Adam那么棒,为什么还对SGD念念不忘 (2)

一代又一代的研究者们为了我们能炼(xun)好(hao)金(mo)丹(xing)可谓是煞费苦心。从理论上看,一代更比一代完善,Adam/Nadam已经登峰造极了,为什么大家还是不忘初心SGD呢?
上篇文章中( Adam 那么棒,为什么还对 SGD 念念不忘 (1) —— 一个框架看懂优化算法 ),我们用一个框架来回顾了主流的深度学习优化算法。可以看到,一代又一代的研究者们为了我们能炼(xun)好(hao)金(mo)丹(xing)可谓是煞费苦心。从理论上看,一代更比一代完善,Adam/Nadam已经登峰造极了,为什么大家还是不忘初心SGD呢?
举个栗子。很多年以前,摄影离普罗大众非常遥远。十年前,傻瓜相机开始风靡,游客几乎人手一个。智能手机出现以后,摄影更是走进千家万户,手机随手一拍,前后两千万,照亮你的美(咦,这是什么乱七八糟的)。但是专业摄影师还是喜欢用单反,孜孜不倦地调光圈、快门、ISO、白平衡……一堆自拍党从不care的名词。技术的进步,使得傻瓜式操作就可以得到不错的效果,但是在特定的场景下,要拍出最好的效果,依然需要深入地理解光线、理解结构、理解器材。
优化算法大抵也如此。在上一篇中,我们用同一个框架让各类算法对号入座。可以看出,大家都是殊途同归,只是相当于在SGD基础上增加了各类学习率的主动控制。如果不想做精细的调优,那么Adam显然最便于直接拿来上手。
但这样的傻瓜式操作并不一定能够适应所有的场合。如果能够深入了解数据,研究员们可以更加自如地控制优化迭代的各类参数,实现更好的效果也并不奇怪。毕竟,精调的参数还比不过傻瓜式的SGD,无疑是在挑战顶级研究员们的炼丹经验!
最近,不少paper开怼Adam,我们简单看看都在说什么:
Adam罪状一:可能不收敛
这篇是正在深度学习领域顶级会议之一 ICLR 2018 匿名审稿中的一篇论文《On the Convergence of Adam and Beyond》,探讨了Adam算法的收敛性,通过反例证明了Adam在某些情况下可能会不收敛。
回忆一下上文提到的各大优化算法的学习率:
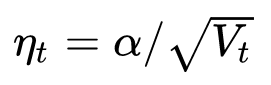
其中,SGD没有用到二阶动量,因此学习率是恒定的(实际使用过程中会采用学习率衰减策略,因此学习率递减)。AdaGrad的二阶动量不断累积,单调递增,因此学习率是单调递减的。因此,这两类算法会使得学习率不断递减,最终收敛到0,模型也得以收敛。
但AdaDelta和Adam则不然。二阶动量是固定时间窗口内的累积,随着时间窗口的变化,遇到的数据可能发生巨变,使得 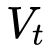
这篇文章也给出了一个修正的方法。由于Adam中的学习率主要是由二阶动量控制的,为了保证算法的收敛,可以对二阶动量的变化进行控制,避免上下波动。
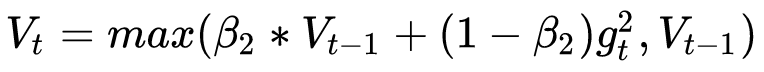
通过这样修改,就保证了
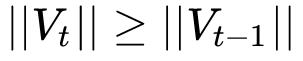
从而使得学习率单调递减。
Adam罪状二:可能错过全局最优解
深度神经网络往往包含大量的参数,在这样一个维度极高的空间内,非凸的目标函数往往起起伏伏,拥有无数个高地和洼地。有的是高峰,通过引入动量可能很容易越过;但有些是高原,可能探索很多次都出不来,于是停止了训练。
近期Arxiv上的两篇文章谈到这个问题。
第一篇就是前文提到的吐槽Adam最狠的UC Berkeley的文章《The Marginal Value of Adaptive Gradient Methods in Machine Learning》。文中说到,同样的一个优化问题,不同的优化算法可能会找到不同的答案,但自适应学习率的算法往往找到非常差的答案(very poor solution)。他们设计了一个特定的数据例子,自适应学习率算法可能会对前期出现的特征过拟合,后期才出现的特征很难纠正前期的拟合效果。但这个文章给的例子很极端,在实际情况中未必会出现。
另外一篇是《Improving Generalization Performance by Switching from Adam to SGD》,进行了实验验证。他们CIFAR-10数据集上进行测试,Adam的收敛速度比SGD要快,但最终收敛的结果并没有SGD好。他们进一步实验发现,主要是后期Adam的学习率太低,影响了有效的收敛。他们试着对Adam的学习率的下界进行控制,发现效果好了很多。
于是他们提出了一个用来改进Adam的方法:前期用Adam,享受Adam快速收敛的优势;后期切换到SGD,慢慢寻找最优解。这一方法以前也被研究者们用到,不过主要是根据经验来选择切换的时机和切换后的学习率。这篇文章把这一切换过程傻瓜化,给出了切换SGD的时机选择方法,以及学习率的计算方法,效果看起来也不错。
这个算法挺有趣,下一篇我们可以来谈谈,这里先贴个算法框架图:

到底该用Adam还是SGD?
所以,谈到现在,到底Adam好还是SGD好?这可能是很难一句话说清楚的事情。去看学术会议中的各种paper,用SGD的很多,Adam的也不少,还有很多偏爱AdaGrad或者AdaDelta。可能研究员把每个算法都试了一遍,哪个出来的效果好就用哪个了。毕竟paper的重点是突出自己某方面的贡献,其他方面当然是无所不用其极,怎么能输在细节上呢?
而从这几篇怒怼Adam的paper来看,多数都构造了一些比较极端的例子来演示了Adam失效的可能性。这些例子一般过于极端,实际情况中可能未必会这样,但这提醒了我们,理解数据对于设计算法的必要性。优化算法的演变历史,都是基于对数据的某种假设而进行的优化,那么某种算法是否有效,就要看你的数据是否符合该算法的胃口了。
算法固然美好,数据才是根本。
另一方面,Adam之流虽然说已经简化了调参,但是并没有一劳永逸地解决问题,默认的参数虽然好,但也不是放之四海而皆准。因此,在充分理解数据的基础上,依然需要根据数据特性、算法特性进行充分的调参实验。
少年,好好炼丹吧。
转载声明:本文转载自「机器学习炼丹记」,搜索「julius-ai」即可关注。

上海交通大学博士讲师团队
从算法到实战应用
涵盖 CV 领域主要知识点
手把手项目演示
全程提供代码
深度剖析 CV 研究体系
轻松实战深度学习应用领域!
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
到底该用Adam还是SGD(1)
▼▼▼



