Nature论文解读 | 基于深度学习和心脏影像预测生存概率

作者丨Peter
单位丨某基因科技公司生物信息工程师
研究方向丨生物信息
本文解读的文章来自今年 2 月份的 Nature 杂志新子刊 Machine Intelligence,标题为:Deep-learning cardiac motion analysis for human survival prediction。


实验设计
文章的实验设计如下:
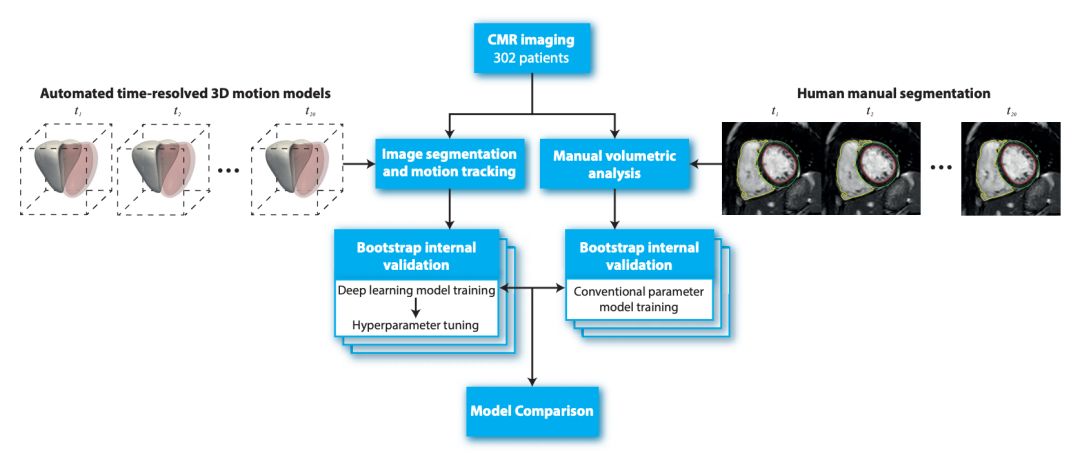
1. 采集 302 位病人的心脏三维 MRI 影响数据,并对其由认证医师标注出其血管流量等和诊断有关的特征和区域,同时对其进行了 12 年的跟踪并记录其医疗相关的事件;
2. 对比手动标记的图像分割和自动的标记和运动追踪;
3. 对手动的模型使用常规参数,对自动化标记的数据通过深度学习模型及超参数优化分别进行模型内部的验证;
4. 比较不同的模型在预测患者死亡率上的表现。
从上述流程可以看出,这篇文章的要点有三个,一是怎么去做图像分割,二是做预测模型,三是如何评价模型的表现。
图像分割
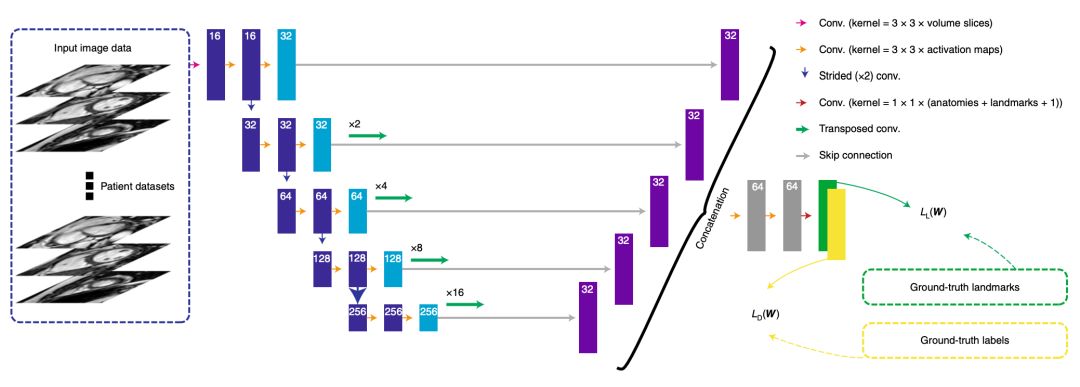
对于图像分割,首先是训练一个能够在单个影像中确定血流量的和图像分隔的模型,之后通过不同截面下的高分辨率数据,去训练一个更加平滑的分隔模型。
通过将血液流量和图像分割变成一个多任务的预测问题,通过全卷积网络,先分别提取单张图片的特征,之后再将不同截面的图片的特征整合(即上图的左半部分),而通过不同尺度的反卷积,可以将特征返还成图像,最终将预测的标签和实际标签的差作为损失函数,最终完成了图像的分割。通过不同时间段的数据,还可以对心脏的运动情况进行跟踪。
预测死亡率的模型
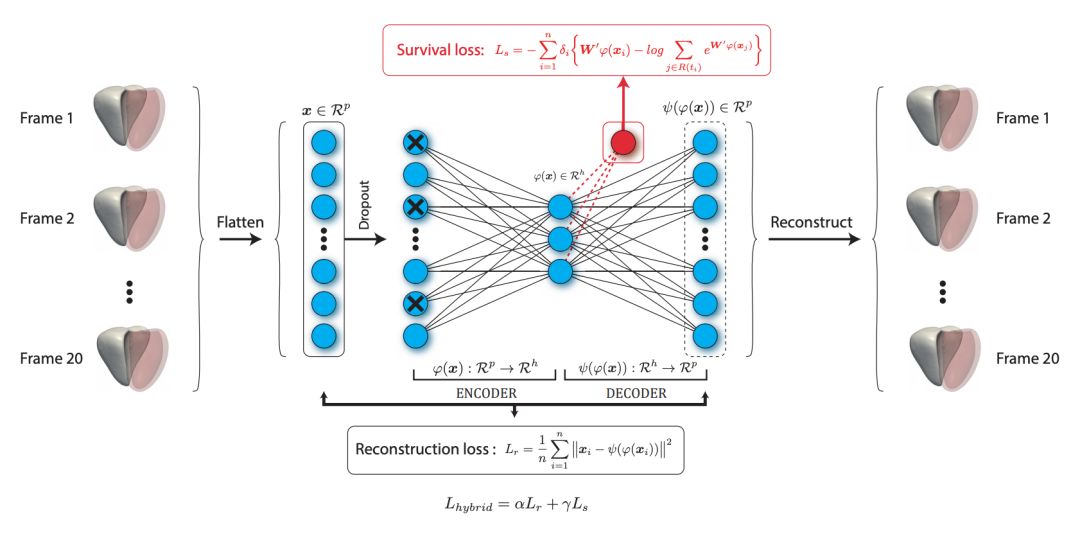
不同的病人各自有自己做过的 N 次心脏 MRI,通过二层的降噪自编码器,能够训练出一个能够鲁棒的用低维数据表达心脏 MRI 数据的模型。
该文的创新点在于将要预测的死亡风险也加入了待优化的损失函数,这里的重构误差是不同 n 次数据间 MSE 的平均值,而死亡风险使用了 Cox’s proportional hazards regression model。
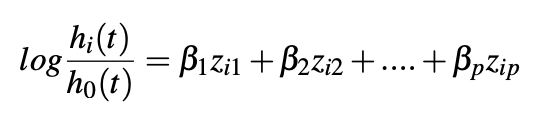
这里等式的左边是该个体存活的概率与群体存活概率的比值,右侧是 DAE 提取的特征的加权之和,通过将损失函数定义为重构误差和包含待预测指标的形式,DAE 需要学到既能够再现原始的 3D 结构,又和待预测目标有关的特征。
对于每一个待优化的权重 beta 来说,求导数后得出下面的等式:
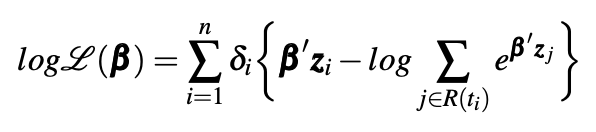
考虑到数据是不同时间段的,而一个人只会死一次,因此对不同的时间进行了加权,最终得出要优化的与死亡率有关的损失函数。
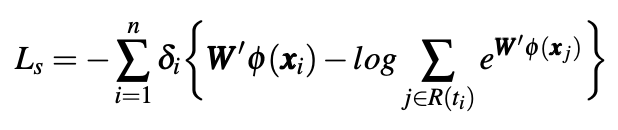
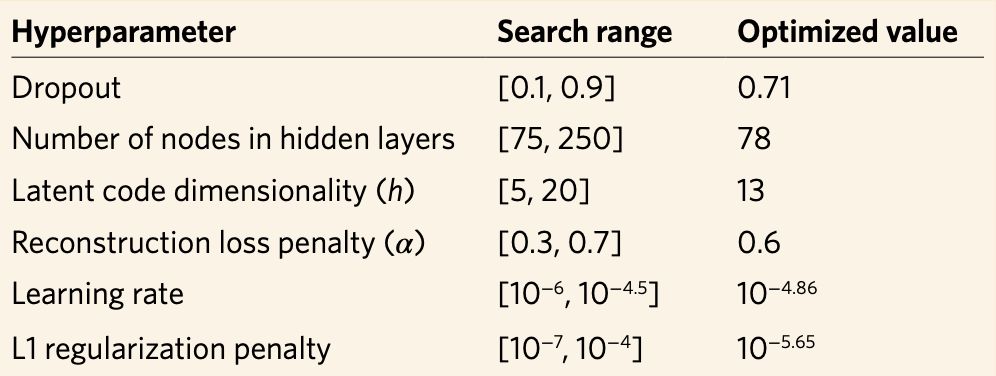
而在超参数的优化中,使用了 PSO(粒子群算法),待优化的参数如下表所列:
模型的效果
相比人工标记的数据 + 传统的预测模型,全卷积网络做的图像分割 + DAE做的预测,效果如何了?
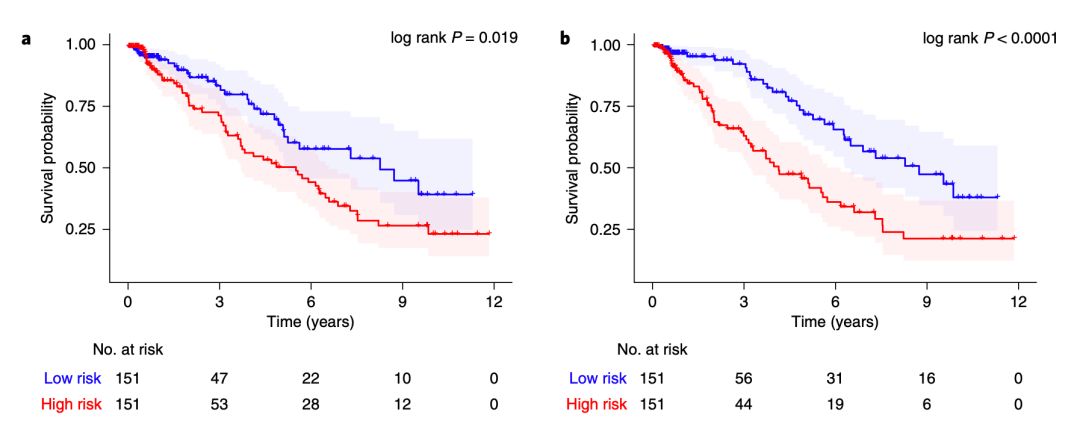
在该问题中,对每个患者的存活率的预测是一个连续值,而是否存活是一个 0 或1的问题。为此,按照预估存活率在人群的前 50% 或后 50%,将人群分成了高风险与低风险,下图的 A 是人工标记数据的模型,b 是全部用深度学习做的模型,蓝色的代表低风险,红色代表高风险,线旁边的框代表了 95% 的置信区间。
图中展示的是医学中常用的 Kaplan–Meier 曲线,反映的是病人在患病不同年份之间的死亡率,其中的 P 值代表了统计上红色和蓝色的差距。B 图相比 A 图,不止 P 值更低,而且在不同的年份间始终预测的更准,而手动的模型至少在最初几年,效果是差一些的。
模型的可解释性
医学与深度学习的结合,模型的可解释性始终会受到格外的关注。不止是由于医学样本的样本量小,人们对涉及生死的事情,需要最终能归结到生物本身的机理上。
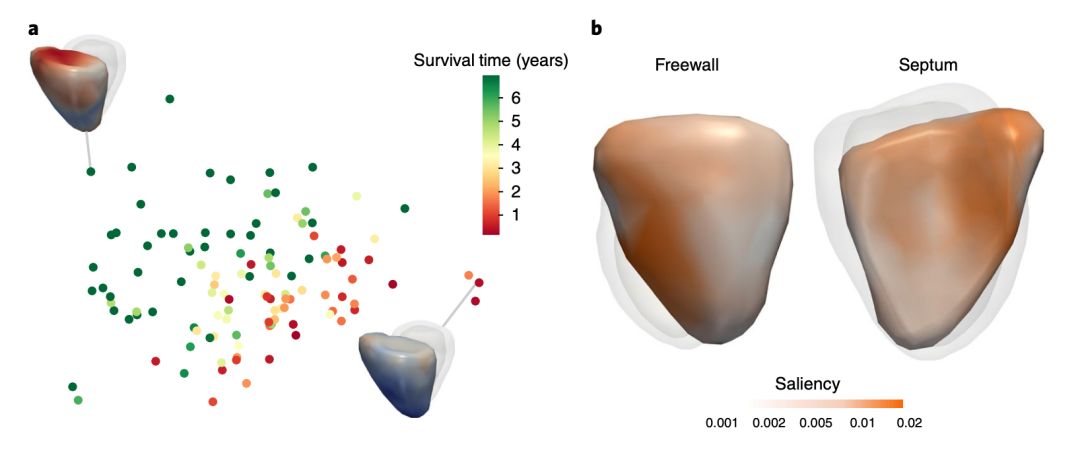
该模型对 4D 的数据用 Laplacian eigenmaps 降维到 2D 后,按照存活的年份,进行了聚类,可以看到颜色相近的点也在一起,而 b 图暂时了游离壁和间隔对模型预测的显著性,从而给出了模型的预测的可视化解释。
总结
该文的亮点在于首先做到了 4D 影像数据的全自动处理(之后的新数据不需要人工标注),以及改变自编码器的损失函数做回归问题。由于该文只用了一家医疗机构的 302 位患者的数据,因此只对该模型利用 70% 训练集,30% 验证集的方式进行了内部的调优,最后在全部 302 名患者中得出了对比图,因此该模型有过拟合的可能性。
并且该模型预测的存活率,难以指导医疗,如果能够根据更大规模的数据,结合生活习惯的问卷,预测不同的生活习惯,例如持续的运动,低盐低脂的饮食,是否对不同的人患者有不同的存活率影响,即对于坚持运动的人和不坚持运动的人(低盐低脂饮食与否),分别做一个模型来预测,再去看对于一个即不运动,也不健康的患者,上述模型能够告诉患者指导过改变那一种生活习惯,能够更好的提高自己的长期存活率,从而助力精准医学。

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐




