谷歌大脑开源TensorFuzz库,可自动调试神经网络

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)

Brain 团队基于传统软件工程的覆盖引导模糊技术开发出了适用于神经网络的 CGF 方法。具体来说,他们的工作内容如下:
将 CGF 概念引入到神经网络中,并描述了如何使用快速近似最近邻算法来检查覆盖率。
开源了一个名为 TensorFuzz 的库。
使用 TensorFuzz 查找训练过的神经网络的数值问题、神经网络与其量化版本之间的分歧,以及字符级语言模型中的不良行为。
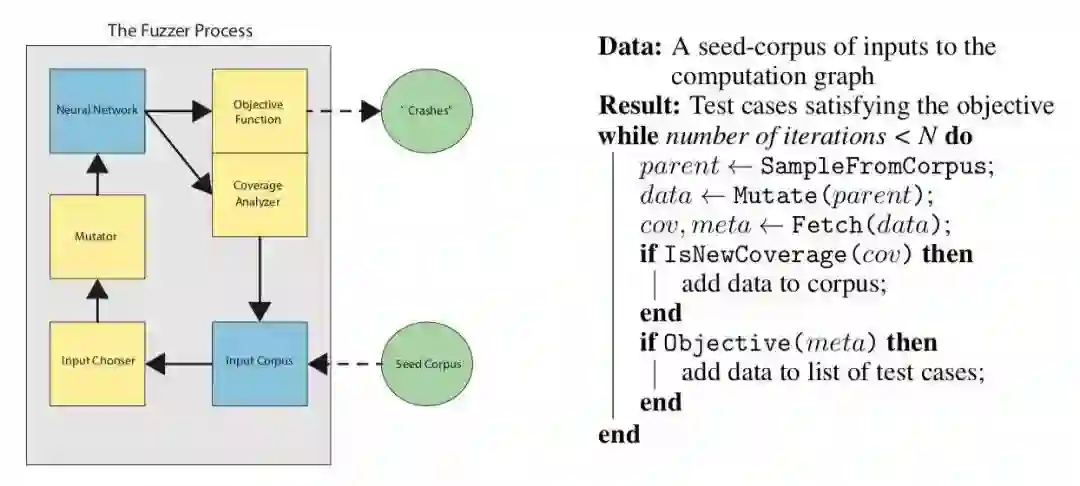
fuzzing 主循环的粗略描述。左:fuzzing 过程的数据流图。右:fuzzing 主循环的算法描述。
覆盖引导模糊(Coverage-guided fuzzing,CGF)用于发现真实软件中存在的严重错误。在覆盖引导模糊测试中,模糊测试过程将维护一个输入语料库,其中包含程序的输入。根据一些变异程序对这些输入进行随机变化,并且在它们执行新的“覆盖”时,变异输入被保留在语料库中。覆盖取决于模糊器的类型和想要达到的目标,一个常见的衡量标准是已执行的代码集。如果一个新的输入导致代码在 if 语句上以不同于先前的方式进行分支,那么覆盖率就会增加。
CGF 在传统软件中已经可以成功地识别错误,那么它是否也可以应用在神经网络中呢?
传统的覆盖率指标会跟踪已执行的代码行和分支。神经网络实现为一系列矩阵乘法,后面跟上元素运算。这些操作的底层实现可能包含许多分支语句,其中有很多是基于矩阵的大小,也就是基于神经网络架构,因此分支行为几乎独立于神经网络输入中的特定值。在几个不同输入上运行的神经网络通常要执行相同的代码行并采用相同的分支,但由于输入和输出值的变化,会产生一些有趣的行为变化。因此,现有的 CGF 工具可能找不到神经网络的这些有趣的行为。
谷歌大脑团队选择使用快速近似最近邻算法来确定两组神经网络的“激活”是否存在不同的意义。这样就为神经网络产生有用的结果提供了一个覆盖率指标,即使神经网络的底层实现没有使用依赖于数据的分支。
谷歌大脑团队实现了一个叫作 TensorFuzz 的工具。它的工作方式与其他模糊测试工具类似,只是它更适合用于神经网络测试。它与其他使用 C 或 C++ 开发的计算机程序不一样,它是直接将输入提供给任意的 TensorFlow 图。它不是通过查看基本代码块或控制流的变化来测量覆盖率,而是通过(粗略地说)查看计算图的“激活”来测量覆盖率。
模糊测试程序的整体结构与普通计算机程序的覆盖引导模糊器的结构非常相似。主要的区别在于,交互的对象不是已经检测过的计算机程序,而是 TensorFlow 图,通过向 TensorFlow 图提供输入并从中获取输出。
研究人员通过在不同的应用程序上应用 CGF 技术,证明该技术在一般性的情况下可以发挥它的作用。
CGF 可以快速找到数值误差:通过使用 CGF,应该能够简单地在元数据中添加数值检查操作并运行模糊器。为了验证这一假设,Brain 团队训练了一个完全连通的神经网络来对 MNIST 数据集中的数字进行分类。他们故意使用了很差的交叉熵损失,因此就存在数字出错的可能性。他们对模型进行了 35000 步的训练,mini-batch 为 100,此时验证准确率为 98%。然后他们检查了 MNIST 数据集中没有导致数字错误的元素。TensorFuzz 在多个随机初始化过程中快速发现了 NaN。如下图所示:
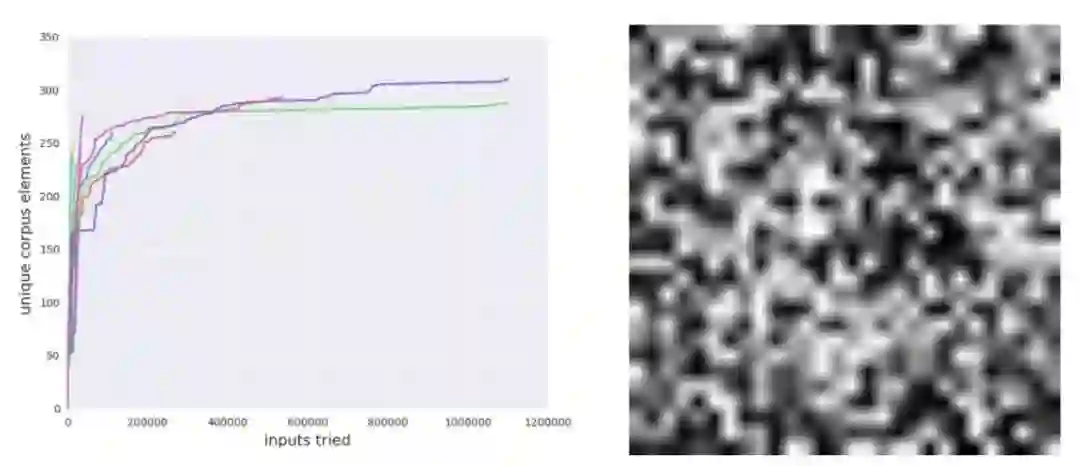
他们用一些不安全的数值运算训练了一个 MNIST 分类器,然后对来自 MNIST 数据集的随机种子运行 10 次模糊测试。模糊器每次运行都发现了一个非限定元素。左图:运行时模糊器的累计语料库大小,运行 10 次。右图:模糊器找到的图像示例。
量化是保存神经网络权重的过程,也是使用由较少内存为组成的数字表示来执行神经网络计算的过程。量化是一种流行的降低神经网络计算成本或尺寸的方法,并且被广泛应用于手机上的神经网络推理。
CGF 可以在数据周围的小区域内快速找到很多错误:Brain 团队使用 32 位模型的激活作为覆盖,基于种子图像周围半径 0.4 范围内的变异运行模糊器。他们限制了种子图像附近的输入,因为这些输入几乎都具有明确的类语义。通过这些设置,模糊器在尝试过的 70%的示例中产生了分歧。因此,CGF 可能可以发现在测试时发生的真实错误。如下图所示:
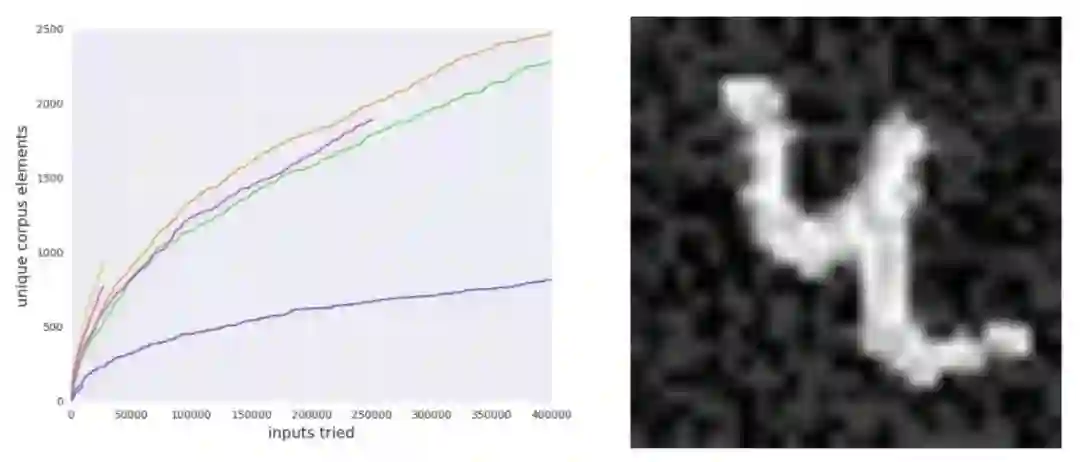
他们训练了一个带有 32 位浮点数的 MNIST 分类器,然后将相关的 TensorFlow 图截断为 16 位浮点数。 原始图和截断图对 MNIST 测试集的所有 10000 个元素进行了相同的预测,在大约 70%的测试图像中,模糊器能够在半径为 0.4 的范围内找到分歧。左图:运行时模糊器的累计语料库大小,运行 10 次。右图:模糊器找到的通过 32 位和 16 位神经网络进行分类的图像。
他们运行了一个 TensorFuzz 实例和一个随机搜索实例,每个实例运行 24 小时。TensorFuzz 和随机搜索都会生成重复单词,但 TensorFuzz 能够生成给定黑名单中的六个单词,而随机搜索只生成一个。
谷歌大脑团队为神经网络引入了覆盖引导模糊的概念,并描述了如何在此背景下构建有用的覆盖率检查器。他们通过查找数值误差、神经网络与其量化版本之间的分歧,以及揭示 RNN 的不良行为,证明了 TensorFuzz 的实用性。他们发布了 TensorFuzz 库,让其他人可以基于现有的工作继续研究,或使用模糊器来找出真正的问题。
论文地址:https://arxiv.org/pdf/1807.10875.pdf
开源项目地址:https://github.com/google/oss-fuzz

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!





