学界 | 谷歌联手斯坦福等高校研究电子病历,深度学习准确预测病人病程

AI 科技评论消息,谷歌在 ArXiv 上公开了一篇论文,也很可能是谷歌使用深度学习模型在电子病历建模分析方面的首篇文章。这篇论文由「编译器从不警告Jeff,Jeff 会警告编译器」的谷歌大脑高级研究员 Jeff Dean 率队,联合了 UCSF、Stanford、UChicago 等知名机构的众多大牛。
论文地址:
https://arxiv.org/pdf/1801.07860.pdf

在这篇文章里,Google 选择了 UCSF、Stanford、UChicago 作为合作单位,在两个大的医院系统——CSF 和 UChicago 的电子病历数据上,用深度学习模型预测四件事情:住院期间的死亡风险、规划之外的再住院风险、长时间的住院天数以及出院的疾病诊断。
据 AI 科技评论了解,本篇论文的作者团队背景豪华。Quoc Le 等人是深度学习界耳熟能详的人物。此外,Nigam Shah 是 Stanford 生物医学信息中心的终身教授,一直大力推动机器学习、数据挖掘技术在医学信息学中的应用。而 Atul Butte 则是医学信息学界最有影响力的学者之一,本人是 UCSF 计算健康科学中心(Institute for Computational Health Science)的首任 director,美国医学院院士。
他们总结了这篇论文得到的两个成果。首先,提出了一个通用的数据处理途径,可以将原始的EHR数据作为输入,并且在没有手动特征协调的情况下生成FHIR标准输出。这一成果使得系统可以相对容易地部署到新医院。
其次,基于两家具有普通患者群体(不局限于 ICU)的医院数据,展示了在各种预测问题和设置中使用深度学习模型的有效性。
AI 科技评论了解到,作者从 2012-2016 年的加州大学旧金山分校(UCSF)以及 2009-2016 年的芝加哥大学医学(UCM)中获取了 EHR 数据。他们把每个卫生系统称为 A 医院和 B 医院。所有电子健康记录都进行了脱敏。这两个数据集都包含患者人口统计数据、诊断记录、药物治疗、生命体征等数据。UCM 数据集(但不是 UCSF)还包含了不确定的、免费的医学注释。
此外,作者还采用了 FHIR 标准,开发了一个单独的数据结构,而不需要手动创建的数据集。AI 科技评论对该论文编译如下:
采用的三种预测模型
尽管考虑到数据的巨大潜力,但是提高预测模型的可扩展性是困难的,因为对于传统的预测建模技术来说,要预测的每一个结果都需要创建具有特定变量的自定义数据集。人们普遍认为,分析模型中80%的工作是预处理、合并、自定义和清理数据集,而不是对此进行分析,这极大地限制了预测模型的可扩展性。
我们主要采用了三种模型:LSTM、前馈神经网络和决策树。在输入模型之前,所有电子病历中的事件全都被嵌入到一个统一的低维空间中。
我们使用了两个美国学术医疗中心的 EHR 数据来验证我们的方法,其中包括住院至少24小时的216221名病例。深度学习模型对住院期间死亡风险(AUROC)、规划之外的再住院风险(AUROC 0.75-0.76)、长时间的住院天数(AUROC 0.85-0.86)和出院的疾病诊断(频率加权 AUROC 0.90)都具有较高的准确性。这些模型在所有情况下都优于最先进的传统预测模型。
事实上,常规收集的病人医疗数据还没有用于临床医生改善护理服务的预测统计模型。另一个挑战是,电子健康记录(EHR)中潜在的预测变量的数量可能会很容易地达到数千个之多。传统的建模方法仅仅通过选择非常有限的常用变量,由此产生的模型可能会产生不精确的预测:假阳性的预测可能会加重医生、护士的负担。
深度学习和人工神经网络的发展可以使我们应对这些挑战。一个关键的优点是,调查人员通常不需要指定考虑哪些潜在的预测变量,以及如何进行组合;相反,神经网络可以学习来自数据本身的关键因素和交互表示。具体来说,这种深度学习方法可以将电子健康记录(包括自由文本注释)纳入到对一系列临床问题和结果的预测中,这些问题和结果比传统的预测模型要好得多。
用 FHIR 标准对电子病历进行映射
使用计算机系统从「高度组织和记录的数据库」中学习临床数据具有悠久的历史。尽管目前 EHRs 的数据已经数字化,但最近对医学文献的系统回顾发现,用EHR数据构建的预测模型使用的变量的中位数为 27,依赖于传统的广义线性模型,并且是在单个中心使用数据构建的。在临床实践中,最常用的是更简单的模型,比如 CURB-65,这是一个 5 因素模型,或者是单参数的警告分数。
对每个患者使用更多可用数据的一个主要挑战是,来自多个站点的卫生数据缺乏标准和语义互操作性。通常为每个新的预测任务选择一组独特的变量,通常需要耗费大量劳动来提取和规范来自不同站点的数据。
重要的前期研究集中于在传统关系数据库中通过耗时的数据标准化来解决可扩展性问题,如 OHDSI 联盟定义的 OMOP 标准。这样的标准允许跨站点的预测模型的一致性开发,但是只适应原始数据的一部分。
最近,一种被称为 FHIR 的数据结构被开发出来,以一种一致的、分层的、可扩展的容器格式来表示临床数据,而不考虑卫生系统,它简化了站点之间的数据交换。然而,这种格式并不保证语义一致性,增加了处理不协调数据的额外技术需要。
通过电子健康记录和深度学习方法的发展,对电子健康记录数据的深度学习的应用迅速发展。在一项著名的研究中,研究人员使用自动编码器预测一组特定的诊断结果。随后的工作扩展了这种方法,通过对患者记录中发生的事件的时间序列进行建模,这可以提高依赖于事件顺序的场景的准确性,以及卷积和递归神经网络。
一般来说,以前的工作集中于 EHR 中可用的特性的子集,而不是在电子健康记录中所有可用的数据,包括临床自由文本注释以及大量结构化和半结构化数据。由于重症监护(模拟)数据的医疗信息市场的可用性,许多先前的研究也集中在单一中心的 ICU 患者;其他单中心研究也关注 ICU 患者。每个 ICU 患者的数据都比普通医院病人多得多,尽管非 ICU 的住院人数比 ICU 的住院人数多出 6 倍。
深度学习能够提供有效预测
我们感兴趣的是,深度学习能否在广泛的临床问题和结果中产生有效的预测。因此,我们选择了来自不同领域的结果,包括住院期间的死亡风险;规划之外的再住院风险;长时间的住院天数;出院的疾病诊断。
住院期间的死亡风险:我们预测住院病人的死亡率,定义为「过期」的出院处置。

图1:来自每个卫生系统的数据,一个合适的 FHIR 资源,并按时间顺序排列。深度学习模型可以在做出预测之前使用所有可用的数据。因此,不管任务如何,每个预测都使用相同的数据。
规划之外的再住院风险:我们预计将在 30 天内重新入院,并在出院后30天内入院。如果入院日期在出院后 30 天内,住院治疗被认为是「重新入院」。一个重新接纳的计划只能算一次。
长时间的住院天数:我们预测至少 7 天的时间,住院时间是指住院和出院之间的时间。
出院的疾病诊断:我们预测了全部的初级和二级 ICD-9 账单诊断。
我们共纳入了 216221 例住院病例,涉及 114003 例独立病人。住院死亡率为 2.3%(4930/ 216221),计划外 30 天的入院率为 12.9%(27918/216221),较长住院时间(23.9%),患者的出院诊断范围为 1 到 228 次。人口统计和利用特征见表1。为了预测住院死亡率,AUROC 在 24 小时内入院后,医院 A 为 0.95(95% CI 0.94 - -0.96),医院 B 为 0.93(95% CI 0.92 - -0.94)。这明显比传统的预测模型更准确。
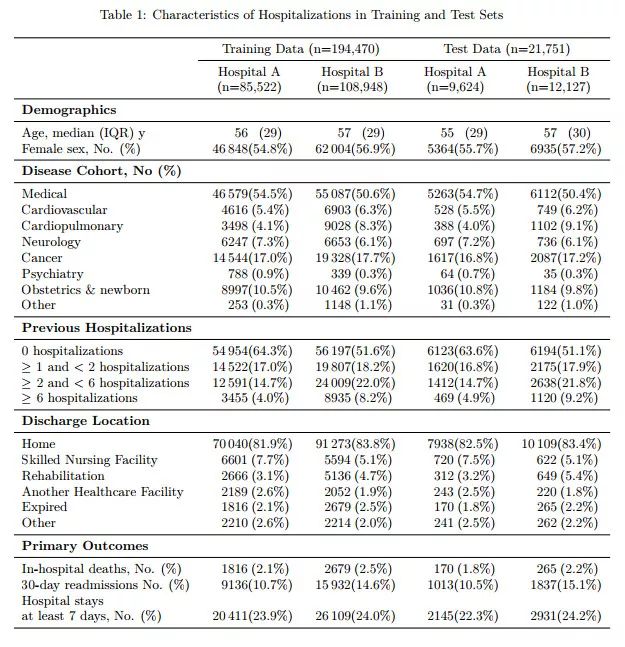
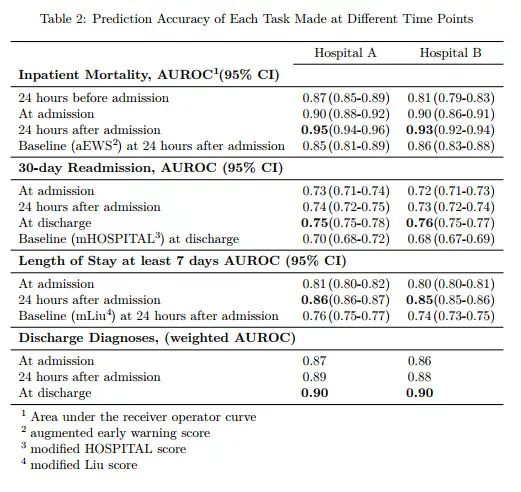
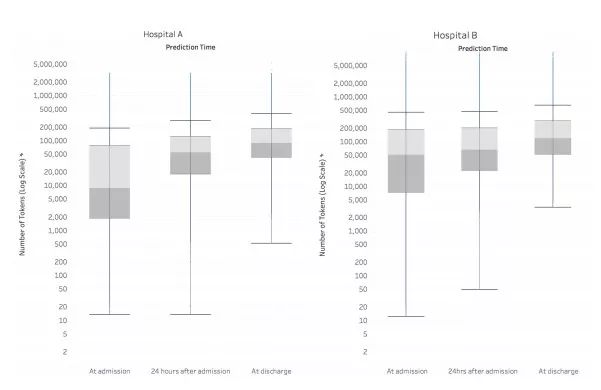
图2:箱线图显示了 EHR 中的数据量,以及它在接收过程中的时间变化。我们将一个令牌定义为电子健康记录中的单个数据元素,如药物名称,在特定时间点。每个令牌都被认为是深度学习模型的潜在预测因子。箱线图中的线表示中位数,方框表示四分位范围(IQR),须为 IQR 的 1.5 倍。令牌数量稳步增加,从入院到出院。出院时,A医院的代币数中位数为 86477,医院 B 为 122961。
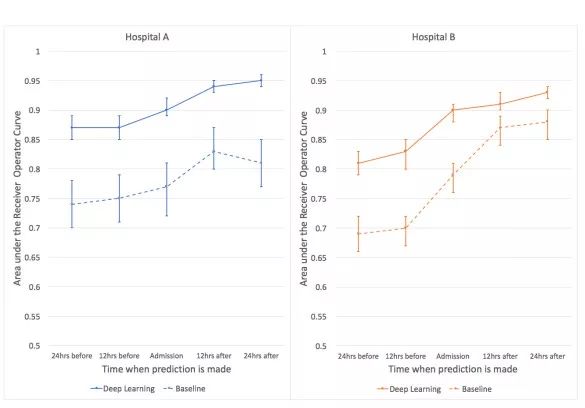
图3:接收人操作曲线下的区域显示了深度学习和基线模型在入院前和住院后 12 小时内的住院死亡率的预测。 对于住院病死率,与加利福尼亚大学旧金山分校(UCSF)和芝加哥大学医学院(UCM)分组的基线相比,深度学习模型在每个预测时间都实现了更高的识别率。 这两种模式在前 24 小时都有所改善,但深度学习模式在 UCM 提前约 24 小时达到类似的精确度,甚至提前 48 小时达到 UCSF 的水平。错误条表示引导的 95%置信区间。
先进性和局限性
我们可以总结一下,这种深度学习方法,将整个电子健康记录纳入其中,对各种临床问题和结果进行预测,结果超过了最先进的传统预测模型。
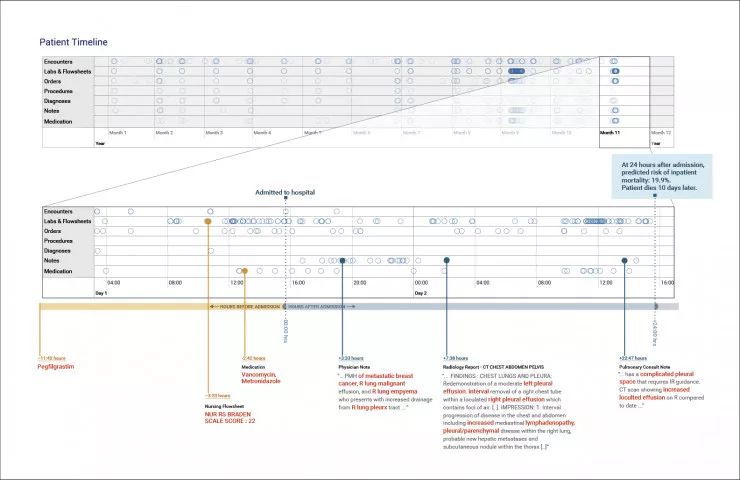
图4:患者记录显示一名患有恶性胸腔积液和脓胸的转移性乳腺癌患者。在图的顶部的病人时间线包含了每个时间步骤的圆圈,其中至少有一个标记为病人而存在,而水平线显示的是数据类型。我们训练了每种数据类型的模型,并在红色中突出显示了模型所关注的标记——非突出显示的文本没有被处理,而是显示在上下文环境中。这些模型在药物、护理流程和临床记录中提取特征来进行预测。
因为我们感兴趣的是深度学习能否在不同的医疗领域产生有效的预测,该方法在临床护理预测模型的可扩展性方面具有重要的先进性。首先,我们的研究方法是将整个 EHR 的单一数据表示作为事件序列,允许该系统用于任何可能在临床或操作上有用的预测,而无需额外的数据准备。传统的预测模型需要大量的工作来准备一个具有特定变量的数据集,由专家选择,并由分析师为每一个新的预测进行组装。这些数据的准备和清理通常消耗掉预测分析项目 80%的工作量,限制了预测模型在医疗保健行业中的可扩展性。
其次,用病人的所有预测图来做预测不仅能提高可扩展性,还能提供更多的数据来做出准确的预测。对于出院时的预测,我们的深度学习模型考虑了超过460亿份 EHR 数据,并在医院停留的时间比传统模型更准确地做出了预测。
据我们所知,我们的模型在预测死亡率(0.92-0.94 vs 0.91)上优于现有的 EHR 文献,例如评价死亡风险的 NEWS 分数,以及评价再住院风险的 HOSPITAL 分数等,作者对这些模型做了微小的改进。最终通过比较,作者的模型都显著好于这些传统模型(AUC 普遍提高 0.1 左右)。
然而,这种方法的新颖之处并不仅仅在于增量模型性能的改进。更确切地说,这种预测性能是在没有人工选择专家认为重要的变量的情况下实现的,这与深度学习对 EHR 数据的其他应用类似。相反,我们的模型可以访问每个病人的成千上万个预测因子,包括自由文本注释,并了解什么对于特定的预测是重要的。
此外,我们的研究也有重要的局限性。
第一,它是一个回顾性的研究,具有所有通常的局限性。
第二,尽管人们普遍认为准确的预测可以用于改善护理,但这并不是一个预料之中的结论,需要进行前瞻性试验来证明这一点。
第三,个性化预测的一个含义是,它们利用了许多特定 EHR 的小数据点,而不是一些常见的变量。未来的研究需要确定如何在一个站点上训练的模型能够最好地应用于另一个站点,这对于那些具有有限历史数据的站点尤其有用。作为第一步,我们证明了类似的模型架构和训练方法为两个地理上截然不同的卫生系统提供了可比较的模型,但是在这一点上还需要进一步的研究。
最后,计算资源耗费大,花费时间大于 20 万 GPU 小时。
在我们的研究中,最具挑战性的预测可能是预测病人的全部出院诊断。由于几个原因,这个预测很困难。首先,一个病人可能有1到228次出院诊断范围,而这个数字在预测的时候是不知道的。
其次,每项诊断可以从大约 14025 个 ICD-9 诊断代码中选择,这使得可能的组合总数指数级增大。最后,许多 ICD-9 编码在临床上类似,但在数字上是不同的(例如,011.30「支气管结核,未说明」与 011.31「支气管结核,细菌学或组织学检查没有完成」)。这就产生了将随机误差引入预测的效果。微 F1 评分是一个指标,当预测超过一个单一结果(例如多个诊断)时,我们的模型比在 ICU 数据集的文献中所报告的更少。这是一个概念验证,证明可以从日常的 EHR 数据中推断出诊断,这可以帮助触发决策支持或临床试验招募。
使用自由文本进行预测还可以提高预测的可解释性。 由于沟通机制的问题,临床医生历来不了解神经网络模型。 我们展示了我们的方法如何可视化模型「查看」每个病人的数据,临床医生可以使用这些数据来确定预测是否基于可信的事实,并可能有助于确定行动。
在我们的案例研究中,该模型确定了患者的历史和放射学研究结果的元素,这是至关重要的数据点,临床医生也会使用。这种方法可以解决这样的问题:这种「黑盒」方法是不可靠的。然而,对于深度学习模型的可解释性还有其他可能的技术,需要进一步研究这一方法的认知影响和它的临床效用。
————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
Fintech 年终思想盛宴
28 天『AI+金融』学习特惠
跟着民生技术总监、前瑞银大牛、四大行一线操盘手们一起充电
区块链、智能投顾、CCF ADL 智能商业课等都参与特惠
与大咖们碰撞思维
扫码或点击阅读原文了解活动详情
▼▼▼

————————————————————