【观点】张军平:爱犯错的智能体 -- 视觉篇(四):看得见的斑点狗

先看张图。大家看看图1里面,有什么东西呢?一群杂乱无章的黑点块,还是其他?如果我说,里面有一条低垂着头的斑点狗,可能还有一棵长着茂密树叶的树,你都能看见吗?

图1 树旁的斑点狗
也许能,也许不能,因为不是每个人都见过斑点狗的姿态。但这只看不见的“斑点狗”却引出了一个人工智能的话题,一个关于“机器”图像分割和“心理”图像分割的话题,一个客观与主观图像分割的话题。
图像分割,简而言之,就是把图像中的(多个)目标和背景分离开来。它是计算机视觉和图像处理领域的经典研究方向,但至今仍未得到圆满解决。对于人工智能而言,它也是重要的基石。因为它的性能优劣决定了多数人工智能应用的有效性。比如智能驾驶,人、车、交通标志、路面、建筑物如果不能有效从监控的视频中进行准确分离,那么智能驾驶就无法实用。比如视频摘要和图像理解,如果不能把图像或视频中的目标及目标关系提取出来,也会碰到类似的问题。再比如智能服务机器人,如果不能将待服务的主人或顾客从视频中识别出来,那也就无法提供有效的服务。
不管用何种方法提取目标或背景,有标签的监督学习、或无标签的非监督学习也好,基于每个目标或类别中心的方法也好,把图像看成节点和连接边组成的图模型的方法也好,基于类似新华字典的视觉词包(Bag of visual words)方法也好,基于深度学习的图像分割也好,对目标的结构假设基本上是一致的。一般都假设了目标内部是同质地的、空洞是比较少的,目标与背景之间的边界是明显的、少锯齿状、尽量光滑的。图2就是一个标准的图像分割示例。

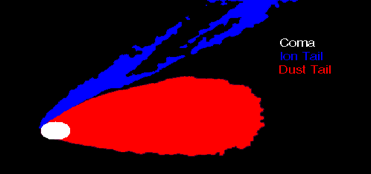
图2 左图:彗星;右图:经过图像分割后的慧星,白色:慧核;蓝色:离子慧尾;红色:尘埃慧尾
另外,衡量图像分割质量优劣,有两类标准。要么是人为先把真正的分割结果标记好,再通过图像相似性或信噪比指数来客观评判;要么是视觉上根据个人经验做主观分析和比较。前者与人感知的图像分割存在一定偏差,有偏好选择定量好但视觉效果差的图像分割结果的风险;后者则容易陷入“公说公有理、婆说婆有理”的尴尬局面,让人对图像分割质量的好坏没什么底。因为有可能某些图的分割效果好,但某些图效果又很不好,难以验证其可推广性。
除此以外,图像分割还具有多义性。如图3中花瓶与人、ABC和12, 13, 14中的B与13、人脸正面和侧面的图。这些图都反映了主观意识和上下文在图像分割中的重要性,也表明了图像分割并非像字面意义那么简单好处理。

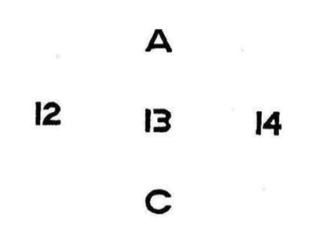

图3:左:花瓶与人;中:13与B; 右:正脸/侧脸?
至于看不见的斑点狗,它涉及到另一层的“图像分割”---- 主观意识下的图像分割和目标提取。图像中本没有显明的斑点狗,可是当给予线索暗示后,人会根据提示,从自己先前的知识中,合成潜在的目标形状,并在图像中进行匹配、分割和形成最接近的目标结构。
为什么会有这样的情况出现呢?心理学中,有个叫格式塔(Gestalt)心理学的流派分析过这一现象,并将其归结为涌现(Emergence)。
在其框架下,感知到一只达尔马提亚狗(俗称斑点狗)正在茂盛的树下嗅着地面的过程称为涌现。但与常规的图像分割不同,人在辨识这只狗时,并不是通过先找到它的每个局部结构如腿、耳朵、鼻子、尾巴等,再将其拼成整体来推断狗的;而是将那些与斑点狗相关的黑点作为一个整体、一次性的感知成狗。然而,格式塔心理学也只是描述了这一现象,并没有解释这个涌现是如何在大脑中形成的。
有种解释是,人会根据自己习得的经验来分析图像,并尽可能与自己的经验去匹配。数学上,称这种经验为先验知识。尤其是当遇到毫无线索的图像时,人会优先根据先验知识或暗示来寻找最可能的答案。于是,你便可以从图1中看到一只“斑点狗”了。
根据先验知识或经验来形成对图像内容和自然界的景色进行想象和判断的例子不在少数。比如图4中的平远南台的卧佛山、桂林漓江的九马画山、甚至月球上的疑似外星人飞船等。



图4:左:平远南台卧佛;中:桂林九马画山;右:月球上的疑似飞船
但这种整体结构的形成又恰恰是“客观”图像分割很少能做到的。首先,人感知到的“斑点狗”并不符合图像分割的客观定义,如同质性、少洞性、边界光滑性和差异性。斑点狗与背景几乎是相同纹理的,斑点狗内部和外部的差异极小,边界也不清晰,甚至人也很难把其边界唯一的勾勒出来 。其次,图像匹配的相似度也不高,因为只是形似,并非百分之九十的精确相似。在计算机视觉中,有可能第一时间就被判断成异常点或因为低于阈值而被排队。即使是将其视为认证任务(即:非此即彼)而非分类任务,识别算法也不见得能有多高的准确定位能力。第三,他能形成的联想会超出图像分割本身的范畴。图像分割的目的是纯粹的。而联想却是基于每个人长年耳濡目染构建的知识库。所以,才会“看到”图上的飞船,由其比例大小才会猜测非人力可为,进而联想到外星文明等。
这种上下文的联系表达,尽管已经有一些看图说话(image captioning)的研究成果,但目前的结果,从人工智能和计算机视觉角度来看,都还没法与人类抗衡。因为,他需要的知识库更为庞大,如果只靠枚举,很容易出现曾经流行的专家系统中的组合爆炸问题。
除了人的先验知识能影响对图像中目标的判断外,还有一个更为简单的因素,却能严重影响人对目标的判断,下回书表。
参考文献:
1. Wikipedia. Gestalt Psychology. Retrieved from http://en.wikipedia.org/wiki/Gestalt_psychology. Last accessed on February 18th 2007.
2. Carlos Pedroza, Visual Perception: Gestalt Laws, College of Education, San Diego State University. Retrieved at April 8, 2007.
来源:科学网张军平教授博客

中国认知计算与混合智能学术大会报名通道已开启,欢迎广大国内外学者及相关领域各界人士参会,期待您的到来。
往期文章推荐

🔗【CCHI2018】大会专题论坛二之混合增强智能与深度学习最新日程新鲜出炉!
🔗【重要通知】2018新一代人工智能高峰论坛将于8月23日在福建漳州举办
🔗【学会新闻】智能科技高等教育与智能产业研讨会 在澳门科技大学成功召开
🔗【通知】2018全国第二十三届 自动化应用技术学术交流会会议通知
🔗【CAC2018】中国自动化大会截稿时间变更至8月30日的通知
🔗【征文】首届ABB杯全国智能技术大赛征文中, 丰厚的奖励等你拿!
🔗【学会新闻】第六期智能自动化学科前沿讲习班在湖北武汉成功召开





