YOLOv4团队开源最新力作!1774fps、COCO最高精度,分别适合高低端GPU的YOLO

论文链接:https://arxiv.org/2011.08036
开源代码:https://github.com/WongKinYiu/ScaledYOLOv4
-
设计了一种强有力的“网络扩展”方法用于提升小模型的性能,可以同时平衡计算复杂度与内存占用; -
设计了一种简单而有效的策略用于扩展大目标检测器; -
分析了模型扩展因子之间的相关性并基于最优划分进行模型扩展; -
通过实验证实:FPN structure is inherently a once-for-all structure -
基于前述分析设计了两种高效模型:YOLOv4-tiny与YOLOv4-Large。
模型扩展原则
模型扩展通用原则
When the scale is up/down, the lower/higher the quantitative cost we want to increase/decrease, the better. ----author
上面给出了模型扩展所需要考虑的一些因素。接下来,我们将分析几种不同的CNN模型(ResNet, ResNeXt, DarkNet)并尝试理解其相对于输入大小、层数、通道数等的定量损失。
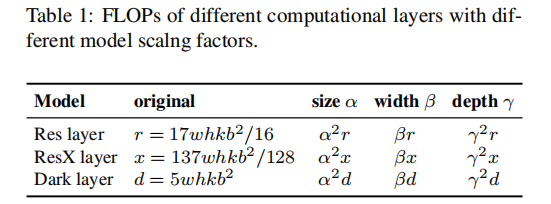
对于包含k层b个通道的CNN而言,ResNet的计算量为:
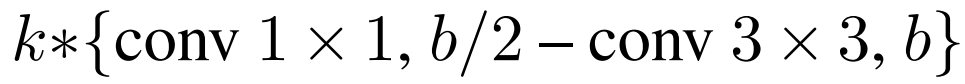 假设用于调整图像大小、层数以及通道数的因子分别为
假设用于调整图像大小、层数以及通道数的因子分别为
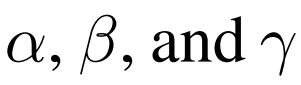 ,
其调整对应的FLOPs变化见下表,可以看到:它们与FLOPs提升的关系分别是
,
其调整对应的FLOPs变化见下表,可以看到:它们与FLOPs提升的关系分别是
square, linear, square
。

为低端设备扩展Tiny Model

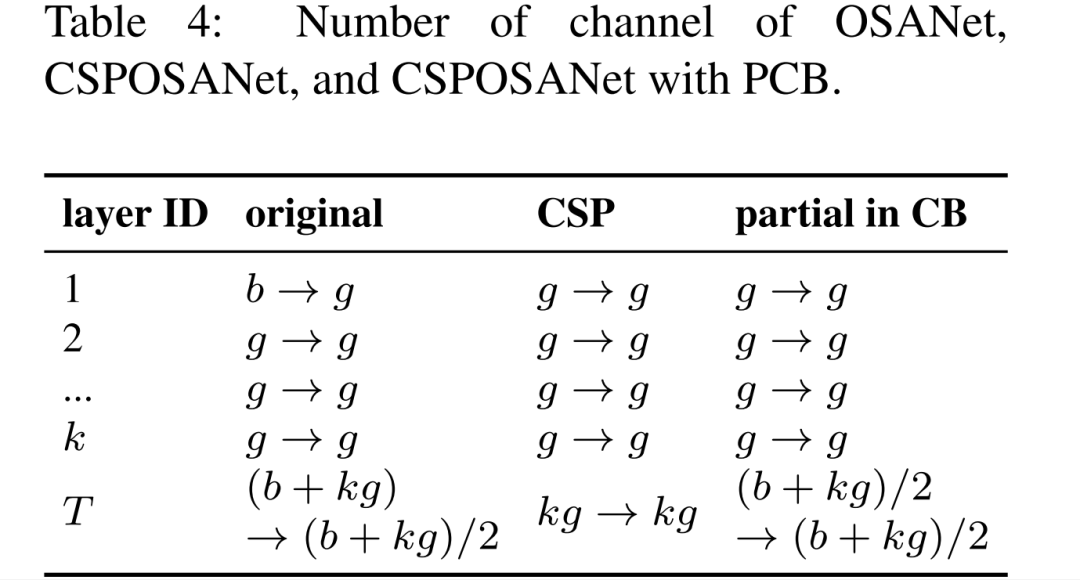
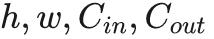 分别表示特征图的高、宽输入与输出通道数、卷积核尺寸。从上式可以得出:当
分别表示特征图的高、宽输入与输出通道数、卷积核尺寸。从上式可以得出:当
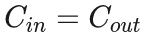 时,MAC最小。
时,MAC最小。

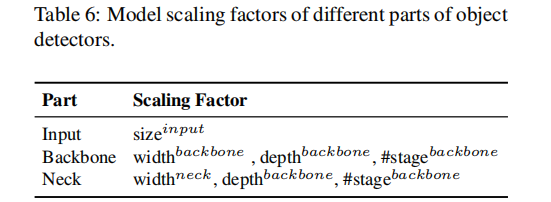
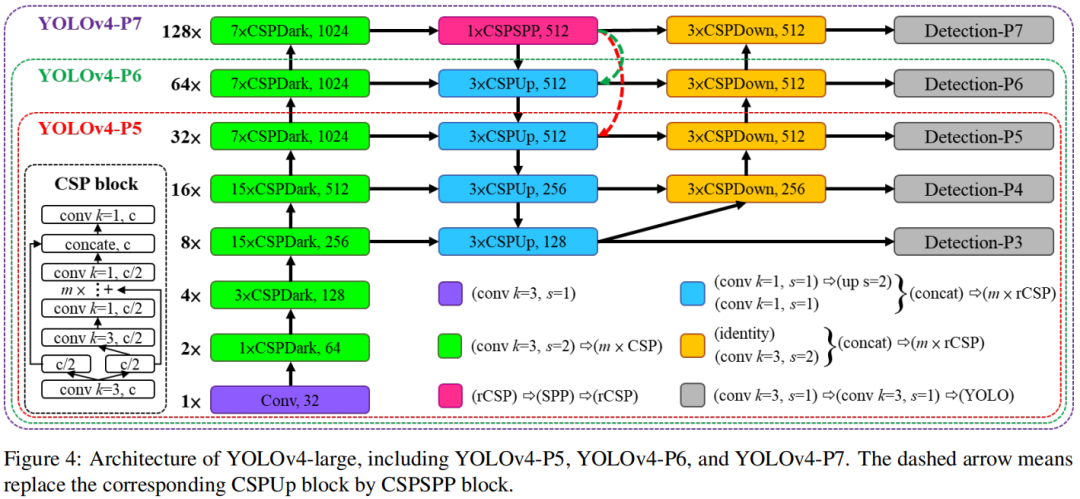
为高端GPU扩展大模型

CSP-ized YOLOv4
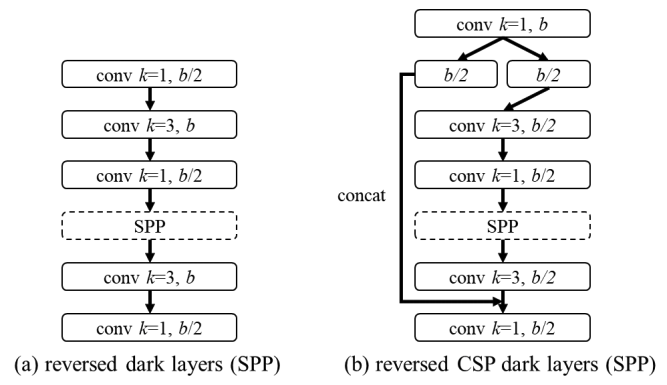
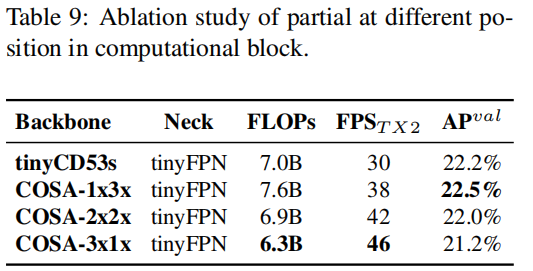
YOLOv4-tiny
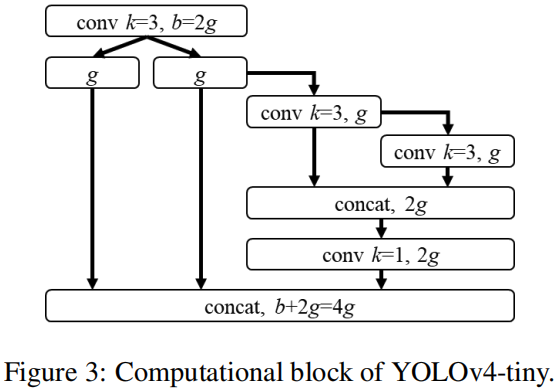
 。通过计算,作者推断得到k=3,其对应的计算单元示意图见上图。至于YOLOv4-tiny的通道数信息,作者延续了YOLOv3-tiny的设计。
。通过计算,作者推断得到k=3,其对应的计算单元示意图见上图。至于YOLOv4-tiny的通道数信息,作者延续了YOLOv3-tiny的设计。
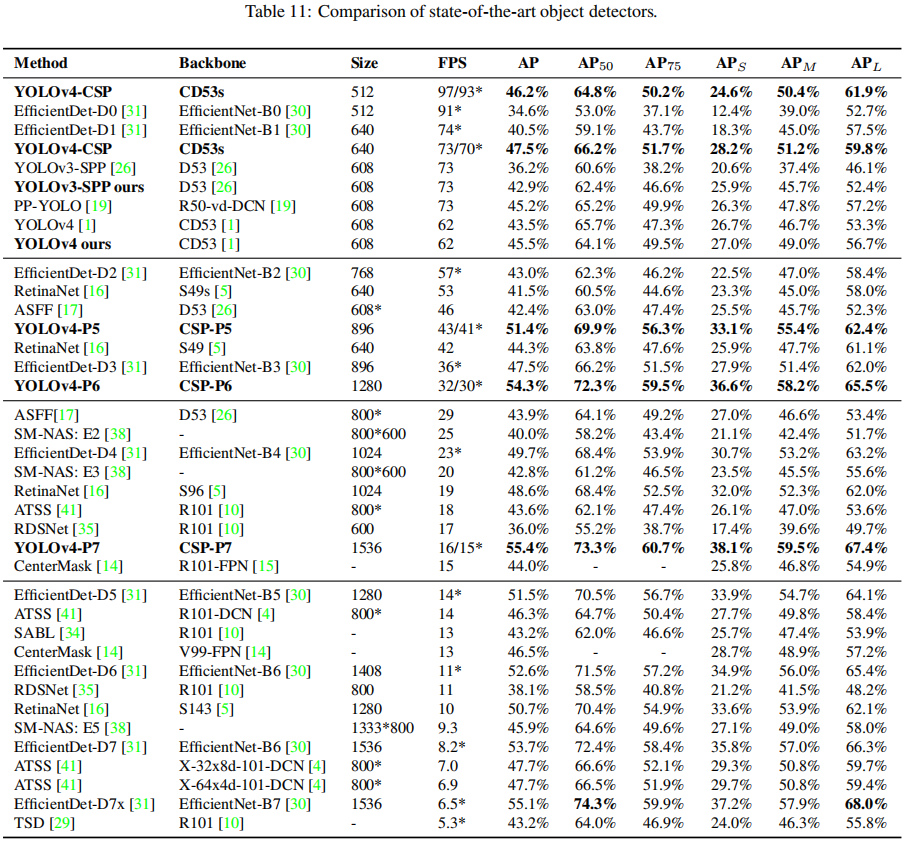
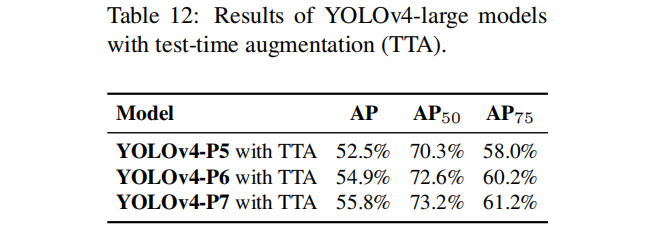
YOLOv4-large
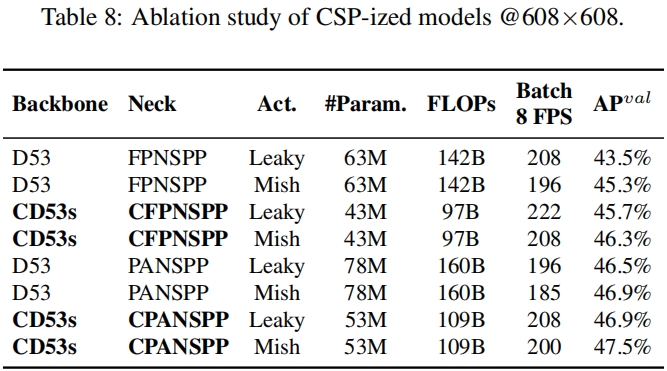
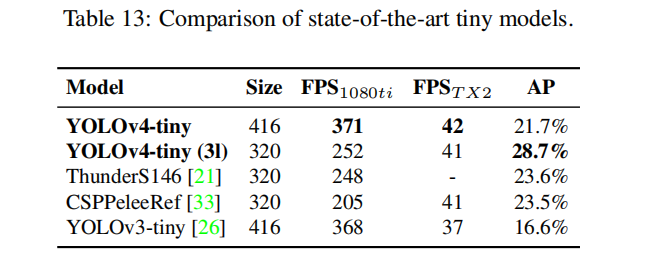
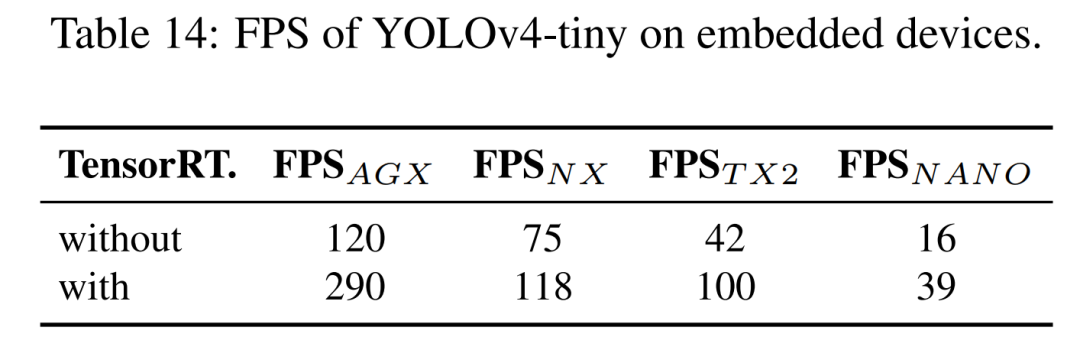
在YOLOv4-tiny上的消融研究
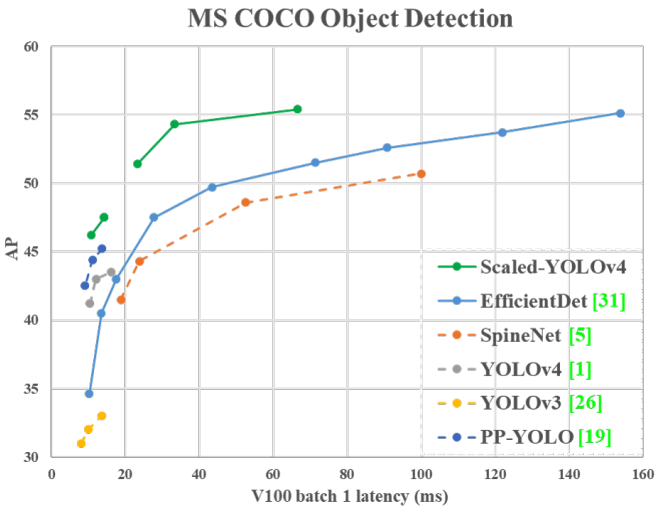
目标检测的Scaled-YOLOv4
最后附上YOLO系列相关论文:


点击阅读原文,直达EMNLP小组!
登录查看更多
相关内容
Arxiv
3+阅读 · 2019年3月20日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年3月20日