李飞飞等ICLR2019论文:构建人类眼睛感知评估

【导读】生成模型通常使用人工评估来确定和证明进展。不幸的是,现有的人类评估方法目前还没有标准化,李飞飞等人ICLR2019论文构建人类眼睛感知评估(HYPE),带给你新的认知。
HYPE是一种人类眼睛感知评估,它具有四大特点:
(1)以感知的心理物理学研究为基础,
(2)在一个模型的不同随机抽样输出集合中是可靠的,
(3)能够产生可分离的模型性能,
(4)在成本和时间上是有效的。
我们引入了两种变体:一种是在自适应时间约束下测量视觉感知,以确定模型输出显示为真实的阈值(例如250毫秒),另一种是在无时间约束的假图像和真实图像上测量人为错误率的较便宜变体。
我们测试了六种最先进的生成对抗网络和两种采样技术,利用四种数据集(CelebA, FFHQ, CIFAR-10和ImageNet)生成有条件和无条件图像。我们发现HYPE可以跟踪模型之间的相对改进,并通过引导抽样确认这些测量是一致且可复制的。
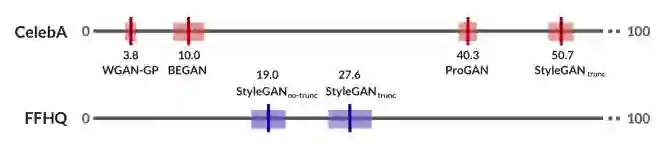
图1:我们的人的评估指标,HYPE,可以一直区分彼此模型:这里,我们比较不同的生成模型在FFHQ上的表现。50%的分数代表取自真实的不可区分的结果,而50%以上的分数代表超现实。
我们进行了两次大规模实验。首先,在CelebA-64,我们通过四个生成对抗网络(GANs)展示了HYPE在无条件人脸生成上的表现。我们还在FFHQ-1024上评估了的两个较新的GANs。HYPE表明,GANs之间有明显的、可测量的知觉差异;这种排名在HYPE和HYPE∞上都是相同的。表现最好的模型StyleGAN在FFHQ上接受了训练,并使用截尾技巧(截断技巧)进行了采样,HYPE∞表现27.6%,这表明改进的机会很大。我们可以以60美元的价格用30名人工评估人员用10分钟的时间重现这些结果,以95%的置信区间。
我们在ImageNet 的和CIFAR-10数据集上对HYPE 的性能进行了测试。当产生CIFAR-10时,像BEGAN这样的早期GANs在HYPE∞中是不可分离的:它们没有一个能产生令人信服的结果,证明这是一项比面部生成更困难的任务。较新的StyleGAN显示出可分离的改进,这表明它比以前的模型有了进步。有了ImageNet-5,GANs已经改进了被认为“更容易”生成的类(例如柠檬),但在所有较难生成类(例如法国号)的模型中,它的分数始终较低。
对于研究人员来说,HYPE是一种快速的解决方案,可以测量他们的生成模型,只需点击一下就可以得出可靠的分数并测量进展。
HYPE在Amazon Mechanical Turk上向众包评估人员逐个显示一系列图像,并要求评估人员评估每个图像是真是假。一半的图像是真实图像,从模型的训练集(例如,FFHQ, CelebA, ImageNet或CIFAR-10)中绘制。另一半来自模型的输出。我们使用现代众包培训和质量控制技术来确保高质量的标签。模型创建者可以选择执行两种不同的评估:HYPEtime,它收集时间限制的感知阈值来测量心理测量功能并报告人们进行准确分类所需的最短时间;HYPE∞,一种简单的方法,它在无时间限制的情况下评估人们的错误率。

图2:使用在FFHQ上训练的StyleGAN的截断技巧采样的示例图像。右边的图像显示出最高的HYPE∞分数,最高的人类感知。
HYPEtime:基于心理物理学的知觉保真度
我们的第一种方法,HYPEtime,测量时间限制的知觉阈值。它属于心理学文献,一个专门研究人类如何感知刺激的领域,在感知图像时评估人类时间阈值。我们的评估方案遵循所谓的自适应阶梯法(图3)程序。图像在有限的时间内被闪烁,之后评估者被要求判断它是真是假。如果评估者一直回答正确,楼梯会下降并以更少的时间闪烁下一个图像。如果评估者不正确,楼梯会上升并提供更多的时间。
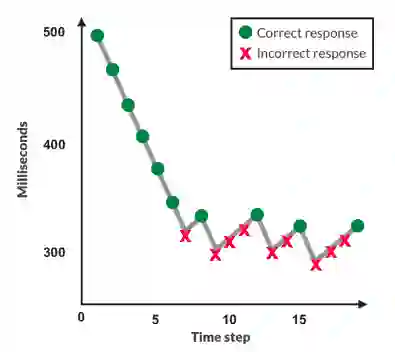
图3:自适应阶梯法向评估者显示不同时间曝光的图像。正确时减少,错误时增加。模态暴露测量他们的感知阈值。
这个过程需要足够的迭代来收敛到评估者的感知阈值:他们能够保持有效性能的最短曝光时间。这个过程产生了所谓的心理测量功能,即时间刺激暴露与准确性的关系。例如,对于一组易于识别的生成图像,人类评估人员将立即降低到最低毫秒曝光。HYPEtime为每个评估者显示三个楼梯块。图像评估从3-2-1倒计时时钟开始,每个数字显示500毫秒。然后显示当前曝光时间的采样图像。每幅图像后立即快速显示四幅感知掩模图像各30毫秒。这些噪声面罩被扭曲,以防止图像消失后的视网膜后像和进一步的感官处理。我们使用现有的纹理合成算法生成遮罩。每次提交报告时,HYPE都会向评估者揭示报告是否正确。图像曝光范围[100毫秒,1000毫秒],来源于感知文献。所有块从500毫秒开始,持续150个图像(50%生成,50%真实),根据之前的工作经验调整值。在3向上/1向下自适应阶梯方法之后,曝光时间以10毫秒的增量增加,并以30毫秒的降幅减少,理论上这会导致接近人类感知阈值的75%精度阈值。每个评估人员在不同的图像集上完成多个称为块的楼梯。因此,我们观察到模型的多个度量。我们采用三个区块,以平衡评估人员的疲劳。我们对各模块的模态暴露时间进行平均,以计算每个评估者的最终值。分数越高表明模型越好,其输出需要更长的时间曝光才能从真实图像中辨别出来。
HYPE∞:成本效益近似
在前面的方法的基础上,我们引入了HYPE∞:一种简单、快速、廉价的方法,在除去HYPEtime后优化速度、成本和解释的方便性。HYPE∞在给定的无限评估时间内,从感知时间的测量值转变为人类欺骗率的测量值。HYPE∞分数测量任务的总误差,使测量能够捕获假图像和真实图像上的误差,以及假图像看起来比真实图像更逼真时超现实生成的效果。HYPE∞比HYPEtime需要更少的图像才能找到稳定的值,经验上可以减少6倍的时间和成本(每个评估者10分钟,而不是60分钟,同样的速度是每小时12美元)。分数越高越好:10%的HYPE∞表示只有10%的图像欺骗了人,而50%的人则表示人们偶然会误认为真实和虚假图像,从而使虚假图像与真实图像无法区分。超过50%的分数表明是超现实的图像,因为评估者错误的图像的概率大于偶然性。HYPE∞向每个评估者显示总共100张图像:50张真实图像和50张假图像。我们计算错误判断的图像比例,并将K图像上n个评价者的判断汇总,得出给定模型的最终得分。
设计一致可靠
为了确保我们报告的分数是一致和可靠的,我们需要从模型中充分抽样,并雇用、鉴定和适当支付足够的评估人员。
采样足够的模型输出。从特定模型中选择要评估的K图像是公平和有用评估的关键组成部分。我们必须对足够多的图像进行采样,以充分捕捉模型的生成多样性,同时在评估中平衡这一点与可跟踪成本。我们遵循现有的工作,通过从每个模型中抽取k=5000个生成图像和从训练集中抽取k=5000个真实图像来评估生成输出。从这些样本中,我们随机选择要给每个评价者的图像。
评估人员的质量。为了获得一个高质量的评估人员库,每个人都需要通过一个资格鉴定任务。这种任务前过滤方法,有时被称为面向人的策略,其性能优于执行任务后数据过滤或处理的面向过程的策略。我们的鉴定任务显示100个图像(50个真实图像和50个假图像),没有时间限制。评估人员必须正确分类65%的真实和虚假图像。该阈值应被视为一个超参数,并可能根据教程中使用的GANs和所选评估者的期望识别能力而改变。我们根据100个答案中65个二项选择答案的累积二项式概率选择65%:只有千分之一的概率评价者有资格通过随机猜测。
与任务本身不同的是,虚假的资格图像是从多个不同的GANs抽取出的,以确保所有主体都具有公平的主体资格。资格鉴定是偶尔进行的,这样一批评估人员就可以根据需要评估新的模型。
付款。评估人员的基本工资为1美元,用于完成资格鉴定任务。为了激励评估人员在整个任务中保持参与,资格认证后的所有进一步薪酬都来自每幅正确标记的图像0.02美元的奖金,通常总计工资为12美元/小时。
我们报告了HYPEtime的结果,并证明HYPE∞的结果与HYPEtime的结果接近,只是成本和时间的一小部分。
HYPEtime
CelebA-64。我们发现StyleGANtrunc的HYPE得分最高(模式曝光时间),平均为439.3毫秒,这表明评估者需要近半秒的曝光来准确分类StyleGANtrunc图像(表??)StyleGANtrunc之后是ProGAN,速度为363.7毫秒,时间下降17%。BEGAN 和WGAN-GP都很容易被识别为假的,因此它们在可用的最小曝光时间100毫秒左右排在第三位。BEGAN 和WGAN-GP都表现出一种触底效应——快速一致地达到最小曝光时间100毫秒。
为了证明模型之间的可分性,我们报告了单向方差分析(ANOVA)测试的结果,其中每个模型的输入是每个模型的30个评估者的模式列表。ANOVA结果证实存在统计学上显著的综合差异(F(3,29)=83.5,P<0.0001)。使用Tukey测试进行的成对事后分析证实,除了BEGAN 和 WGAN-GP (n.s.).之外,所有模型对都是可分离的(所有p<0.05)。
FFHQ-1024.我们发现,StyleGANtrunc的曝光时间比StyleGANno-trunc高,分别为363.2 毫秒和240.7 毫秒(表1)。虽然95%的置信区间代表2.7 毫秒的保守重叠,但未配对的t-test证实两种模型之间的差异是显著的(t(58)=2.3,p=0.02)。
HYPE常数
CelebA-64。表2是CelebA-64的HYPE∞结果。我们发现StyleGANtrunc使得HYPE∞得分最高,50.7%会欺骗评估者。StyleGANtrunc之后是ProGAN,为40.3%,开始于10.0%,WGAN-GP为3.8%。无重叠的置信区间,方差分析检验显著(F(3,29)=404.4,P<0.001)。成对的事后Tukey检验表明,所有的模型对都是可分离的(p<0.05)。值得注意的是,HYPE∞导致了BEGAN 和 WGAN-GP的可分离结果,而在HYPEtime中,由于自下而上的影响,它们不可分离。

表2:在CelebA-64上训练的四个GANs上的HYPE∞。与直觉相反,真实误差随着假图像上的误差而增加,因为评价者变得更加困惑,两种分布之间的区分因素变得更加难以辨别。
FFHQ-1024.我们观察到StyleGANtrunc和StyleGANno-trunc之间的一致可分离性差异,以及模型之间的清晰轮廓(表3)。HYPE∞将StyleGANtrunc(27.6%)排在StyleGANtrunc(19.0%)之上,没有重叠的CIs。可分离性通过未配对t检验(t(58)=8.3,p<0.001)得到确认。

表3:FFHQ-1024培训的StyleGANtrunc和StyleGANno-trunc上的HYPE∞。评价者经常被StyleGANtrunc欺骗。
准确度和时间的成本权衡
HYPE的目标之一是节约成本和时间。当运行HYPE时,在准确性和时间以及准确性和成本之间有一个内在的权衡。这是由大量法律驱动的:在众包任务中招聘额外的评估人员通常会产生更一致的结果,但成本更高(因为每个评估人员的工作都是付费的),而且完成的时间更长(因为必须招聘更多的评估人员,并且必须完成他们的工作)。
为了处理这种权衡,我们在StyleGANtrunc上运行了一个HYPE∞实验。我们用60个评估者完成了一个额外的评估,并计算了95%的自举置信区间,从10到120个评估者中进行选择(图4)。我们看到CI开始聚集大约30名评估人员,这是我们推荐的要招聘的评估人员数量。
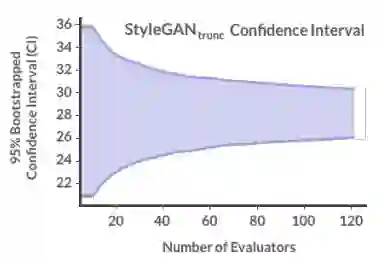
图4:更多评估者对CI的影响
对评估人员的付款按照“方法”一节中的描述进行计算。在30个评估者中,在一个模型上运行HYPEtime的成本约为360美元,而在同一个模型上运行HYPE∞的成本约为60美元。两项任务的每个评估人员的报酬约为12美元/小时,评估人员平均花在一项HYPE任务上的时间为一小时,在HYPE∞任务上花费的时间为10分钟。因此,HYPE∞的目标是在保持一致性的同时,运行起来要比HYPEtime便宜得多。
与自动化指标的比较
由于FID是最常用的无条件图像生成评估方法之一,因此有必要在相同的模型上将HYPE与FID进行比较。我们还比较了两个新的自动化指标:KID,一个独立于样本大小的无偏估计量,以及F1/8(精度),它独立的捕获保真度。我们通过Spearman秩次相关系数表明,HYPE分数与FID不相关(ρ=-0.029,p=0.96),其中-1.0的Spearman相关性是理想的,因为较低的FID和较高的HYPE分数表示更强的模型。因此,我们发现,FID与人类的判断并不高度相关。同时,HYPE时间和HYPE∞之间具有很强的相关性(ρ=1.0,p=0.0),其中1.0是理想的,因为它们是直接相关的。我们通过评估CelebA-64和FFHQ-1024的50K生成和50K真实图像的标准协议计算FID,重现StyleGANno-trunc的分数。Kid(ρ=−0.609,p=0.20)和精度(ρ=0.657,p=0.16)均显示出与人类的统计上不显著但中等水平的相关性。
模型训练时的HYPE∞
HYPE也可以用来评估模型培训的进展。我们发现随着StyleGAN训练的进展,HYPE∞分数从4k时的29.5%上升到9k时的45.9%,到25k时的50.3%(f(2,29)=63.3,p<0.001)。
现在我们转到另一个流行的图像生成任务:对象。实验1表明,HYPE∞是HYPEtime的一个有效且具有成本效益的变体,这里我们只关注HYPE∞。
ImageNet-5
我们评估了五个ImageNet类上的条件图像生成(表4)。我们还报告了FID、KID和F1/8(精度分数。为了评估每个对象类中三个GAN的相对有效性,我们计算了五个单向方差分析,每个对象类一个方差分析。我们发现,对于来自三个简单类的图像,HYPE∞分数是可分离的:萨摩耶(狗)(F(2,29)=15.0,p<0.001),柠檬(F(2,29)=4.2,p=0.017),和图书馆(F(2,29)=4.9,p=0.009)。配对后验表明,这一差异仅在SN-GAN和两个BigGAN变体之间有显著性。我们还观察到,模型具有不同的优势,例如SN-GAN更适合生成图书馆而不是萨摩耶。
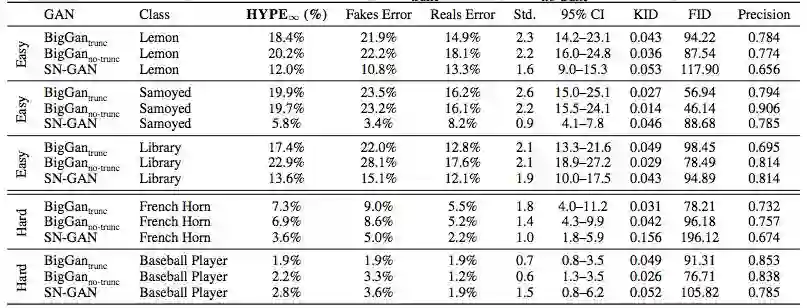
表4:在ImageNet上训练的三个模型上的HYPE∞和在五种类别里有条件抽样。BigGAN的表现通常优于SN-GAN。BigGANtrunc和BigGANno-trunc不可分离。
与自动化指标的比较。所有三个GANs的Spearman秩次相关系数在所有五个分类中均显示,HYPE∞分数与KID(ρ=-0.377,p=0.02)、FID(ρ=-0.282,p=0.01)之间存在一个低到中等的相关性,与精度的相关性可忽略不计(ρ=-0.067,p=0.81)。我们的ImageNet-5任务需要一些相关性,因为这些度量使用预训练的ImageNet嵌入来测量生成数据和实际数据之间的差异。
有趣的是,我们发现这种相关性依赖于GAN:仅考虑SN-GAN,我们发现KID(ρ=−0.500,p=0.39)、FID(ρ=−0.300,p=0.62)和精度(ρ=−0.205,p=0.74)的系数更强。当只考虑BigGAN时,我们发现FID(ρ=−0.151,p=0.68)、FID(ρ=−0.067,p=0.85)和精度(ρ=−0.164,p=0.65)的系数要弱得多。这说明了这些自动度量的一个重要缺陷:它们与人类关联的能力取决于度量正在评估的生成模型,根据模型和任务而变化。
CIFAR-10
针对CIFAR-10上无条件生成的困难任务,我们在实验1中使用了相同的四种模型体系结构:CelebA-64。表5显示HYPE∞能够将StyleGANtrunc与早期的BEGAN, WGAN-GP, 和ProGAN分离,这表明StyleGAN是其中第一个在CIFAR-10无条件对象生成方面取得人类可感知进展的。

表5:CIFAR-10上的四种型号。StyleGANtrunc可以从CIFAR-10生成逼真的图像。
与自动化指标的比较。所有四个GAN的Spearman秩次相关系数均为中等,但统计学上不显著,与KID(ρ=-0.600,p=0.40)和FID(ρ=0.600,p=0.40)和精度(ρ=-800,p=0.20)的相关性。
预期用途。我们创造了一个HYPE作为解决方案,人类对生成模型的评估。研究人员可以上传他们的模型,获得分数,并通过我们的在线部署比较进展。在高使用率期间(如比赛),retainer模式允许在10分钟内使用HYPE∞进行评估,而不是默认的30分钟。
局限性:HYPE的扩展可能需要不同的任务设计。在文本生成(翻译、标题生成)的情况下,HYPE需要对感知时间阈值进行更长、更大范围的调整。除了测量真实性之外,其他指标,如多样性、过度拟合、纠缠度、训练稳定性、计算和样本效率,都是可以纳入但不在本文范围内的额外基准。有些可能更适合全自动评估。
结论:HYPE为生成模型提供了两个人类评估基准:
(1)以心理物理学为基础,
(2)提供产生可靠结果的任务设计,
(3)单独的模型性能,
(4)具有成本和时间效率。
我们引入两个基准:使用时间感知阈值的HYPEtime和报告无时间限制的错误率的HYPE∞。我们展示了我们的方法在六种模型中的图像生成效果:StyleGAN、Sn-GAN、BigGAN、ProGAN、Begin、WGAN-gp、四种图像数据集Celeba-64、FFHQ-1024、CIFAR-10、ImageNet-5,以及两种采样方法。{有、无截断技巧}。
来源:stanford,新智元
参考来源:
https://hype.stanford.edu/
论文地址:
https://arxiv.org/pdf/1904.01121.pdf
广告 & 商务合作请加微信:kellyhyw
投稿请发送至:mary.hu@aisdk.com

