感知概率
本文节转自科学网蒋迅老师博客, 感兴趣的朋友还请 [阅读原文] 移步阅读.

谢尔曼·肯特(Sherman Kent)是耶鲁大学历史学教授。但是在二战和冷战期间,他先后在美国战略情报局和中央情报局工作,共达17年。他的工作是为美国总统提供国家情报评估(National Intelligence Estimate)。在工作中,他总结开创了许多情报分析(Intelligence analysis)的方法。他的一个重要贡献之一就是他为美国中央情报局写的“Words of Estimative Probability”。
我们平时在交谈中会使用“可能”、“很可能”、“极有可能”、“大概”、“不肯定”、“不太可能”等等不明确的词语来描述一个事件的可能性。其实我们给出的是一种没有量化的估计。我们在向上司提交报告的时候,往往也会用到这些词汇。这对上司来说就是一个麻烦,因为不同的人在说“很可能”的时候不一定是相同的意思。所以上司就无法根据我们的报告来做出决断。这对於像国家政府机构来说就是一个致命的问题。
一个解决办法就是量化这些含糊不清的用语。比如说,“可能”就意味着50%的概率,“很可能”就意味着70%的概率,而“不太可能”就是30%的概率。有人可能会认为,“很可能”应该是75%的概率。於是我们可以想像,对於每个定性的词语,它相应的的是一个区间。肯特做过一个统计调查。他将得到的数据做成了下图,并给出了他认为的每一个用词所代表的区间。显然,实际的数据距离他提议的区间还是有所不同的。
Source: Sherman Kent
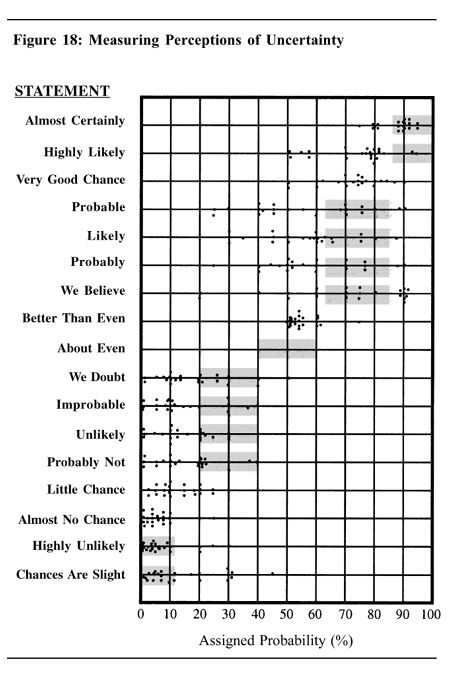
北大西洋公约组织(NATO)的23名军官们也做了一次类似的统计。下面是他们通常对相应词汇的数值化的理解。表中也包含了肯特提议的区间。似乎他们的回答比肯特找的人更加离谱。比如有5个NATO军官认为“better than even”是47-49%。不知道是否是文化上的差异或语言上的差异造成的。
Source: Critical Thinking For Strategic Intelligence

肯特的提议还有一个问题:他给出的区间似乎过於简单。比如,他把“probably”、“likely”、“probably”和“we believe”的区间都定义为同一个区间(从图片上看大约是62-85%)。一方面,这四个词的含义多少有些区分,而且一个从62%到85%的范围也不够精细。有人在reddit上重新做了一次统计(原始数据在这里:raw CSV data (numbers)),然后用R语言程序计算出每个短语的箱形图(box plot),再用ggplot2绘图包制作出漂亮的图表。对这位作者zonination的R程序感兴趣的请点击这里。
Source: KANTAR Information is Beautiful
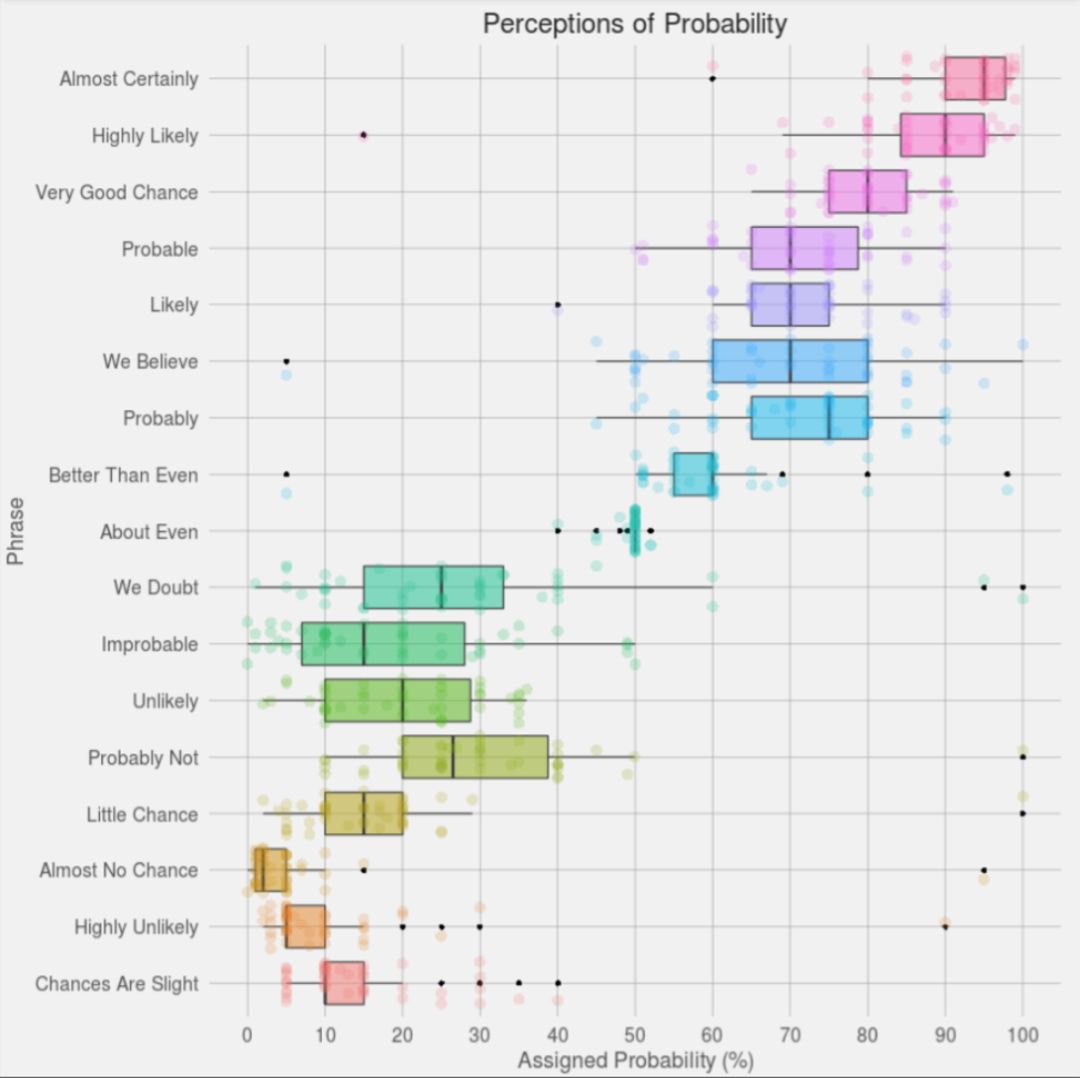
我们看到,这个图表与肯特的提议非常吻合,但是更加精确,也包含了更多的信息。箱形图给出了四分位间距,也给出了中间值的位置。离群值也都清楚地标出了。下面是对同一组数据做出的统计分布图,跟生动。我们看到意见最一致的是对“about even”的理解。我们看到的是一个方差很小的正态分布(那里的离群值让人无语)。
作者保留了全部数据,即使一些明显错误的答案也没有删除。该不该保留其实作为一个练习来说也无关紧要,但如果是提供给政府部门的报告则是一个需要考虑的问题。
Source: KANTAR Information is Beautiful
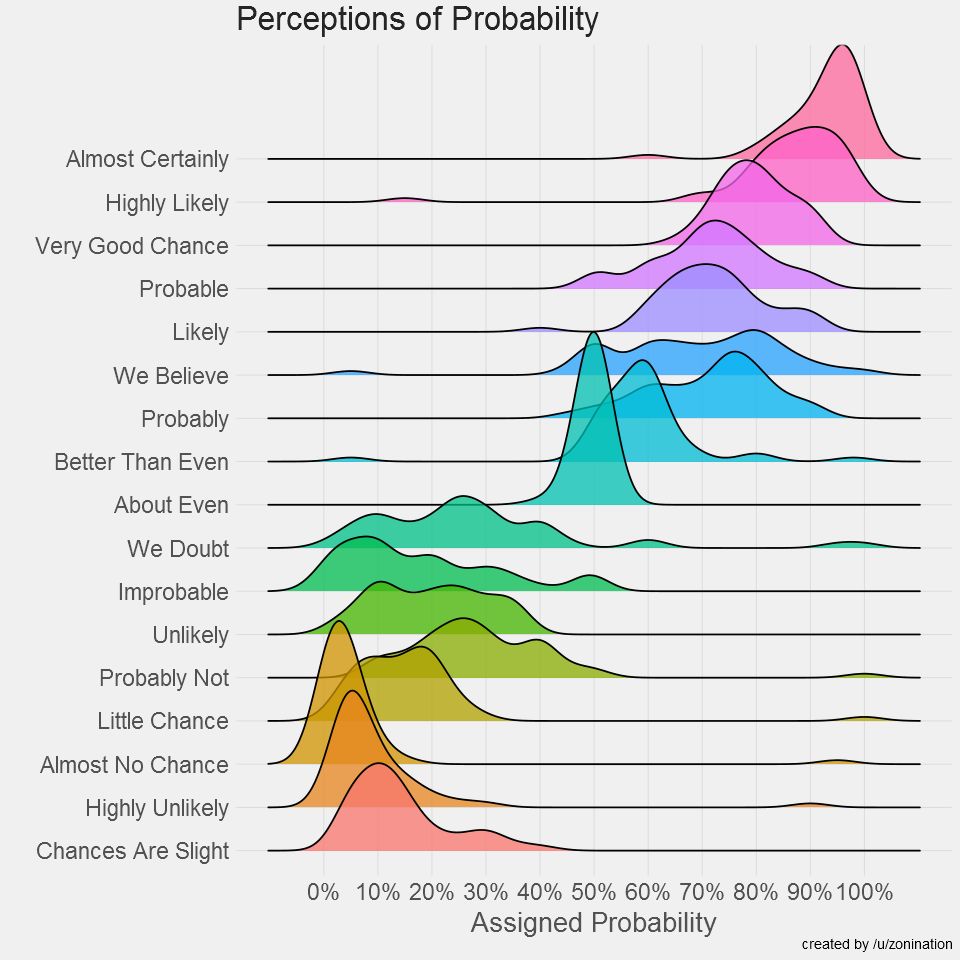
在此基础上,该作者又制作了另一组数据的感知图。如下。这里就不细说了。
Source: KANTAR Information is Beautiful
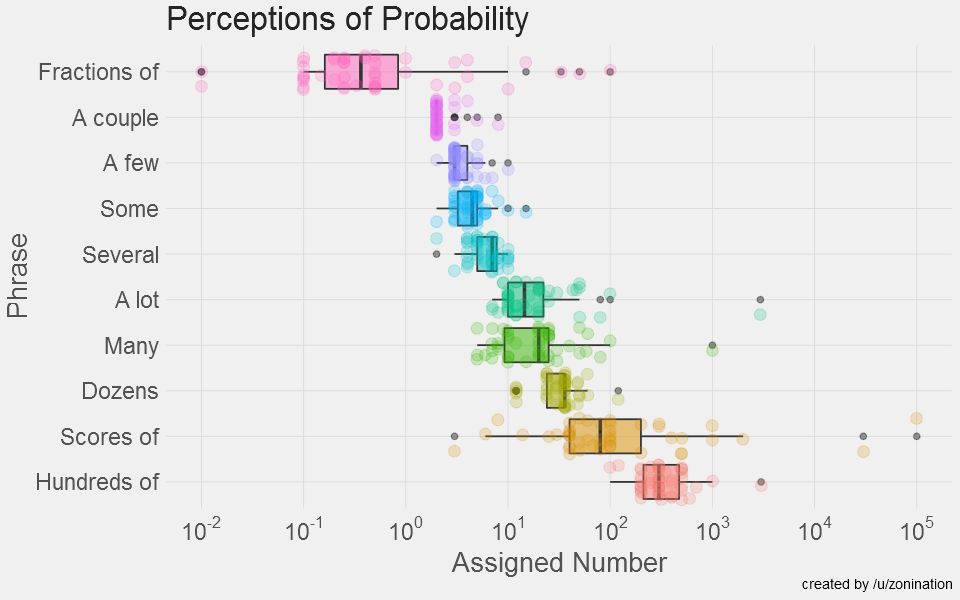
Source: KANTAR Information is Beautiful
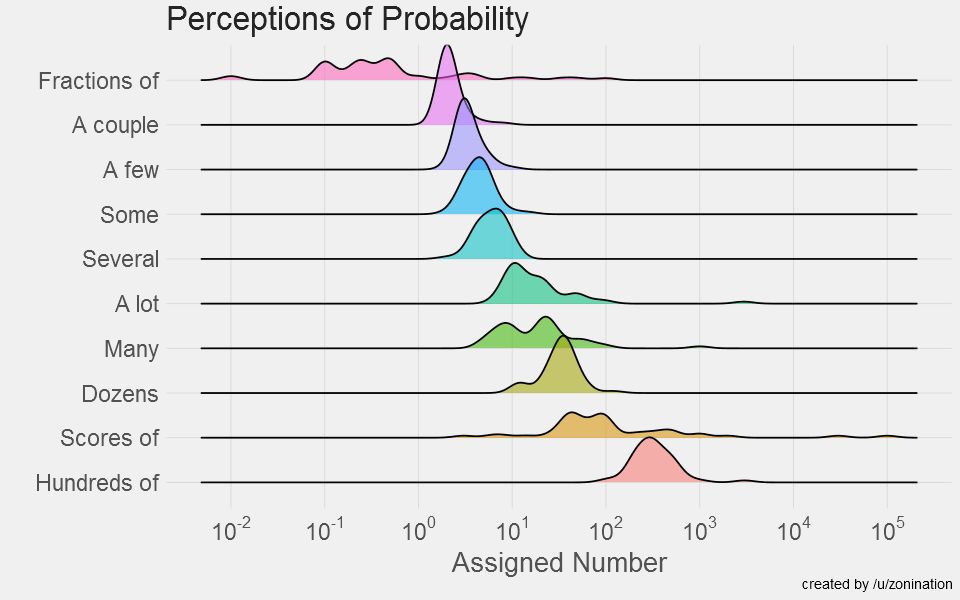
这里的感知还存在缺陷。对同一个用词,在不同的背景里可能有不同意思。在中文中完全同样的词语也有可能是不同的意思。另外,上面的作图中没有去掉明显的“outlier”,这也是值得商榷的。我们在这里仅仅是作为对数据的欣赏而展示给大家,这正如它的出处:Reddit上的“dataisbeautiful”(www.reddit.com/r/dataisbeautiful/)。如果你喜欢数据,不妨到这里寻求数据之美。(完)
「予人玫瑰, 手留余香」感谢支持!





