Ian Goodfellow最新论文:神经网络也能Debug

如今,神经网络对人们生活产生的影响日渐深刻,应用领域日渐广泛,包括医疗诊断、自动交通、公司决策、电网控制……神经网络有潜力去改变社会和日常生活中很多应用,拯救生命,为人们提供比人工更多的福利。然而,在这些福利到达之前,我们首先要确保神经网络足够可靠担此重任。
然而,机器学习的模型是出了名的难调试,对于神经网络更是如此,因此检查神经网络运行中可能出现的错误一直是个棘手的问题。不过近日该领域又取得了新的进展——谷歌大脑的研究人员将自动软件测试技术引入神经网络测试,并发现这种方法非常适合发现那些由罕见输入引起的错误。
为此,来自Google Brain的Augustus Odena以及Ian Goodfellow开发了专门针对神经网络的CGF(coverge-guided fuzzing,覆盖引导模糊测试)方法,并通过实验证明了它的有效性和强大的能力,并开发了名为Tensorfuzz的工具。
机器学习模型难以被理解和调试的原因是多方面的。首先,在概念上就很难确定用户究竟想了解模型的哪一方面;其次,对于特定问题答案的统计和计算都十分困难。这些属性也就导致了最近机器学习领域的“再现性危机”,难以通过调试得到可靠的结论困扰着人们。
而在机器学习模型中,神经网络更加难以调试。即使是针对结构简单的神经网络模型的最直接的问题,计算代价也是十分巨大的。因为实际使用的神经网络模型和理论模型可能存在很大差异。
覆盖引导模糊测试是一种软件测试方法,用来检查软件中严重的漏洞。目前最常用的两种覆盖引导模糊测试方法是AFL和libFuzzer。在测试过程中,一个模糊过程维护一个满足特定条件的输入语料库。一些变异程序会对这些输入进行随机的改变,当它们行使了新的“覆盖”时,就被保存到语料库中。而什么是覆盖呢?这取决于模糊测试的种类和想要达到的目标。一个常见的衡量标准是依据已经被执行的代码集合。如果新输入在if条件语句中以不同于先前的方式分支,则覆盖范围增加。

这种方法在传统软件的测试中大获成功,将其应用到神经网络中的想法就会自然而然地产生。传统的覆盖矩阵指标追踪的是哪些代码、哪些分支被覆盖。而就最基本的形式来说,神经网络是一系列的矩阵运算和元素运算。这些运算的底层可能也包含很多分支,但这都将由矩阵的大小和神经网络的体系结构来决定。因此执行哪些分支取决于神经网络的输入。而即使输入不同,神经网络也通常执行相同的代码行并采用相同的分支,但却会由于输入和输出值的变化而产生有趣的行为。因此,现有的CGF工具难以发现这些有趣的行为。而在这项工作中,研究者选择快速近似最近邻算法来确定两组神经网络“激活”是否存在有意义的区别,即使神经网络的底层软件实现没有使用更多的分支。
这并非是第一次在该方面的探索。前人也曾提出一些覆盖度量方法,但这些方法往往计算代价极大,难以在不同结构的神经网络上迁移。而研究者们在该工作中提出的度量方法则十分简单,计算代价小,且可以非常容易地在各种结构的神经网络中应用。开源的工具TensorFuzz更加适合与神经网络的调试,因为其将输入提供给任意的TensorFlow图,不通过查看基本块和控制流的变化,而是通过计算图的激活率来衡量覆盖率。
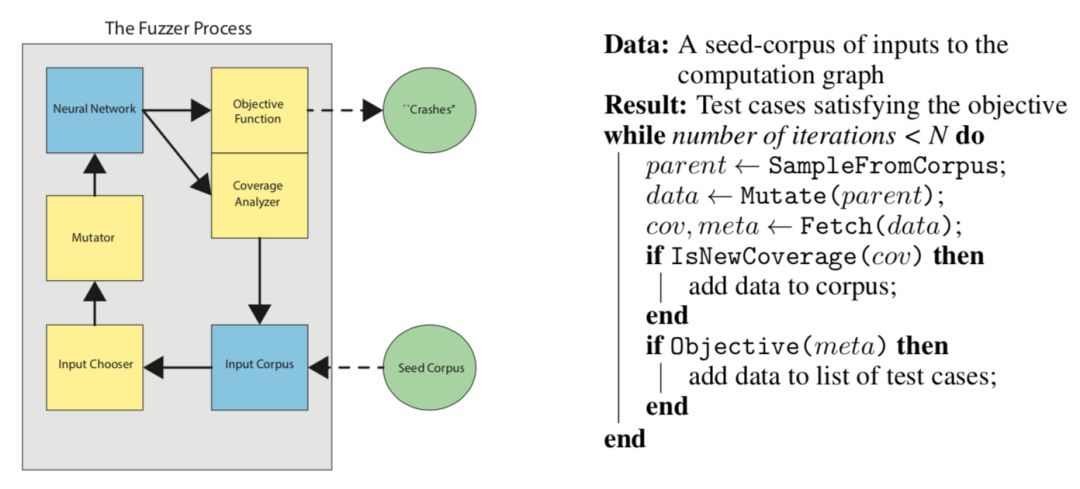
图一:模糊测试主流程的粗略描述。左侧为模糊测试的流程,并标示出了数据流;右侧为模糊测试主流程的算法表示。
以下为CGF的大致过程:
输入的选择:在任何时间,模糊控制器都要从语料库中选择输入进行变异。最优的选择取决于问题本身,通过特定的启发式算法进行搜索。
变异器:当选择器选择了语料库的一个元素时,变异器将对其进行变异。对于图像输入,研究者实现了两种不同类型的突变。第一种方法是将符合用户可配置方差的白噪声添加到输入中。第二种是添加白噪声,但是要限制变异元素与原始元素之间的差异。对于文本输入,不能直接向字符串添加统一的噪声,因此随机执行以下操作:删除随机位置的字符;在随机位置添加随机字符;在随机位置替换随机字符。
目标函数:我们希望模型某种状态,一般来说是错误的状态。目标函数正是用来评估是否已经达到这种状态。当输入进入计算图时,覆盖数组和元数据数据都作为输出返回。目标函数作用于元数据数组,标示那些满足要求的输入。
覆盖分析器:覆盖率分析器负责在TensorFlow运行时从中读取数组,将其转换为标示覆盖的python对象,并检查这些覆盖是否是新的。
研究者将该方法应用到实践之中,证明了其迅速发现错误的有效性。
首先,CGF可以高效地检查训练好的神经网络中出现的数值错误,比如NaN(Not a number非数值类型)。这类错误可能只会由一小部分输入产生,因此很难去调试。而在实践中一旦出现这样的情况,系统就可能会产生非常危险的行为。
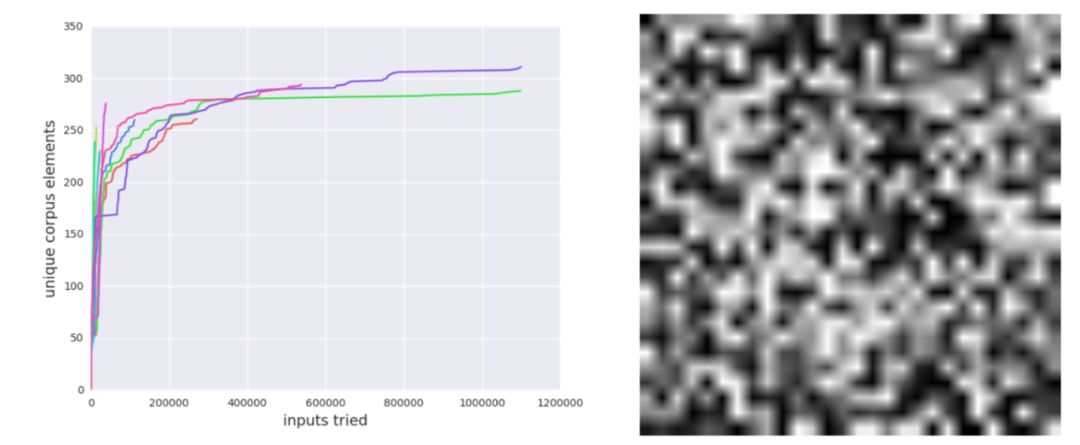
图二:研究者训练了一个 MNIST 手写数据集分类器,在训练过程中进行了一些不安全的数值操作。接下来研究者在其上运行了 10 次模糊测试器,每一次都发现了一个不符合限定的数据元素,而随机搜索则一个也没有发现。左图:运行 10 次时模糊语料库的大小;右图:模糊测试器发现的符合要求的图像。
量化是神经网络的参数被存储起来,由较少位的数值表示在计算机的存储单元中进行计算的过程。这是一种常见的减少计算代价的方式,常被应用于智能手机客户端的机器学习模型运行。但这种方式会在一定程度上损失计算精度。而这种损失导致的错误很难在已有的数据上发现,CGF则可以在迅速的在其上找到许多错误。
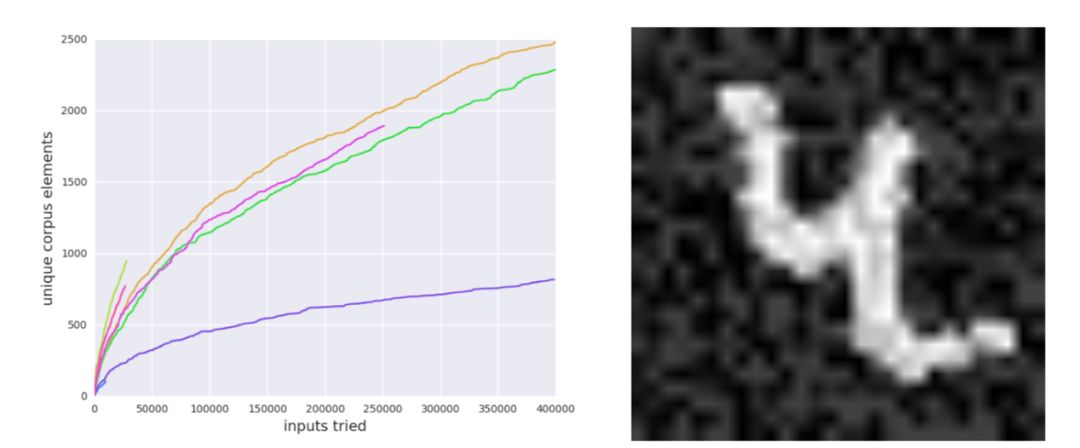
图三:研究者利用 32bit 浮点数训练 MNIST 分类器,再将与之相关的 TensorFlow 图截取为 16 位浮点数。原本的模型和截取后的在 MNIST 测试集的 10000 个元素上都做出了相同的预测。但 fuzzer 却能够发现他们之间的不同。左图:运行 10 次时模糊语料库的大小,一直向右延伸的线对应失败的 fuzzer 运行;右图:由 fuzzer 发现的图像,它被 32 位和 16 位神经网络分到了不同的类别。
此外,CGF还可以有效地检测字符级语言模型中的不良行为。研究者已经开源了名为TensorFuzz的软件库,希望帮助更多研究人员和开发人员在他们的实际工作中应用这一方法。
参考:
https://arxiv.org/pdf/1807.10875.pdf


【扫描二维码,备注工作单位+兴趣/研究方向,邀您进入德先生学术交流群,定期推送干货文章,解读学术动态,助力登顶学术科研高峰】

📚往期文章推荐

🔗美国密苏里科技大学Cihan Dagli:应对复杂自适应系统挑战的可行性方法
🔗图灵奖得主Hennessy、Patterson访谈:未来小学生都能做机器学习
🔗别人家的孩子:95后博士毕业入职达摩院,成阿里最年轻科学家
🔗手术台上96岁的吴孟超:老兵的"不老"传奇,刀尖上的"肝胆"春秋

德先生公众号 | 往期精选
在公众号会话位置回复以下关键词,查看德先生往期文章!
人工智能|机器崛起|区块链|名人堂
虚拟现实|智能制造|专家智库|科技快讯
名人轶事|峥嵘岁月|专题探讨|学术活动
……
更多精彩文章正在赶来,敬请期待!


点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。




