渐渐逐渐清晰,这一切并不如我们所希望的那样。实际情况是,很少有研究论文使用Adam来训练他们的模型,一些新的研究,如《The Marginal Value of Adaptive Gradient Methods in Machine Learning》建议不要使用Adam,并通过多个实验中表明,传统的SGD+momentum的方法得到的结果更好。
但是在2017年底,Adam似乎获得了新生。Ilya Loshchilov和Frank Hutter在他们的论文《Fixing Weight Decay Regularization in Adam》中指出,所有的深度学习库中的Adam optimizer中实现的weight decay方法似乎都是错误的,并提出了一种简单的方法(他们称之为AdamW)来解决它。尽管他们的结果略有不同,但从下图的效果对比图中可以发现,结果令人振奋,:
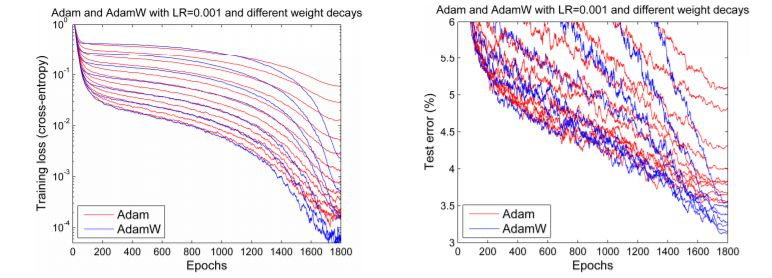
Adam和AdamW的对比
我们当然期待看到Adam的回归,因为似乎最初的结果可能会再次被发现。但事情并非如此。实际上,所有深度学习框架中,只有fastai,由Sylvain编写的代码中的的算法实现修复了这一bug。如果没有广泛的框架可用性,大多数人仍旧会被old、“broken”adam所困扰。
但这不是唯一的问题。未来会遇到更多的问题。两篇相互独立的论文都明确指出并证明了Adam中存在的收敛性问题,尽管其中一人声称修复了这一问题(并获得了ICLR-2018年的“最佳论文”奖),他们的算法称为Amsgrad。但是,如果我们是否从这个最具戏剧性的历史生活中学到了任何东西(至少在optimizer standards上是戏剧性的)呢?看起来似乎并没有。事实上,博士生Jeremy Bernstein 已经指出,声称的收敛问题实际上只是因为超参数的选择不当导致的,而且无论如何,Amsgrad也许无法解决这一问题。另一名博士生Filip Korzeniowski展示了一些早期的结果,这些结果似乎也支持这种关于Amsgrad的,令人沮丧的观点。
脱离Roller-coaster
那么对于我们这些只想快速且准确训练模型的人来说,我们该怎么办呢?让我们用经历数百年时间的,科学的方式来解决这场争论:通过实验!我们会在短时间内告诉你所有细节,首先,给出一个结果概述:
· 适当调整,Adam是真的有效!我们在各种任务上都获得了最新的成绩(就训练时间而言)
o 在DAWNBench竞赛中,通训练CIFAR10达到> 94%的准确度,评测当采用Augmentation时,只需要18个epoch;或不采用Augmentation时,只需要30个epochs;
o 采用Cars Stanford Dataset数据集,训练60个epochs,fine-tuning Resnet50达到90%的精确度(之前达到相同的结果需要600 epochs);
o 从头开始训练AWD LSTM或QRNN,需要90个epochs(或单个GPU上需要1个半小时),在Wikitext-2数据集上的达到state-of-the-art的perplexity(之前的report的对于LSTM需要750个epochs,对于QRNN需要500个epochs)。
· 这意味着我们已经看到(我们第一次意识到)在论文《Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates》使用Adam所获得的超级收敛效果(Super-Convergence)!超级收敛是在采用较大的学习率训练神经网络时发生的一种现象,使训练速度加快一倍。在了解这一现象之前,将CIFAR10训练达到94%的准确度大约需要100个epochs。
· 与之前的工作相比,我们看到Adam在我们尝试过的每个CNN图像问题上获得与SGD + Momentum一样的精确度,只要它经过适当调整,并且它几乎总是更快一点。
· Amsgrad是一个糟糕的“fix”的这一suggestion是正确的。我们一直发现,与普通的Adam / AdamW相比,Amsgrad在准确度(或其他相关指标)方面没有获得任何提升。
当你听到有人们说Adam没有像SGD + Momentum那样generalize的时候,你几乎总会发现,根本原因使他们为他们的模型选择了较差的超参数。Adam通常需要比SGD更多的regularization,因此在从SGD切换到Adam时,请务必调整正则化超参数。
以下是本文其余部分的概述:
1 AdamW
1.1 了解AdamW
1.2 实现AdamW
1.3 AdamW实验的结果
2 Amsgrad
2.1 了解Amsgrad
2.2 实现Amsgrad
2.3 Amsgrad实验的结果
3 完整结果表
1 AdamW
1.1 了解AdamW:weight decay or L2正规?
L2正则是一种减少过拟合的一种经典方法,它在损失函数中加入对模型所有权重的平方和,乘以给定的超参数(本文中的所有方程都使用python,numpy,和pytorch表示):
final_loss = loss + wd * all_weights.pow(2).sum() / 2
...其中wd是要设置的l2正则的超参数。这也称为weight decay,因为在应用普通的SGD时,它相当于采用如下所示来更新权重:
w = w - lr * w.grad - lr * wd * w
(注意,w 2相对于w的导数是2w。)在这个等式中,我们看到我们如何在每一步中减去一小部分权重,因此成为衰减。
我们查看过的所有深度学习库,都使用了第一种形式。(实际上,它几乎总是通过向gradients中添加wd * w来实现,而不是去改变损失函数:我们不希望在有更简单的方法时,通过修改损失来增加更多计算量。)
那么为什么要区分这两个概念,它们是否起到了相同的作用呢?答案是,它们对于vanilla SGD来说是一样的东西,但只要我们在公式中增加动量项,或者使用像Adam这样更复杂的一阶或二阶的optimizer,L2正则化(第一个等式)和权重衰减(第二个等式)就会变得不同。在本文的其余部分,当我们谈论weight decay时,我们将始终参考第二个公式(梯度更新时,稍微减轻权重)并谈谈L2正则化,如果我们想提一下经典的方法。
以SGD + momentum为例。使用L2正则化,并添加wd * w衰减项到公式中(如前所述),但不直接从权重中减去梯度。首先我们计算移动平均值(moving average):
moving_avg = alpha * moving_avg + (1-alpha) * (w.grad + wd*w)
...这个移动平均值将乘以学习率并从w中减去。因此,与将从w取得的正则化相关联的部分是lr *(1-alpha)* wd * w加上前一步的moving_avg值。
另一方面,weight decay的梯度更新如下式:
moving_avg = alpha * moving_avg + (1-alpha) * w.grad w = w - lr * moving_avg - lr * wd * w
我们可以看到,从与正则化相关联的w中减去的部分在两种方法中是不同的。当使用Adam optimizer时,它会变得更加不同:在L2正则化的情况下,我们将这个wd * w添加到gradients,然后计算gradients及其平方值的移动平均值,然后再使用它们进行梯度更新。而weight decay的方法只是在进行更新,然后减去每个权重。
显然,这是两种不同的方法。在尝试了这个之后,Ilya Loshchilov和Frank Hutter在他们的文章中建议我们应该使用Adam的权重衰减,而不是经典深度学习库实现的L2正则化方法。
1.2 实现AdamW
我们应该怎么做?基于fastai库为例,具体来说,如果使用fit函数,只需添加参数 use_wd_sched = True:
learn.fit(lr, 1, wds=1e-4, use_wd_sched=
True)
如果您更喜欢新的API,则可以在每个训练阶段使用参数wd_loss = False(计算损失函数时,不使用weight decay):
phases = [TrainingPhase(1, optim.Adam, lr, wds=1-e4, wd_loss=False)]
learn.fit_opt_sched(phases)
以下给出基于fast库的一个简单实现。在optimizer的step函数的内部,只使用gradients来更新参数,根本不使用参数本身的值(除了weight decay,但我们将在外围处理)。然后我们可以在optimizer处理之前,简单地执行权重衰减。在计算梯度之后仍然必须进行相同操作(否则会影响gradients值),所以在训练循环中,你必须找到这个位置。
loss.backward()
#Do the weight decay here!
optimizer.step()
当然,optimizer应该设置为wd = 0,否则它会进行L2正则化,这正是我们现在不想要的。现在,在那个位置,我们必须循环所有参数,并做weight decay更新。你的参数应该都在optimizer的字典param_groups中,因此循环看起来像这样:
loss.backward()
for group in optimizer.param_groups():
for param in group['params']:
param.data = param.data.add(-wd * group['lr'], param.data)
optimizer.step()
1.3 AdamW实验的结果:它有效吗?
我们在计算机视觉问题上第一次进行测试得到的结果非常令人惊讶。具体来说,我们采用Adam+L2正规化在30个epochs内获得的准确率(这是SGD通过去1 cycle policy达到94%准确度所需要的必要时间)的平均为93.96%,其中一半超过了94%。使用Adam + weight decay则达到94%和94.25%之间。为此,我们发现使用1 cycle policy时,beta2的最佳值为0.99。我们将beta1参数视为SGD的动量(意味着它随着学习率的增长从0.95变为0.85,然后当学习率变低时再回到0.95)。
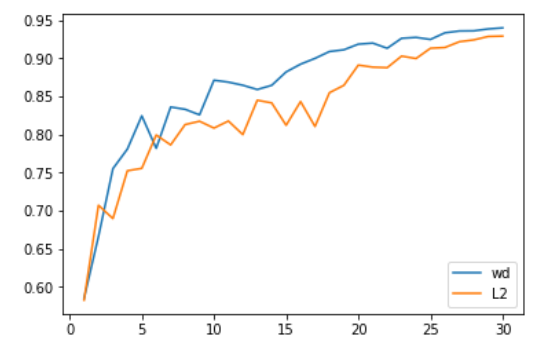
L2正则化或权重衰减的准确性
更令人印象深刻的是,使用Test Time Augmentation(即对测试集上的一个图像,取四个和他相同data-augmented版本的预测的平均值作为最终预测结果),我们可以在18个epochs内达到94%的准确率(平均预测值为93.98%) )!通过简单的Adam和L2正规,超过20个epochs时,达到94%。
在这些比较中要考虑的一件事是,改变我们正则的方式会改变weight decay或学习率的最佳值。在我们进行的测试中,L2正则化的最佳学习率是1e-6(最大学习率为1e-3),而0.3是weight decay的最佳值(学习率为3e-3)。在我们的所有测试中,数量级的差异非常一致,主要原因是,L2正则于梯度的平均范数(相当小)相除后,变得非常有效,且Adam使用的学习速率非常小(因此,weight decay的更新需要更强的系数)。
那么,使用Adam时,权重衰减总是比L2正规化更好吗?我们还没有发现一个明显更糟的情况,但对于迁移学习问题或RNN而言(例如在Stanford cars数据集上对Resnet50进行微调),它没有获得更好的结果。
2 Amsgrad
2.1 了解Amsgrad
最近 Sashank J. Reddi,Satyen Kale和Sanjiv Kumar 在ICLR-2018的最佳论文《On the Convergence of Adam and Beyond》了中提出了Amsgrad。通过分析Adam optimizer的收敛证明,他们发现更新规则中的存在错误,且可能导致算法收敛到sub-optimal point。他们设计了理论实验,展示了Adam失败的场景,并提出了一个简单的解决方案。
为了理解错误和修复,让我们先看看Adam的更新公式:
avg_grads = beta1 * avg_grads + (1-beta1) * w.grad
avg_squared = beta2 * (avg_squared) +
(1-beta2) * (w.grad ** 2)
w = w - lr * avg_grads / sqrt(avg_squ
ared)
我们刚刚忽略了bias项(对训练开始时很有用),专注于重点。作者发现的Adam的proof中的存在的错误是它需要值(quantity)
lr / sqrt(avg_squared)
...这是我们在平均梯度方向上采取的step,随着训练过程减少。由于学习率通常是恒定的或降低的(除了像我们这样,试图获得超收敛的疯狂的人),作者提出的修正是通过添加另一个变量来跟踪他们的最大值来强制avg_squared值增加。
2.2 实现Amsgrad
相关文章获得了ICLR 2018的最佳论文奖,并非常受欢迎,以至于它已经在两个主要的深度学习库都实现了,pytorch和Keras。除了使用Amsgrad = True打开选项外,几乎没有什么可做的。
这将上一节中的权重更新代码更改为以下内容:
avg_grads = beta1 * avg_grads + (1-beta1) * w.grad
avg_squared = beta2 * (avg_squared) +
(1-beta2) * (w.grad ** 2)
max_squared = max(avg_squared,
max_squared)
w = w - lr * avg_grads / sqrt(max_squ
ared)
2.3 Amsgrad实验的结果:除了很多噪音意外什么也没有
事实证明,Amsgrad结果令人失望。在我们的实验中,没有一个实验证明它是有点帮助的,即使确实Amsgrad发现的最小值有时略低于(在损失方面)Adam达到的指标(精度,f1得分) ...)最终结果总是恶化(参见我们的introduction,或更多的例子:https://fdlm.github.io/post/amsgrad/)
Adam optimizer在深度学习中的收敛性证明(proof of convergence)(因为它是针对凸问题的)以及它们在其中发现的错误对于与现实生活中的实际问题无关的合成实验来说是至关重要的。实际测试表明,当avg_squared gradients想要减少时,最好的结果是这样做。
这表明,即使关注理论可以获得一些新想法,但它也不能取代实验(以及很多实验!)来确保这些想法能真正帮助从业者训练出更好的模型。
附录:完整结果
从头开始训练CIFAR10(模型是一个比较宽的resnet 22,最终的结果是五个测试集上测平均错误率):

在Stanford Cars数据集上,对Resnet50进行微调(前20个epochs不改变学习率,后40个epochs采用不同的学习率学习):

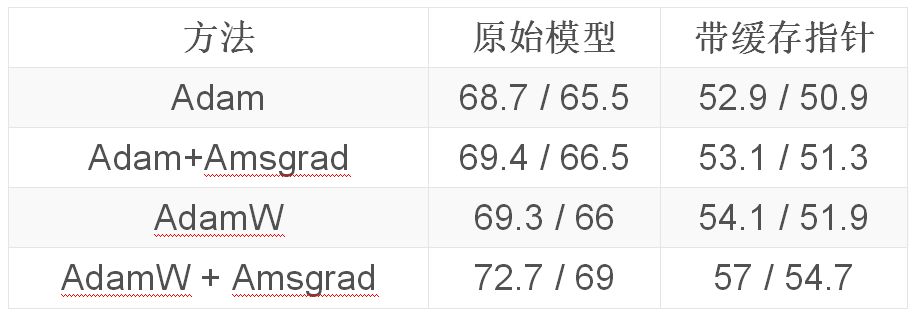
使用github repo中的超参数训练AWD LSTM (结果显示验证/测试集的perplexity,有或没有缓存指针(cache pointer)):
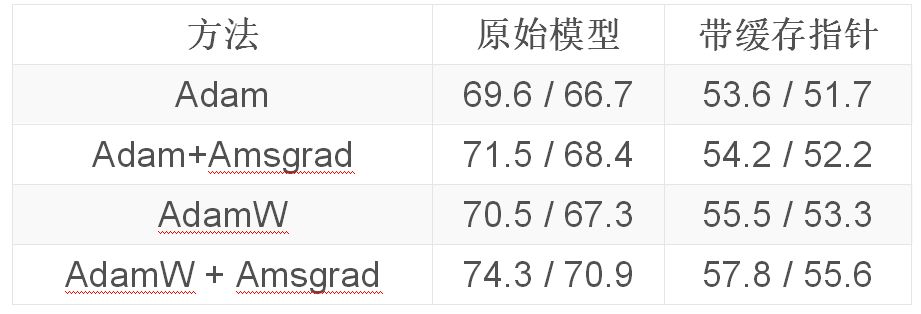
QRNN相同,不采用LSTM:
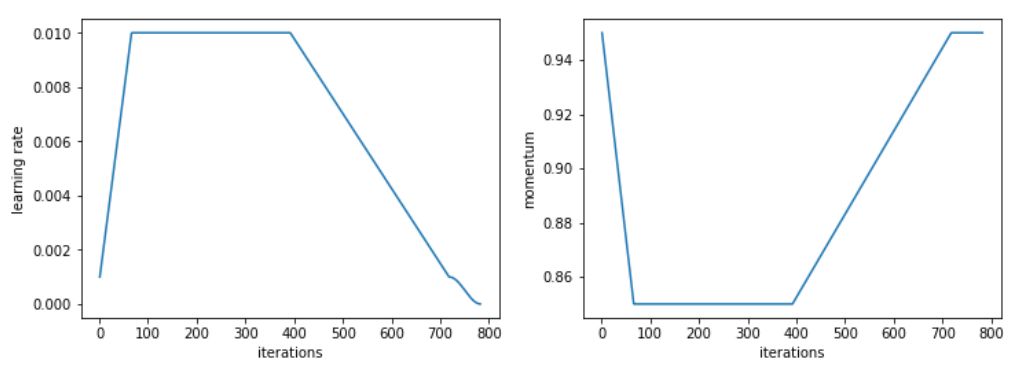
对于这项特定任务,我们使用了1cycle policy的修改版本,更快地增加学习速率,然后在再次下降之前具有更长时间的高恒定学习速率。
Adam和其他optimizer之间的比较
https://github.com/sgugger/Adam-experime
nts提供了所有相关超参数的值以及用于得到这些结果的代码。
往期精彩内容推荐
AI教父-深度学习之父-Geffery Hinton个人简介
精品推荐-2018年Google官方Tensorflow峰会视频教程完整版分享
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用



DeepLearning_NLP


深度学习与NLP
商务合作请联系微信号:lqfarmerlq