CCCF专栏:李航 | 人工智能的未来 ——记忆、知识、语言
点击上方“中国计算机学会”轻松订阅!
来源:《中国计算机学会通讯》2018年第3期《专栏》

从一个悲剧故事谈起
黛博拉(Deborah)轻轻地推开房门,探头往里看。克莱夫(Clive)发现进来的是妻子,脸上露出无限的喜悦。他直奔门前,高喊“太好了”,并张开双臂紧紧地抱住黛博拉。克莱夫一边和黛博拉亲吻,一边说“你来了,真让我吃惊”。接着两人又开始拥抱,好像分别已久。坐下来后,黛博拉用温柔的眼光看着克莱夫说“其实我今天早上也来过”,克莱夫摇摇头反驳道“不可能,这是我今天第一次见到你。”这样的场景每天都在黛博拉和克莱夫之间重复上演。
克莱夫·韦尔林(Clive Wearing)是英国的一位音乐家¹ 。他四十多岁的时候突然患上了病毒性脑炎,这是一种死亡率很高的疾病。幸运的是他活了下来,不幸的是疾病给他留下了失忆症(amnesia)。过去发生的很多事情已不能记起,但他还认识妻子,却不认识女儿。更严重的是他对当前发生的事情不能记忆到脑子里,几分钟后就会完全忘记。他的行动没有任何问题,语言和思维似乎也正常,可以饮食、行走、说话、写字,甚至弹琴、唱歌,看上去和正常人一样。但他就是长期记忆(long term memory)出了问题。他感受到的世界和大家是一样的,但转过头去,刚发生的一切就会从脑海中消失,他所拥有的只是“瞬间到瞬间的意识”,没有过去可以联系,也没有未来可以展望。
克莱夫·韦尔林用自己不幸的经历为我们揭示了长期记忆对我们的智能,乃至我们的人生的重要意义。
记忆与智能
人脑的记忆模型如图1所示,由中央处理器、寄存器、短期记忆和长期记忆组成。视觉、听觉等传感器从外界得到输入,存放到寄存器中,在寄存器停留1~5秒。如果人的注意力关注这些内容,就会将它们转移到短期记忆,在短期记忆停留30秒左右。如果人有意将这些内容记住,就会将它们转移到长期记忆,半永久地留存在长期记忆里。人们需要这些内容的时候,就从长期记忆中进行检索,并将它们转移到短期记忆,进行处理[1]。
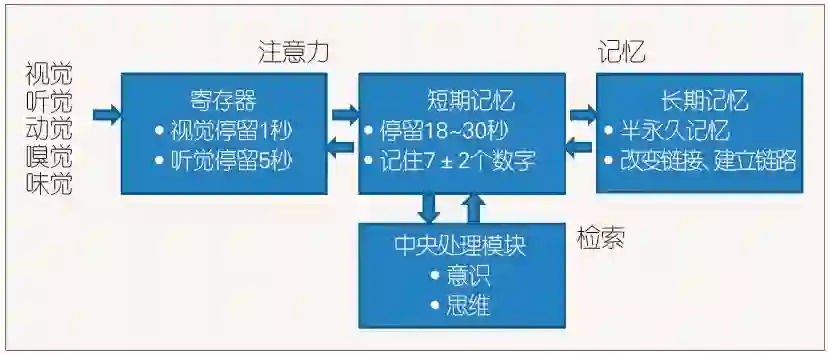
图1 人脑记忆模型
长期记忆的内容既有信息,也有知识。简单地说,信息表示的是世界的事实,知识表示的是人们对世界的理解,两者之间并不一定有明确的界线。人在长期记忆里存储信息和知识时,新的内容和已有的内容联系到一起,规模不断增大,这就是长期记忆的特点。
大脑中,负责向长期记忆读写的是边缘系统中的海马体(hippocampus)。克莱夫·韦尔林患失忆症,是因为海马体受到了损伤。长期记忆实际上存在于大脑皮层(cerebral cortex)。在大脑皮层,记忆意味着改变脑细胞之间的链接,构建新的链路,形成新的网络模式。
我们可以认为,现在的人工智能系统是没有长期记忆的。无论是阿尔法狗,还是自动驾驶汽车,都是重复使用已经学习好的模型或者已经被人工定义好的模型,不具备不断获取信息和知识,并把新的信息与知识加入到系统中的机制。假设人工智能系统也有意识的话,那么其所感受到的世界和克莱夫·韦尔林是一样的,那就是,只有瞬间到瞬间的意识。
那么,意识是什么?这是当今科学的最大疑团之一,众说纷纭,莫衷一是。日裔美国物理学家加莱道雄 (Michio Kaku)给出了他的定义。如果一个系统与外部环境(包括生物、非生物、空间、时间)互动过程中,其内部状态随着环境的变化而变化,那么这个系统就拥有“意识”[2]。按照这个定义,温度计、花儿是有意识的系统,人工智能系统也是有意识的。拥有意识的当前的人工系智能系统缺少的是长期记忆。
具有长期记忆将使人工智能系统演进到一个更高的阶段。这应该是人工智能今后发展的方向。
智能问答系统
未来人工智能技术不断发展,预计将会出现智能性的问答系统,系统包括语言处理模块、短期记忆、长期记忆、中央处理模块(如图2所示)。有大量的结构化的、非结构化的信息和知识作为输入,也有大量的问答语对作为训练数据。系统能够自动获取信息与知识,掌握语言理解与生成能力,将信息和知识处理存储到长期记忆,理解用户用自然语言提的问题,利用记忆的信息与知识给出正确的答案。
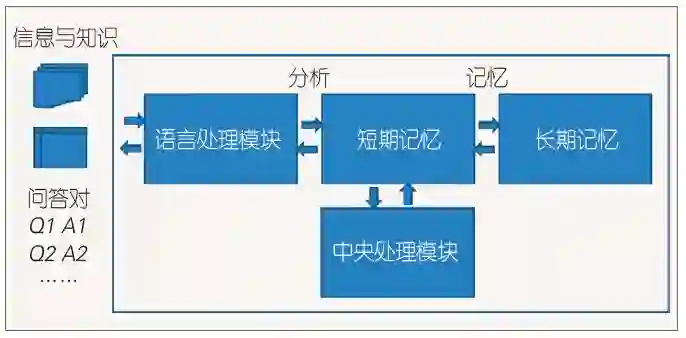
图2 智能问答系统
在某种意义上,现在已经存在这种系统的原型,例如,互联网搜索引擎就可以看作是其简化版。但是要真正构建人类的智能信息助手,还有许多难关要攻克,有许多课题要解决。
知识问答的本质问题是:(1)语义分析,即将输入的自然语言的表示映射到内部的语义表示;(2)知识表示,即将输入的信息知识转换为内部的语义表示。最大的挑战来自语言的多义性和多样性,以及知识的模糊性。
语言具有多义性(ambiguity),也就是说一个表达可以表示不同的意思。下面是语言学家查尔斯·菲尔默(Charles Fillmore)给出的例子。英语单词climb,其基本语义是四肢用力沿着一条轨迹向上移动,表示“向上爬”的意思。所以如果用climb造句,大家一般会给出这样的句子“The boy climbed the tree”(男孩爬上了树)。但是climb一词的语义会向不同方向扩展,可以说“Prices are climbing day by day”(物价每日飙升),这里climb就没有了四肢用力移动的意思。也可以说“He climbed out of a sleeping bag”(他从睡袋中爬出),这里climb就没有了向上移动的意思。语言的词汇都具有如下性质:有一个核心的语义,对应一些典型说法,可以由一些特征表示。但部分特征可以缺失,形成新的语义,产生新的说法。语言中,除了词汇的多义性,还有句法的多义性。
同时语言也具有多样性(variability),也就是说多个表达可以表示同一个意思。比如,“地球和太阳的距离”,“地球离太阳有多远?”,“太阳和地球相隔有多少公里?”等,都是同义表达。
人们的知识,特别是常识,具有模糊性(fuzziness)。下面是人工智能研究的先驱者特里·维诺格拉特(Terry Winograd)给出的例子。英文中,bachelor是指未婚成年男性,即单身的意思。看似是一个明确的概念,但是当我们判断现实中的具体情况时,就会发现我们对这个概念的认识是模糊的,比如,未婚父亲是否是bachelor?假结婚的男子是否是bachelor?过着花花公子生活的高中生是否是bachelor?大家并没有一致的意见。
神经符号处理
近年,深度学习给自然语言处理带来了巨大变化,使机器翻译、对话等任务的性能有了大幅度的提升,成为领域的核心技术。但是另一方面,深度学习用于自然语言处理的局限也显现出来。面向未来,深度学习(神经处理)与传统符号处理的结合应该成为一个重要发展方向,神经符号处理(neural symbolic processing)的新范式被越来越多的人所接受,其研究也取得初步进展。
图 3 基于神经符号处理的智能问答系统
深度学习用实数向量来表示语言,包括单词、句子、文章,向量表示又称为神经表示(neural representation)。神经表示的优点在于其稳健性,可以更好地应对语言的多义性和多样性,以及语言数据中的噪音。另一方面,传统的符号表示(symbolic representation)的优点在于其可读性和可操作性。语言是基于符号的,计算机擅长的是符号处理,用符号表示语言处理的结果是自然的选择。神经符号处理旨在同时使用神经表示与符号表示来描述语言的语义,发挥两者的优势,更好地进行自然语言处理。
基于神经符号处理的智能问答系统也是由语言处理模块、短期记忆、长期记忆、中央处理模块组成,如图3所示。语言处理模块又由编码器和解码器组成。编码器将自然语言问题转换为内部的语义表示,存放在短期记忆中,包括符号表示和神经表示。中央处理模块通过问题的语义表示,从长期记忆中找出相关的信息和知识。长期记忆中的信息和知识也是基于符号表示和神经表示的。找到相关的答案后,解码器把答案的语义表示转换为自然语言答案。
最新进展
实现问答系统有三种方法,分别是基于分析的、检索的、生成的方法。通常是单轮对话,也可以是多轮对话。这里考虑单轮的基于分析的问答系统。
传统的技术是语义分析(semantic parsing) [3]。基于人工定义的语法规则,对问句进行句法分析以及语义分析,得到内部语义表示——逻辑表达式。语义分析需要人工定义句法,开发成本较高,可扩展性不好。
近年,基于神经符号处理的问答系统的研究有了很大突破。可以从数据出发,完全端到端地构建问答系统。不需要人工干预,只需要提供足够量的训练数据。问答的准确率也有了一定的提升。传统的语义分析技术被颠覆。下面介绍几个有代表性的工作。
脸书(Facebook)的韦斯顿(Weston)等人提出了记忆网络(memory networks)框架[4],可以用于如下场景的问答:
John is in the playground.
Bob is in the office.
John picked up the football.
Bob went to the kitchen.
Q: where is the football?
A: playground.
记忆网络由神经网络和长期记忆组成。长期记忆是一个矩阵,矩阵的每一个行向量是一个句子的语义表示。阅读时,记忆网络可以把给定的句子转换成内部表示,存储到长期记忆中。问答时,把问句也转换成内部表示,与长期记忆中每行的句子语义表示进行匹配,找到答案,并做回答。
谷歌DeepMind的格拉夫(Graves)等发明了可微分神经计算机(differentiable neural computer)模型[5]。该模型由神经网络和外部记忆组成。外部记忆是一个矩阵,可以表示复杂的数据结构。神经网络负责对外部记忆进行读写,它有三种类型,拥有不同的注意力机制,表示三种不同的读写控制,对应哺乳动物中海马体的三种功能。神经网络在数据中进行端到端的学习,学习的目标函数是可微分的函数。可微分神经计算机模型被成功应用到了包括智能问答的多个任务中。
谷歌的尼拉康藤(Neelakantan)等开发了神经编程器(neural programmer)模型[6],可以从关系数据库中寻找答案,自动回答自然语言问题。模型整体是一个循环神经网络。每一步都是基于问句的表示(神经表示)以及前一步的状态表示(神经表示),还包括计算操作的概率分布和列的概率分布,以及选择对数据库表的一个列来执行一个操作(符号表示)。顺序执行这些操作,并找到答案。操作表示对数据库列的逻辑或算数计算,如求和、大小比较。学习时,整体目标函数是可微分的,用梯度下降法训练循环神经网络的参数。
谷歌的Liang等开发了神经符号机(neural symbolic machines)模型[7]。神经符号机可以从知识图谱三元组中找到答案,回答像“美国最大的城市是哪个?”这样的问题。模型是序列对序列(sequence-to-sequence)模型,将问题的单词序列转换成命令的序列。命令的序列是LISP语言²的程序,执行程序就可以找到答案。神经符号机的最大特点是序列对序列模型表示和使用程序执行的变量,用附加的键-变量记忆(key-variable memory)记录变量的值,其中键是神经表示,变量是符号表示。模型的训练是基于强化学习(策略梯度法)的端到端的学习。
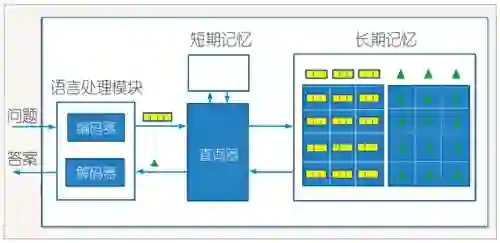
图4 包含查询器的智能问答系统
华为公司的吕正东等开发了神经查询器(neural enquirer)、符号查询器(symbolic enquirer)和连接查询器(coupled enquirer)三个模型[8,9],用于自然语言的关系数据库查询。例如,可以从奥林匹克运动会的数据库中寻找答案,回答“观众人数最多的奥运会的举办城市的面积有多大?”这样的问题。问答系统包括语言处理模块、短期记忆、长期记忆和查询器,语言处理模块又包括编码器和解码器。图4即是这种架构的具体实现。查询器基于短期记忆的问题表示(神经表示)从长期记忆的数据库中(符号表示与神经表示)寻找答案。符号查询器是一个循环神经网络,将问句的表示(神经表示)转换为查询操作(符号表示)的序列,执行操作序列就可以找到答案。利用强化学习,具体的策略梯度法,可以端到端地学习此循环神经网络。神经查询器是一组深度神经网络,将问句的表示(神经表示)多次映射到数据库的一个元素(符号表示),也就是答案,其中一个神经网络表示一次映射的模式。利用深度学习,具体的梯度下降法,可以端到端地学习这些深度神经网络。符号查询器执行效率高,学习效率不高;神经查询器学习效率高,执行效率不高。连接查询器结合了两者的优点。学习时首先训练神经查询器,然后以其结果训练符号查询器,问答时只使用符号查询器。
未来展望
计算机最擅长的是计算和存储,其强大的计算能力已经在现实中展现出巨大的威力,但是其强大的存储能力并没有得到充分的发挥,通常存储的是数据,而不是信息和知识。计算机还不能自动地对数据进行筛选和提炼,抽取信息和知识,并把它们关联起来,存储在长期记忆里,为人类服务。
可以预见,未来会有这样的智能信息和知识管理系统出现,它能够自动获取信息和知识,如对之进行有效的管理,能准确地回答各种问题,成为每一个人的智能助手。人工智能技术,特别是神经符号处理技术,有望帮助我们实现这样的梦想。期盼这一天的到来!
致谢
感谢吕正东、蒋欣、尚利峰、牟力立、殷鹏程等,本文中的很多想法是在与他们合作的工作中产生的。
作者介绍
李航


脚注
参考文献
中国计算机学会

长按识别二维码关注我们
CCF推荐
【精品文章】
点击“阅读原文”,加入CCF。



