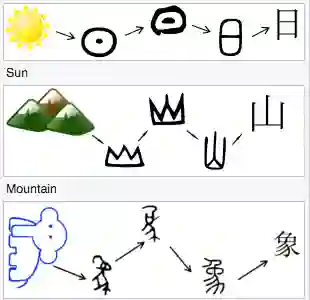
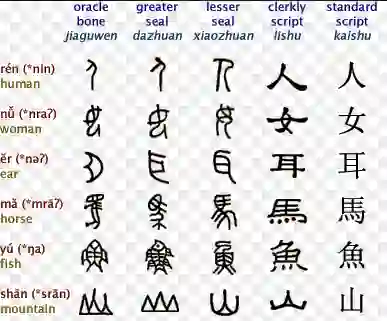
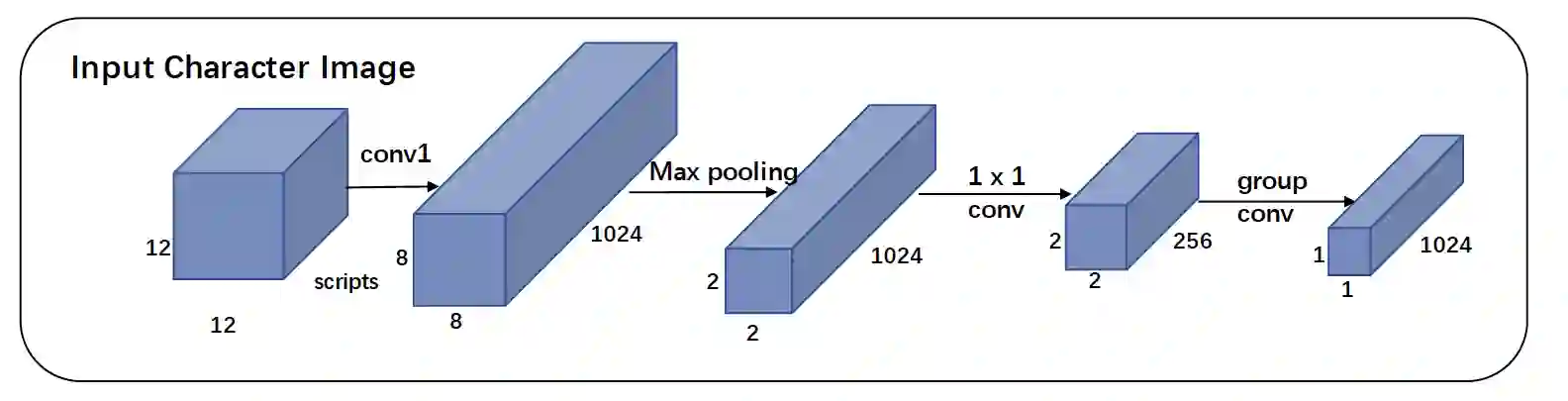
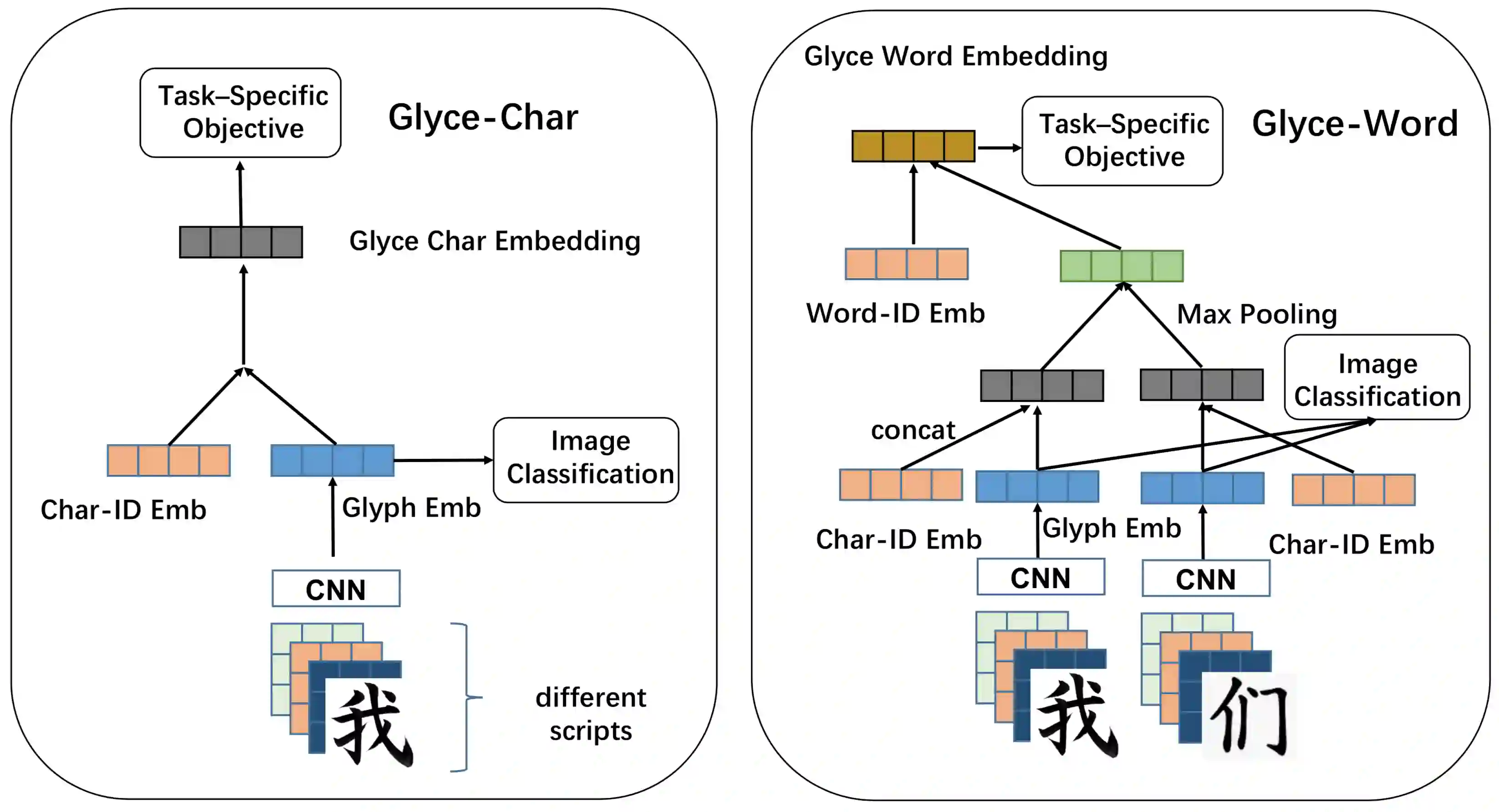
It is intuitive that NLP tasks for logographic languages like Chinese should benefit from the use of the glyph information in those languages. However, due to the lack of rich pictographic evidence in glyphs and the weak generalization ability of standard computer vision models on character data, an effective way to utilize the glyph information remains to be found. In this paper, we address this gap by presenting the Glyce, the glyph-vectors for Chinese character representations. We make three major innovations: (1) We use historical Chinese scripts (e.g., bronzeware script, seal script, traditional Chinese, etc) to enrich the pictographic evidence in characters; (2) We design CNN structures tailored to Chinese character image processing; and (3) We use image-classification as an auxiliary task in a multi-task learning setup to increase the model's ability to generalize. For the first time, we show that glyph-based models are able to consistently outperform word/char ID-based models in a wide range of Chinese NLP tasks. Using Glyce, we are able to achieve the state-of-the-art performances on 13 (almost all) Chinese NLP tasks, including (1) character-Level language modeling, (2) word-Level language modeling, (3) Chinese word segmentation, (4) name entity recognition, (5) part-of-speech tagging, (6) dependency parsing, (7) semantic role labeling, (8) sentence semantic similarity, (9) sentence intention identification, (10) Chinese-English machine translation, (11) sentiment analysis, (12) document classification and (13) discourse parsing
翻译:对于像中文这样的逻辑语言,NLP的任务应该从使用这些语言的格字信息中受益,这是直观的。然而,由于在格字中缺乏丰富的象像学证据,而且标准计算机视觉模型在字符数据方面一般化能力薄弱,因此,尚无法找到一种有效的方法来利用格字信息。在本文中,我们通过展示Glyce,即用于中文字符表达的格字数字算符来弥补这一差距。我们做了三大创新:(1)我们使用中国历史文字(例如,青铜软件脚本、海豹脚本、传统的中文等)来丰富字符的象字证据;(2)我们设计了专门为中文字符图像处理而设计的CNN结构;(3)我们在多任务学习模型中将图像分类作为辅助任务,以提高模型的比喻能力。我们第一次展示了基于格字码的模型能够在广泛的中文NLP任务中以字/字码为基础的句/字句法句模型,以及传统的中文本((4)、Sleylemental lemental ) 翻译角色分析,我们都能在13个字段上实现Syal-decial alial alial alideal alideal alial alideal alideal alideal lading。