图鸭科技斩获CVPR图像压缩挑战赛冠军,TNGcnn4p技术全解读

在刚刚过去的 CVPR 2018 机器学习图像压缩挑战赛,MOS 值、ms-ssim 第一被图鸭科技的 Tucodec TNGcnn4p 摘获。
今天和大家介绍一下 MOS 与 MS-SSIM 第一获得者 Tucodec TNGcnn4p,Tucodec TNGcnn4p 是一个基于深度学习的图像压缩算法,其主要采用了自编码网络算法,并采用了端到端优化的图像压缩框架。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
本文中提出了一种可用于低码率图像压缩,并可进行端到端优化的图像压缩框架。在验证集和测试集上的实验结果均表明,当使用主观测评标准作为损失函数,在 MS-SSIM 和 MOS 等主观性能指标上能取得最优的性能。
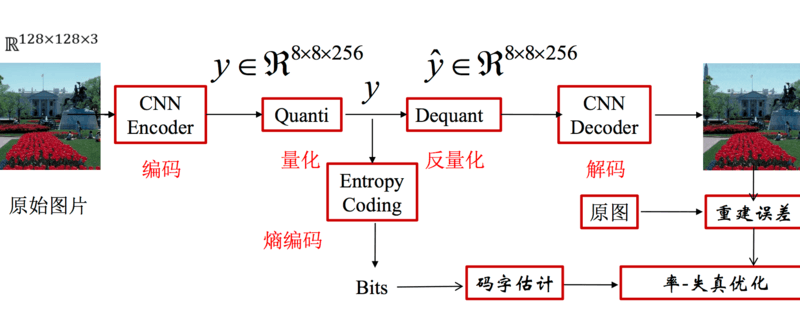
设计好网络模型后,需要使用图像进行训练。由于图像压缩属于无监督学习,无需人工标注,因此数据集是比较容易搜集的。无论是从网上爬取,还是自行使用相机拍摄,都不难得到大量高清图片。
常用的测试集有:
• Kodak PhotoCD 数据集,图像分辨率 768x512,约 40 万像素;
• Tecnick 数据集,约一百四十万像素;
• CVPR 2018 CLIC 数据集,图像类别广泛,分辨率不等(512 至 2048),文件尺寸不等(几百 K 到几 M)。
视频是由一帧一帧的图片组成,其压缩方法与图像压缩有一些相似之处,主要区别是,深度学习视频压缩相比图像压缩增加了帧间预测 / 差值。
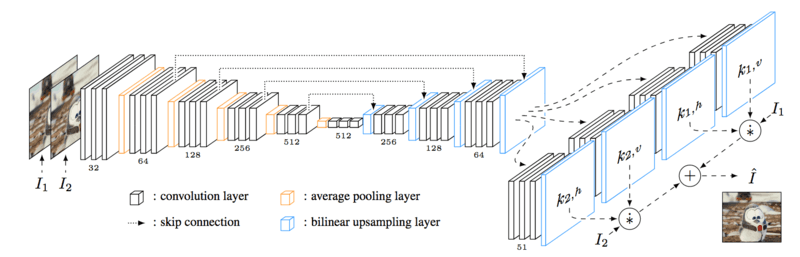
基于卷积网络进行帧间预测
帧间预测可以极大的减少视频帧间冗余。如 1 个参考帧,预测 N-1 帧为例,那么帧间预测的约束为参考帧和预测码字远小于每帧单独压缩的码字:
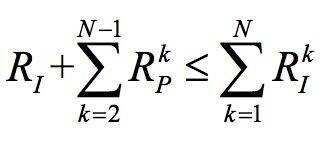
目前通用的深度学习压缩主要采用 CNN 做学习预测编码单元模式分类,在 2016 年 Liu Z、Yu X、Chen S 等发表的 CNN oriented fast HEVC intra CU mode decision 比较详细的介绍了用 CNN 学习预测编码单元模式的分类(2N x 2N 或 N x N)。
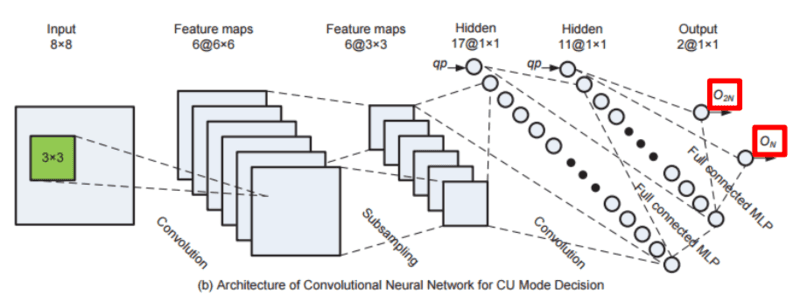
O2N、ON 输出为码率失真代价
视频帧内的下采样,主要采用了分块处理的方法,区别块是否适合进行下采样,之后对适合进行下采样的块进行下采样操作,对于不适合进行下采样的块不执行下采样操作。再完成这以步骤后,根据下采样块的情况分别用 CNN 或 DCTIF 进行上采样,来重建图像,当然为了更好的效果,亮度和色度通道也会根据需要采用不同的网络架构。在这给大家推荐 Jiahao Li 等在 2018 年发表的 Fully Connected Network-Based Intra Prediction for Image Coding 的论文,论文里有对下采样方法更加详细的介绍。
随着传统压缩的瓶颈到来,深度学习图像压缩的优势被越来越多的企业和研究员看到。深度学习在视频压缩领域潜力更大。深度学习在视频压缩领域的主要优势在于:
能够更好的实现变换学习,取得更优效果。
端对端的深度学习算法能够自行学习,不需要手工设计,相比传统视频压缩工作可以节省很多人力。
深度学习针对帧间预测采用的是光流法,相比传统的视频压缩使用的启发式方法,其更加的精确,在压缩中可以大大降低帧间冗余信息。
另一方面,基于深度学习进行视频压缩也会遇到很多挑战。比如控制实现帧间预测占用的比特。
在 CVPR 2018 学习图像压缩挑战上,图鸭科技的 Tucodec TNGcnn4p 获得了 MOS 与 MS-SSIM 两项冠军,综合排名第一。
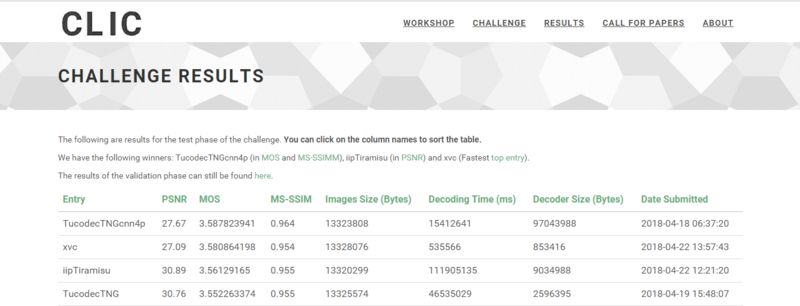
TucodecTNGcnn4p 是基于端到端的深度学习算法,其中使用了层次特征融合的网络结构,以及新的量化方式、码字估计技术,主要针对低码率图像压缩。Tucodec TNGcnn4p 网络使用了卷积模块和残差模块,将损失函数纳入 MS-SSIM。
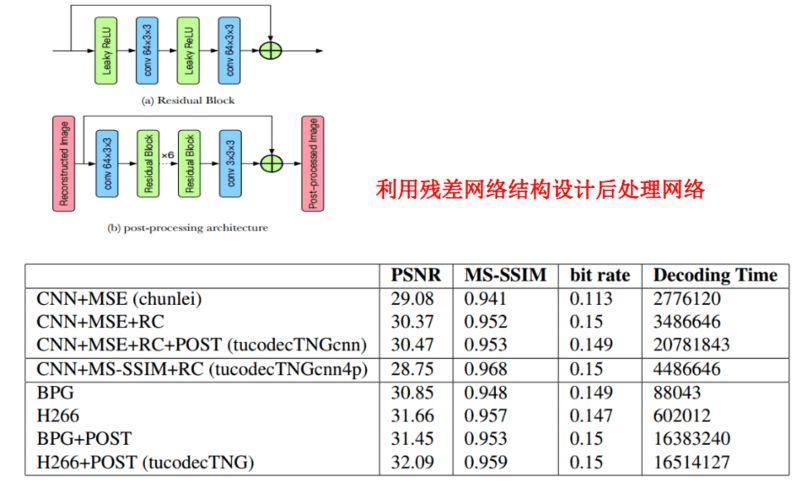
基于深度学习超分辨率重建图像
在图片压缩领域,图鸭科技重点关注低码率图片的超分辨率重建(SR)。相比高码率图片,低码率图片的失真较多,应用 SR 技术可以缓解这些图像上的瑕疵,获得更好的视觉效果。而高码率图片保留的原图细节更详细,很少会用到 SR 技术。
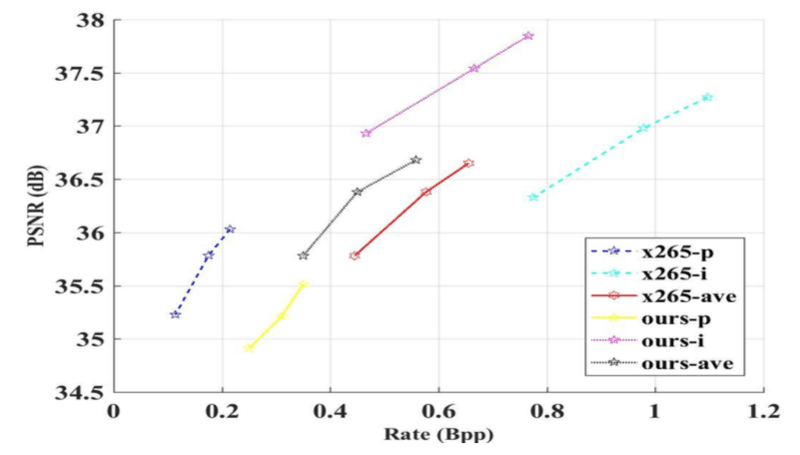
相对图像压缩而言,深度学习在视频压缩领域潜力更大。目前图鸭科技在基于深度学习的视频压缩方面,已经取得与 H265 媲美的效果。
最后附上 Tucodec TNGcnn4p 的论文链接,大家有需要可以自己下载研读:
http://openaccess.thecvf.com/CVPR2018_workshops/CVPR2018_W50.py#


如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!╰( ̄ω ̄o)




