ICLR2019最佳论文!神经网络子网络压缩10倍,精确度保持不变 | MIT出品
铜灵 发自 凹非寺
量子位 出品 | 公众号 QbitAI
在大洋彼岸的新奥尔良,正在举行一年一度的机器学习顶会:ICLR 2019。
今年,ICLR19共收到了1578篇投稿,较去年增长60%。在这1600篇论文中,MIT的“彩票假设”理论从中脱颖而出,其论文斩获今年的最佳论文。
这是项什么研究?
研究人员证明,将神经网络包含的子网络缩小至原来的十分之一,依旧不会影响训练精度,甚至于,压缩后的模型可能比原神经网络更快!
来看看今年的研究新风向。

彩票假设
这篇获奖论文名为The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks,提出了一种叫作“彩票假设”(lottery ticket hypothesis)的缩小方法。
此前,神经网络的剪枝技术能将网络的参数减少到90%,但此方法的弊端也很明显,即剪枝架构一开始的训练就相当困难。
MIT计算机科学与人工智能实验室(CSAIL)的研究人员表示,与其在后期修修剪剪,何必不在一开始就创建一个尺寸合适的网络呢?
他们将传统的深度学习方法比作乐透,训练大型神经网络就像在通过盲目随机选号中奖,而这种新的方法不采用这种大海捞针的方式,想在一开始就拿到最后中奖的号码。
于是乎,“彩票假设”问世。
他们发现,传统的剪枝技术会在神经网络子网络处动刀,让初始化后的子网络能够进行有效训练。
密集、随机初始化的前馈神经网络包含一些子网络,也就是中奖号码,当对其单独进行训练时,这些子网络能够在相似迭代次数中达到与原始网络比肩的准确率。
问题来了,如何找到这个中奖号码呢?总共分为四步:
随机初始化一个神经网络f(x; θ0)
训练这个网络j次,得到网格参数θj
修剪θj中p%的参数,创建mask m
用θ0重新设置剩余网络,创建中奖号码f(x; m⊙θ0)
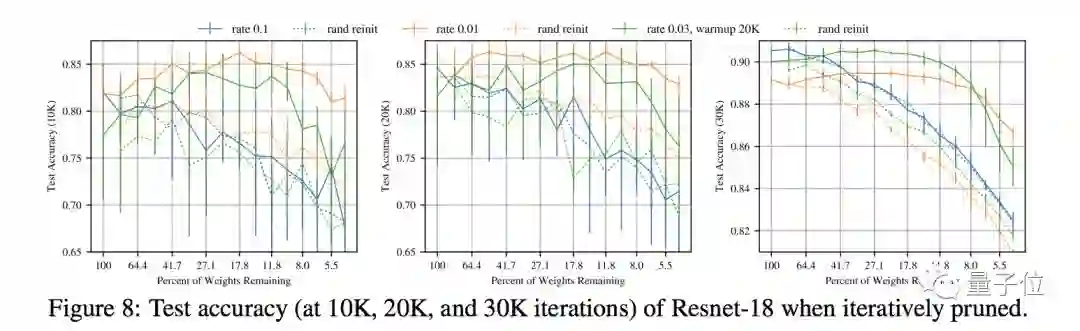
在MNIST和CIFAR10数据集上,“中奖彩票”的大小是很多全连接和卷积前馈架构的10%~20%。
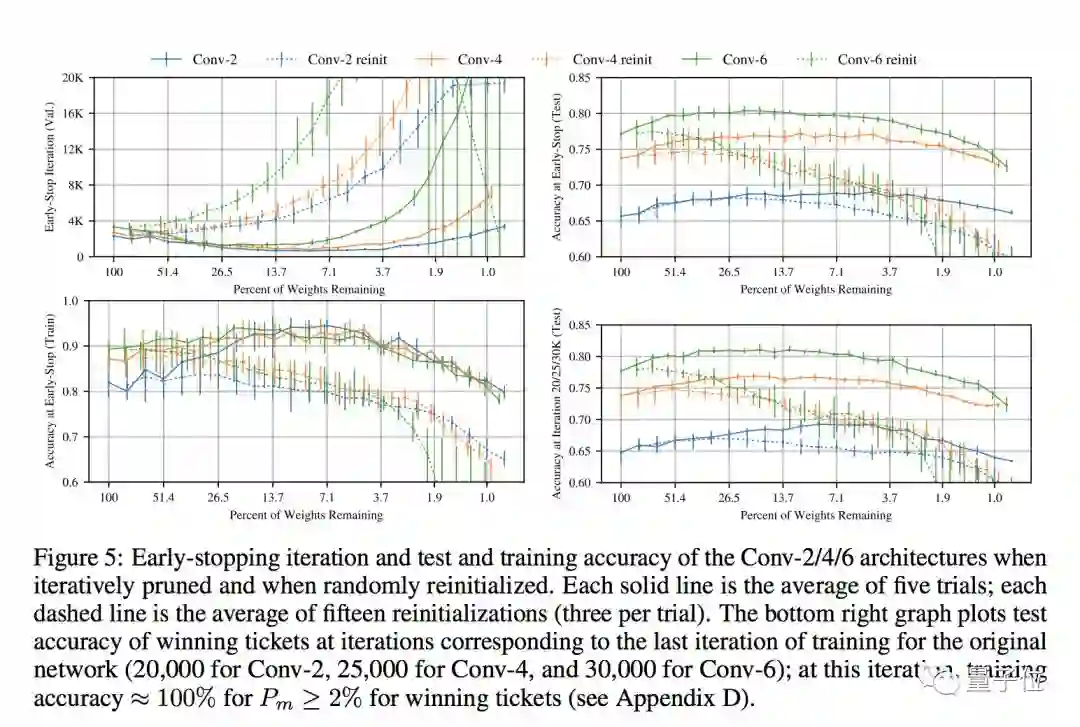
△ 上图为当迭代剪枝和再次随机初始化时,Conv-2/4/6 架构的早停迭代、测试和训练准确率
并且,比原始网络的学习速度更快:甚至准确度更高:
论文地址:
https://arxiv.org/abs/1803.03635
作者团队
这篇论文背后的研究人员只有两位。
一作为MIT的在读博士生Jonathan Frankle,在普林斯顿大学完成计算机科学的本科和研究生学习时,Frankle小哥曾去谷歌、微软、乔治城大学实习,主要研究人工智能、应用密码学和技术政策。
二作Michael Carbin为MIT电子工程和计算机科学的助理教授,此前在微软雷德蒙研究院的研究员,从事大规模深度学习系统的研究,包括优化和应用。

此前,Carbin的数篇论文被ICML19、OOPSLA18、LICS18等机器学习大会接收。
最佳论文×2
今年的ICLR最佳论文共有两篇,除了彩票假设外,还有一篇蒙特利尔大学 MILA 研究所和微软研究院的作品:
Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks,翻译过来就是《有序神经元:将树结构集成到循环神经网络》。

自然语言是一种有层次的结构:小的单元会嵌套在大单元里,比如短语会嵌套在句子中。当较大的单元关闭时,其中的小单元也必须关闭。
虽然标准的LSTM架构可以将不同的神经元在不同的时间阶段追踪信息,但在模型构成层次上差别不大。
在这篇论文中,研究人员提出,通过对神经元进行排序,增加这种归纳偏差,用一个控制输入和遗忘门的向量来确保当给定神经元更新时,跟随它的所有神经元也将按照顺序被更新。
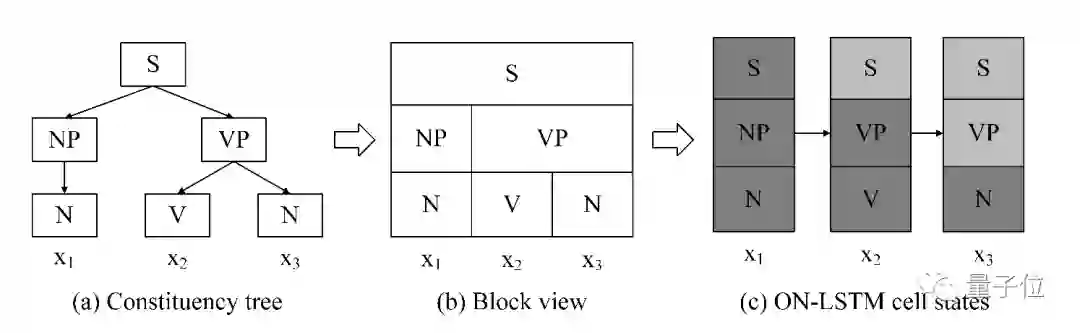
这种全新的循环结构称为有序神经元 LSTM (ON-LSTM),在语言建模、无监督语法分析、目标语法评估和逻辑推理这四个不同的任务上取得了不错的性能。
论文地址:
https://openreview.net/forum?id=B1l6qiR5F7
传送门
最后,附上ICLR 2019官网地址:
https://iclr.cc/
— 完 —
小程序|get更多AI学习干货

加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !




