百度中文依存句法分析工具DDParser重磅开源
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要4分钟
跟随小博主,每天进步一丢丢


来自:百度NLP
继百度词法分析工具LAC 2.0开源之后,8月4日,百度NLP又重磅发布了中文依存句法分析工具—DDParser!
相较于目前的其他句法分析工具,DDParser基于大规模标注数据进行模型的训练,采取了更加简单易理解的标注关系,并且支持一键安装及调用,更加适合开发者快速学习及使用。
开源地址:
https://github.com/baidu/DDParser
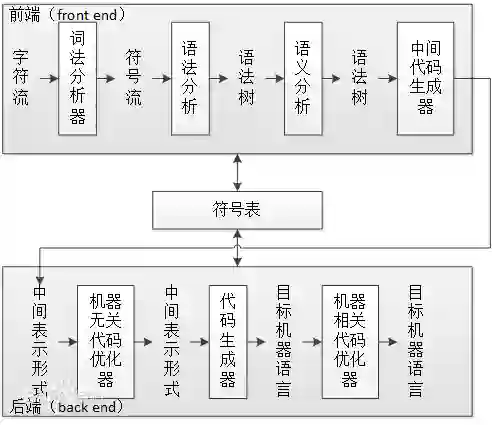
DDParser是什么
DDParser(Baidu Dependency Parser)是百度NLP基于大规模标注数据和深度学习平台飞桨研发的中文依存句法分析工具,可帮助用户直接获取输入文本中的关联词对、长距离依赖词对等。
如图1所示,输入文本通过DDParser输出其对应的句法分析树,其中,两词之间的弧表示两个词具有依赖关系,由核心词指向依存词,弧上的标签表示依存词对核心词的关系。

图1
DDParser能做什么
通过依存句法分析可直接获取输入文本中的关联词对、长距离依赖词对等,其对事件抽取、情感分析、问答等任务均有帮助。
如图1所示实例,在事件抽取任务中,我们通过依存分析结果可提取句子中所包含的各种粒度的事件,如“纳达尔击败梅德韦杰夫”、“纳达尔夺得冠军”、“纳达尔夺得2019年美网男单冠军”。
相应的,在问答任务中,我们根据问题的句法树与答案所在文本的句法树进行基于树的结构匹配,可获取对应的答案。例如,问题“谁夺得了2019年美网男单冠军”,句法树见图2,其答案所在文本的句法树见图1,我们通过两棵树的对应部分匹配,可得出答案为“纳达尔”。
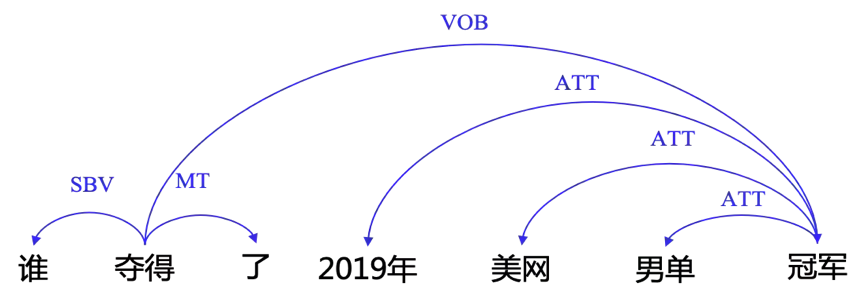
图2
在情感分析任务中,依存分析可用于评价对象的情感极性判断。如图3所示,我们根据依存分析结果提取评价对象“羊肉串”的观点:“羊肉串咸”和“羊肉串不新鲜”,基于此来判断该评价对象的情感极性。
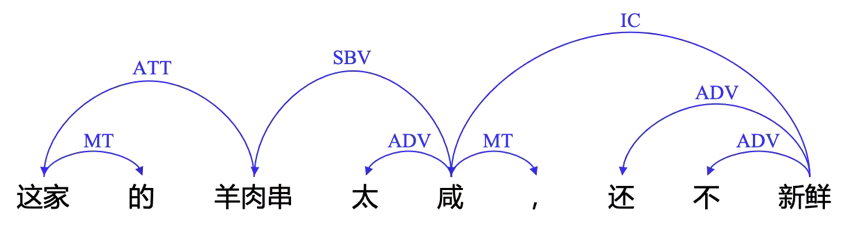
图3
利用依存分析结果可获取词之间的依赖关系和关联路径,如图4所示实例。前半句中存在两条路径“打疫苗”和“在哪儿打”,后半句中存在两条路径“打疫苗”和“打在哪儿”,这些路径信息可以给相似度计算等其他任务提供更多特征。
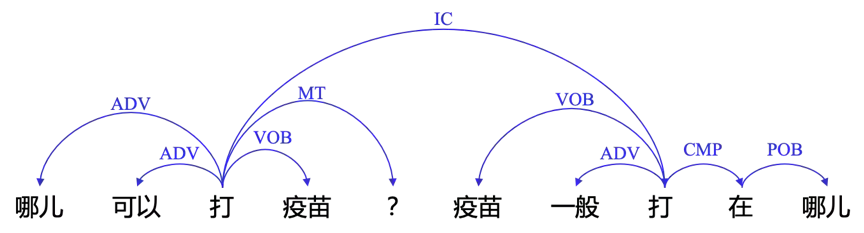
图4
总而言之,依存分析将句子表示为一棵树,提供了词之间的依赖关系和关联路径,其在句子序列基础上提供了更多的句子结构信息,可帮助其他任务从句子结构角度获取所需信息。
DDParser的优势
基于大规模优质标注数据
DDParser训练数据近百万,包含搜索query、网页文本、语音输入数据等,覆盖了新闻、论坛等多种场景。从应用的角度出发,为了方便用户快速上手,DDParser共设计了14种依存关系,并着重凸显实词间的关系,在随机数据上LAS可达到86.9%。
基于深度学习框架,不依赖繁复的特征工程
首先,DDParser采用bilinear attention mechanism对句子语义进行表示,代替复杂的特征工程模式。其次,其输入层加入了词的char级别表示,缓解粒度不同带来的效果下降,网络结构如图5所示。
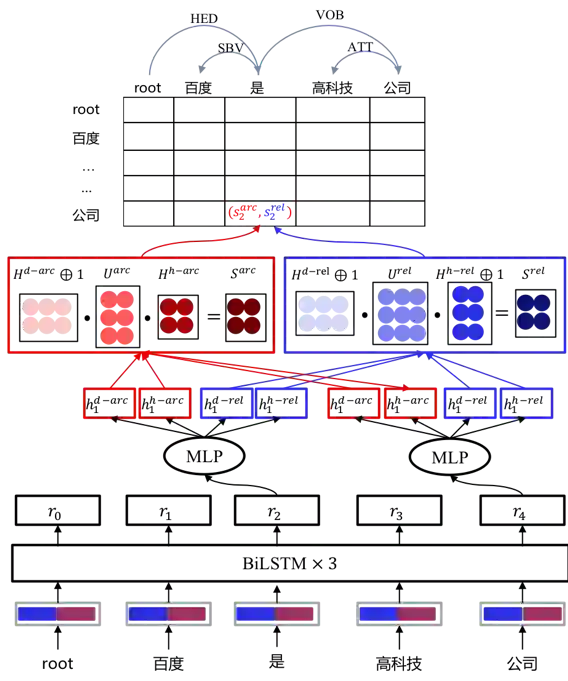
图5
调用便捷
DDParser支持Python一键安装,方便用户快速使用。
DDParser与其他开源工具的效果对比
DDParser在与训练数据同源分布的标准测试集合上,LAS达到92.9%。同时,为了验证DDParser在中文句法分析的优势,我们选择市面上关注度高的2款句法分析开源工具进行效果对比,评估方式为专家根据各工具依存关系定义人工标注。
经测试,在从搜索、聊天、网页文本、语音输入等数据集合中随机抽取构成的随机测试集合上,DDParser效果达到了86.9%,效果优于同类工具,具体效果对比情况如表1所示。
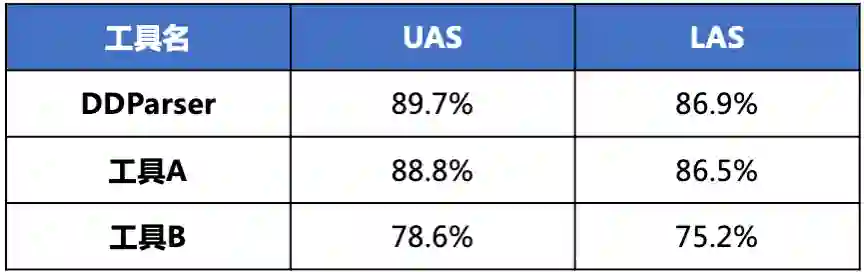
表1
DDParser如何安装使用
DDParser支持pip一键安装,兼容Windows、Linux和MacOS,调用方法如下所示:
pip install ddparser
from ddparser import DDParser
ddp = DDParser()
ddp.parse("百度是一家高科技公司")
具体安装方法参见GitHub的README文档中的快速开始。
目前,DDParser已经开源,点击“阅读原文”即可跳转GitHub开源地址了解更多技术详情,欢迎大家体验,并贡献你的star和Fork!!!
如果您有任何意见或问题都可以提issue到Github,工具开发者将及时为您解答。
DDParser项目地址:
https://github.com/baidu/DDParser
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记

整理不易,还望给个在看!