官方 | 从机器翻译到阅读理解,一文盘点PaddlePaddle九大NLP模型
本文转载自 PaddlePaddle
自然语言处理(NLP)主要是研究实现人与计算机之间用自然语言进行有效通信的各种理论和方法。基于神经网络的深度学习技术具有强大的表达能力、端到端解决问题的能力,因而在NLP任务的应用上越来越广泛和有效。
近日,百度PaddlePaddle开源了语义表示模型ERNIE,在多个中文NLP任务上表现超越了谷歌的BERT,展示了百度在NLP技术的领先能力,同时也表明PaddlePaddle作为国内目前唯一功能完备的深度学习平台,在不断得夯实框架能力, 并引领技术进步。
实际上除了ERNIE,PaddlePaddle官方还有很多其他的NLP模型,覆盖了包括语义表示、语义匹配、阅读理解、机器翻译、语言模型、情感倾向分析、词法分析等各项NLP任务。
本文将对这些模型做一些梳理和介绍。
语义表示-ERNIE
知识增强的语义表示模型 ERNIE(Enhanced Representation through kNowledge IntEgration)通过对词、实体等语义单元的掩码,使得模型学习完整概念的语义表示。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。
ERNIE 模型本身保持基于字特征输入建模,使得模型在应用时不需要依赖其他信息,具备更强的通用性和可扩展性。相对词特征输入模型,字特征可建模字的组合语义,例如建模红色,绿色,蓝色等表示颜色的词语时,通过相同字的语义组合学到词之间的语义关系。
此外,ERNIE 的训练语料引入了多源数据知识。除了百科类文章建模,还对新闻资讯类、论坛对话类数据进行学习,这里重点介绍下论坛对话建模。对于对话数据的学习是语义表示的重要途径,往往相同回复对应的 Query 语义相似。
基于该假设,ERINE 采用 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,通过该方法建模进一步提升模型语义表示能力。
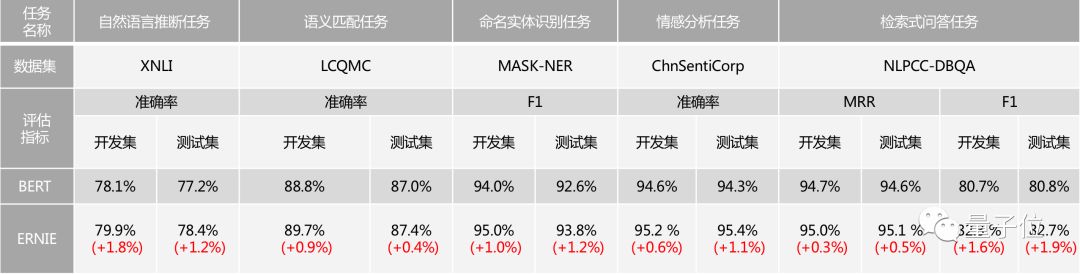
ERNIE在语言推断、语义相似度、命名实体识别、情感分析、问答匹配等自然语言处理(NLP)各类中文任务上的验证显示,模型效果全面超越 BERT,如下表所示。
项目地址:
ERNIE: https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE
语义匹配-DAM,AnyQ-SimNet
语义匹配是一种用来衡量文本相似度的NLP任务。很多NLP的任务可以转化为语义匹配问题。比如搜索可以认为是查询词与文档之间的语义匹配问题,对话系统、智能客服可以认为是问题和回答之间的语义匹配问题。
PaddlePaddle官方提供了两种语义匹配相关的模型:DAM和AnyQ-SimNet。
深度注意力匹配网络DAM(Deep Attention Matching Network)
DAM 是一个完全基于 Attention 机制的神经匹配网络。DAM 的动机是为了在多轮对话中,捕获不同颗粒度的对话元素中的语义依赖,从而更好地在多轮上下文语境中回复。它可用于检索式聊天机器人多轮对话中应答的选择。
DAM受启发于机器翻译的Transformer模型。将Transformer关键的注意力机制从两个方面进行拓展,并将其引入到一个统一的网络之中。
自注意力机制(Self-Attention)
通过从词嵌入中叠加注意力机制,逐渐捕获不同颗粒度的语义表示。这些多粒度的语义表示有助于探索上下文和回答的语义依赖。
互注意力机制(Cross-Attention)
贯穿于上下文和回答的注意力机制,可以捕获不同语段对的依赖关系,从而在多轮上下文的匹配回答中为文本关系提供互补信息。
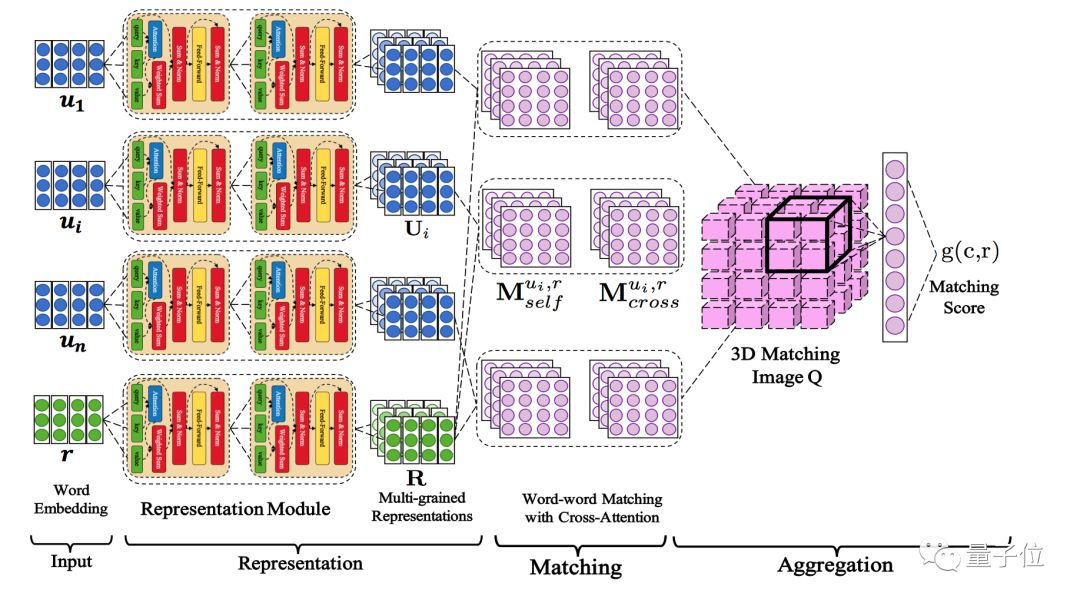
△ DAM模型网络结构
该模型在Ubuntu和豆瓣对话两个语料库上测试了多轮对话任务,如下表所示,相比其他模型有最优的效果。
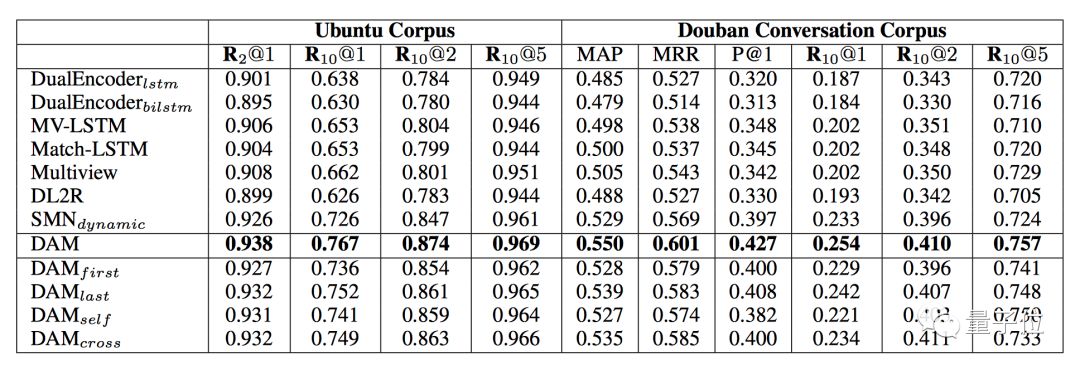
△ DAM模型的效果对比
PaddlePaddle开源的DAM项目提供了数据准备、模型训练和推理等详细的应用步骤。该项目的地址为:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleNLP/deep_attention_matching_net
SimNet
SimNet 是百度自主研发的语义匹配框架,该框架在百度内有广泛的应用,主要包括 BOW、CNN、RNN、MM-DNN 等核心网络结构形式,同时基于该框架也集成了学术界主流的语义匹配模型。使用 SimNet 构建出的模型可以便捷的加入AnyQ系统中,增强AnyQ系统的语义匹配能力。
Paddle版本Simnet提供了BOW,CNN,LSTM及GRU四种网络实现,可以通过配置文件的形式灵活选择您需要的网络,损失函数,训练方式。
PaddlePaddle官方提供了完整的数据准备、训练和推理的相关使用方法。
SimNet项目链接:
https://github.com/baidu/AnyQ/tree/master/tools/simnet/train/paddle
阅读理解-DuReader
机器阅读理解是指让机器像人类一样阅读文本,提炼文本信息并回答相关问题。对人类而言,阅读理解是获取外部知识的一项基本且重要的能力。同样,对机器而言,机器阅读理解能力也是新一代机器人应具备的基础能力。
DuReader 是一个解决阅读理解问题的端到端模型,可以根据已给的文章段落来回答问题。模型通过双向Attention 机制捕捉问题和原文之间的交互关系,生成 Query-Aware 的原文表示,最终基于 Query-Aware 的原文表示通过 Point Network 预测答案范围。
DuReader模型在最大的中文 MRC 开放数据集——百度阅读理解数据集上,达到了当前最好效果。该数据集聚焦于回答真实世界中开放问题,相比其他数据集,它的优点包括真实的问题、真实的文章、真实的回答、真实的场景和翔实的标注。
DuReader受启发于三个经典的阅读理解模型(Bi-DAF、Match-LSTM和R-NET),是一个双向多阶段模型,共有5层:
词嵌入层——用预训练词嵌入模型将每一个词映射到一个向量上
编码层——用双向LSTM网络为每一个问题和段落的位置抽取上下文信息
Attention flow层——耦合问题和上下文向量,为上下文中的每一个词生成query-aware特征向量
Fusion层——利用双向LSTM网络捕获上下文的词之间的相互信息
解码层——通过问题的attention池化的answer point网络定位答案在段落中的位置。
Paddle Github链接:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleNLP/machine_reading_comprehension
机器翻译-Transformer
Transformer 最早是谷歌提出的一种用以完成机器翻译等 Seq2Seq 学习任务的一种全新网络结构,它完全使用 Attention 机制来实现序列到序列的建模,相比于以往NLP模型里使用RNN或者编码-解码结构,具有计算复杂度小、并行度高、容易学习长程依赖等优势, 整体网络结构如图1所示。
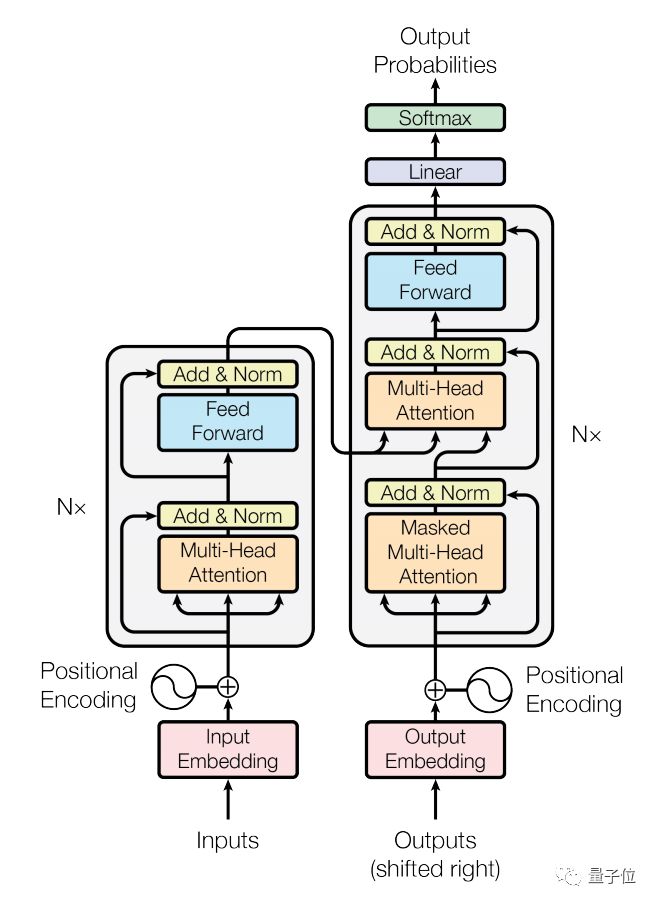
△ 图1:Transfomer模型结构
Encoder 由若干相同的 layer 堆叠组成,每个 layer 主要由多头注意力(Multi-Head Attention)和全连接的前馈(Feed-Forward)网络这两个 sub-layer 构成。
Multi-Head Attention,在这里用于实现 Self-Attention,相比于简单的 Attention 机制,其将输入进行多路线性变换后分别计算 Attention 的结果,并将所有结果拼接后再次进行线性变换作为输出。
参见图2,其中 Attention 使用的是点积(Dot-Product),并在点积后进行了 scale 的处理以避免因点积结果过大进入 softmax 的饱和区域。
Feed-Forward,网络会对序列中的每个位置进行相同的计算(Position-wise),其采用的是两次线性变换中间加以 ReLU 激活的结构。
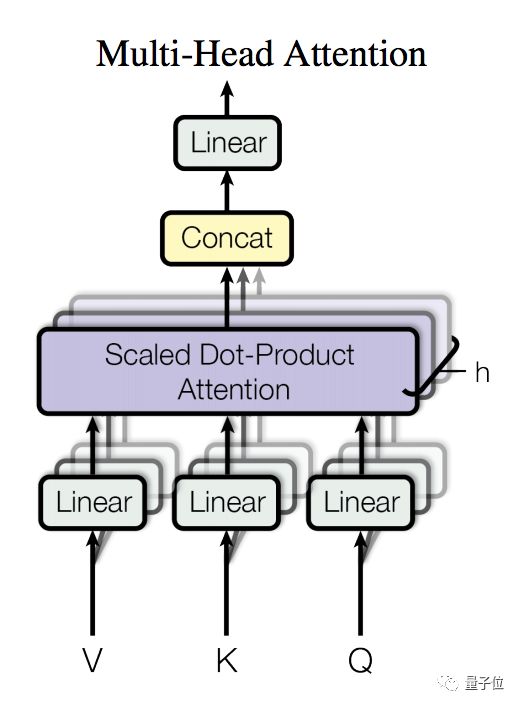
△ 图2:多头注意力(Multi-Head Attention)
此外,每个 sub-layer 后还施以 Residual Connection 和 Layer Normalization 来促进梯度传播和模型收敛。
PaddlePaddle官方提供了该模型的数据准备、训练和推理等方法。
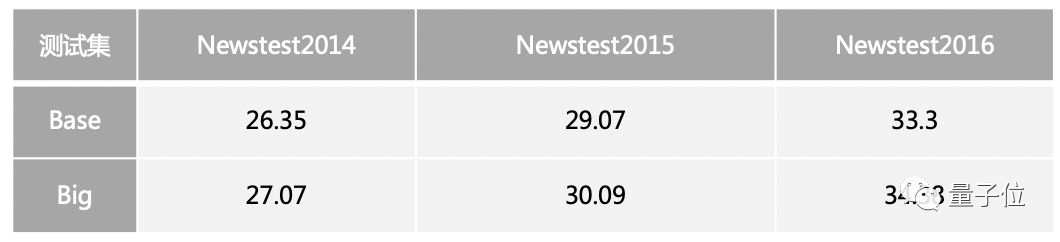
目前在未使用 model average 的情况下,英德翻译 base model 和 big model 八卡训练 100K 个 iteration 后测试 BLEU 值如下表所示:
Transformer 模型支持同步或者异步的分布式训练。Paddle官方提供了详细的配置方法。
Github项目地址:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleNLP/machine_reading_comprehension
语言模型-LSTM,GRU
RNN、LSTM和GRU是深度学习在NLP中应用的基础语言模型。
RNN模型在同一个单元中,每个时刻利用当前和之前输入,产生当前时刻的输出,能够解决一定时序的问题,但是受到短时记忆影响,很难将信息从较早的时间传到较晚的时间。LSTM通过引入门结构(forget,input,output三种门结构),能够将序列的信息一直传递下去,能够将较早的信息也引入到较晚的时间中来,从而客服短时记忆。
GRU与LSTM非常相似,但是只有两个门(update,reset),因而参数更少,结构简单,训练更简单。
Paddle提供了基于Penn Tree Bank (PTB)数据集的经典循环神经网络LSTM语言模型实现,通过学习训练数据中的序列关系,可以预测一个句子出现的的概率。
Paddle也提供了基于Penn Tree Bank (PTB)数据集的经典循环神经网络GRU语言模型实现,在LSTM模型基础上做了一些简化,保持效果基本持平的前提下,模型参数更少、速度更快。
Github链接:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleNLP/language_model/lstm
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleNLP/language_model/gru
情感倾向分析-Senta
情感倾向分析针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度。情感类型分为积极、消极、 中性。情感倾向分析能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有力的决策支持。
Senta 模型是目前最好的中文情感分析模型,可自动判断中文文本的情感极性类别并给出相应的置信度。它包含有以下模型:
Bow(Bag Of Words)模型— 是一个非序列模型。使用基本的全连接结构。
浅层CNN模型—是一个基础的序列模型,能够处理变长的序列输入,提取一个局部区域之内的特征。
单层GRU模型—序列模型,能够较好地解序列文本中长距离依赖的问题。
单层LSTM模型—序列模型,能够较好地解决序列文本中长距离依赖的问题。
双向LSTM模型—序列模型,通过采用双向LSTM结构,更好地捕获句子中的语义特征。百度AI平台上情感倾向分析模块采用此模型进行训练和预测。下图展示了这种模型的原理。
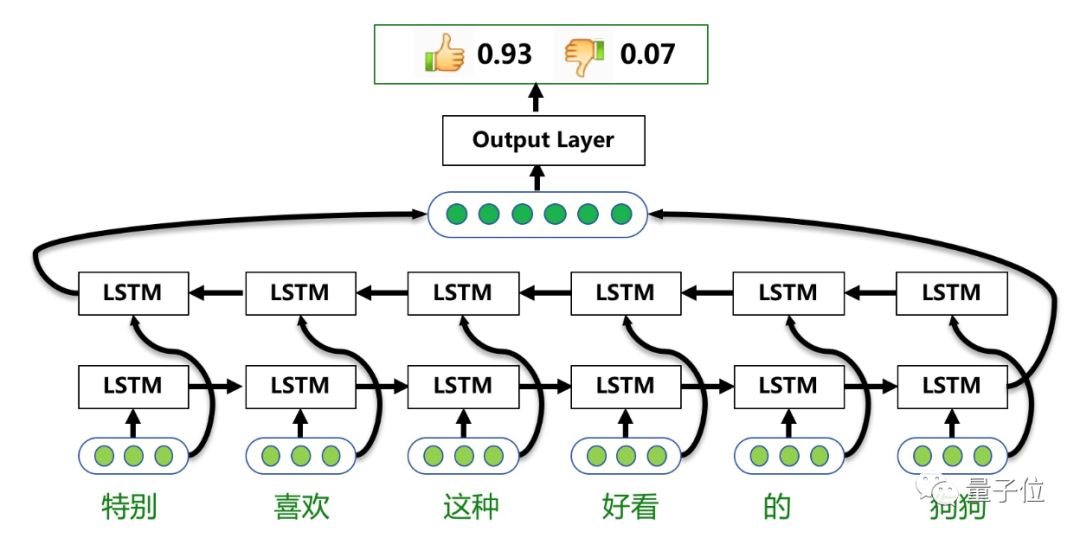
△ 基于Bi-LSTM的情感分类模型
总体来说,基于Bi-LSTM的情感分类模型包括三层:单词语义层,句子语义层,输出层。
单词语义层,主要是将输入文本中的每个单词转化为连续的语义向量表示,也就是单词的Embedding。
句子语义层,通过Bi-LSTM网络结构,将单词语义的序列转化为整个句子的语义表示。
输出层,基于句子语义计算情感倾向的概率。
在PaddlePaddle的该模型项目地址上,给出来在C-API目录下给出了bilstm_net模型的下载脚本download.sh,可供用户下载使用(模型可支持C-API、python两种预测方式),该模型在百度自建数据集上的效果分类准确率为90%。
Github项目地址:
https://github.com/baidu/Senta
中文词法分析-LAC
LAC是一个联合的词法分析模型,能够整体性地完成中文分词、词性标注、专名识别等NLP任务。LAC既可以认为是Lexical Analysis of Chinese的首字母缩写,也可以认为是LAC Analyzes Chinese的递归缩写。
中文分词 — 是将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列的过程。
词性标注(Part-of-Speech tagging 或POS tagging)— 是指为自然语言文本中的每个词汇赋予一个词性的过程。
命名实体识别(Named Entity Recognition 简称NER)— 即”专名识别”,是指识别自然语言文本中具有特定意义的实体,主要包括人名、地名、机构名、时间日期等。
LAC基于一个堆叠的双向 GRU 结构(Bi-GRU-CRF),在长文本上准确复刻了百度AI开放平台上的词法分析算法。网络结构如下图所示。
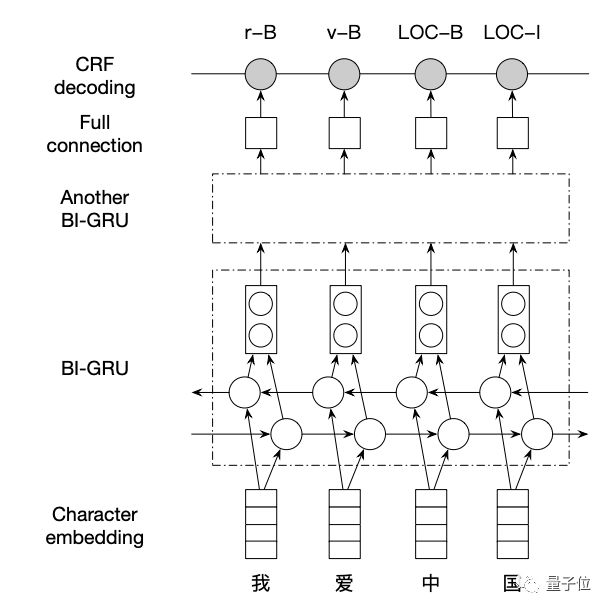
△ 用两个Bi-GRU 堆叠的Bi-GRU-CRF网络
Bi-GRU是GRU网络的一种拓展,由一个反向的GRU与一个正向的GRU耦合而成,将一个完整的句子作为。两个GRU的输入相同,但是训练方向相反。两个网络的结果拼接以后作为输出。堆叠多个Bi-GRU可以形成深度的网络,从而能够促进语义的表示能力。本模型堆叠了两层Bi-GRU。
之后,将Bi-GRU的输出连到一个全连接层。它将Bi-GRU 层的输出转为一个多维度向量,向量的维度是所有可能标签的数量。整个网络最上方,使用了CRF(条件随机场)对最后的标签做联合解码。
效果方面,分词、词性、专名识别的整体准确率95.5%;单独评估专名识别任务,F值87.1%(准确90.3,召回85.4%),总体略优于开放平台版本。在效果优化的基础上,LAC的模型简洁高效,内存开销不到100M,而速度则比百度AI开放平台提高了57%。
Github 链接:
https://github.com/baidu/lac
PaddlePaddle官方模型库Github地址
https://github.com/PaddlePaddle/models
PaddlePaddle Github项目地址:
https://github.com/PaddlePaddle
推荐阅读

喜欢就点击“在看”吧!





