参数跑分真那么重要?大模型评价标准该变变了
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
预训练大模型,自诞生以来不断刷新AI能力,成为业界竞争的焦点。
参数规模突破千亿直奔万亿,开发难度和成本也随之增大。
到了这个份上,大模型的开发与应用似乎成了“巨头专属”,效果越来越惊艳,离普通人却越来越远了。
不过,例外正在发生。
最近一场AI创意赛上,全国各地近2000人参与,大家脑洞大开,使用大模型能力开发出各类趣味应用。
如B站UP主同济子豪兄的这款论文起名神器,输入摘要就可自动生成论文标题。
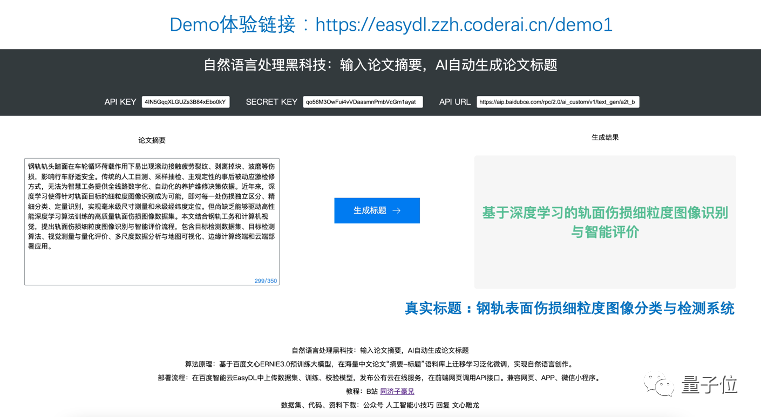
开发出这些作品的人其实很多并非AI从业者,甚至没有计算机专业背景,比如文科生,还有创业公司产品经理等。
这些作品本身倒不是本文的重点,只是,使用大模型什么时候门槛这么低了?
这场由百度举办的比赛,提供的是文心知识增强大模型做技术支持,此外还有一个特别的标签——
业界首次大模型能力向公众开放。

要知道,大模型能力像要向公众开放,不能光是发发论文、开源一下代码了事。
背后还要额外付出努力,提供一系列低门槛的开发平台和工具、相应的培训和教学,才能让没有AI基础、甚至不会编程的人都能“玩转大模型”。

为什么要做到这一步?
百度集团副总裁吴甜这样回答:
这个世界上有技术背景的人还是少数,AI想要落地不能仅靠技术人员,创意在民间。
只有技术门槛低到了所有人都可以的时候,创意才会真正大规模爆发起来,这是人工智能落地路上必然的趋势。
大模型落地难在哪?
想要理解这个趋势,得先跳出比赛本身,看看AI落地、特别是大模型落地到底遇到了什么困难。
最近,微软认知服务团队发表的一篇大模型遭遇“不可能三角”论文,引发业内关注。

论文提出,目前的预训练语言模型对于模型规模、精调能力、小样本能力三者不可兼得。
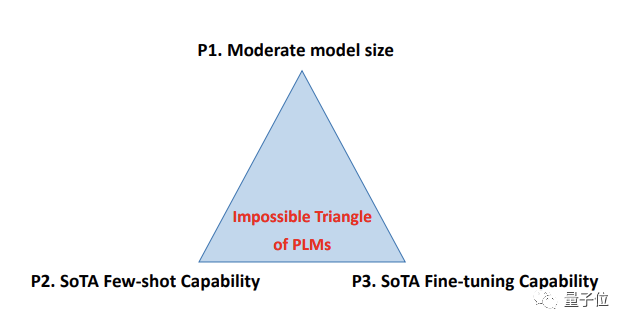
目前业内的普遍做法,是试图得其二的同时努力往第三点靠。
放弃控制规模开发超大模型,可以再用知识蒸馏等手段做小型化。
不追求少样本能力,可以在缺少数据的任务上做数据增强。
不追求精调能力,改用提示学习 (Prompt learning)做少样本任务的方法最近也火了起来。
不过妥协的办法总归是有这样那样的问题,从效果或成本上阻碍大模型进一步应用落地。
如何突破这个“不可能三角”,各家都有着自己的答案。
微软论文中给出一种可能路径,先从个别任务上打开突破口,如命名实体识别或文本摘要,实现单一任务占据全部三项优势后再图横向拓展。
谷歌近日推出的下一代AI架构Pathway,则是从提升训练效率角度尝试解决。也就是不怕模型大,转而追求把炼大模型的难度降低。
百度的技术路线则是知识增强,让AI在大规模知识的指导下以更高效率学习到海量数据中蕴含的规律。
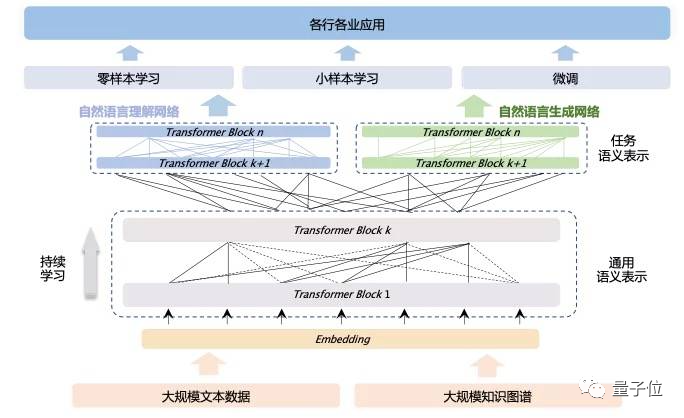
百度靠引入大规模知识图谱,只用百亿级参数规模就在语言模型权威测评SuperGlue上登顶全球榜首,超越人类水平0.8个百分点。
后来发布的全球首个千亿级知识增强大模型鹏城-百度·文心,更是在机器阅读理解、文本分类、语义相似度计算等60多项任务中都取得了最好效果,在30多项小样本和零样本任务上,也刷新了基准。
……
关于模型本身的事先说到这里,现阶段要想真正解决大模型落地问题,百度还提出一个观点:
光靠技术手段是远远不够的。
跳出技术之外
文心大模型家族自2019起开始打造,百度对其定位是产业级知识增强大模型。

知识增强前面已经介绍,那么该如何理解“产业级”这个定位?
吴甜解释其含义为“来源于产业实践,同时服务于产业实践,在实践当中建设起来”。
一方面,百度研发大模型的初衷就来自产业的落地实践。
AI落地场景越多,模型面临泛化性差的问题就越突出。每面临一个新的场景就需要收集新的数据,进行新的模型训练。
预训练模型的出现,通过集中提供通用算法、打造技术底座,大幅降低了人工智能的应用门槛,从开发阶段就应该是面向产业的。
开发设计阶段用到的数据要来源于产业。百度走的知识增强路线,意味着深入到金融、医疗等特定行业时,除了收集该行业的非结构化数据,还要积累专业知识。
做不同的任务设计,模型最后学到的是不一样的。百度会结合大量的产业应用,借助任务构建器不断地提炼任务、挖掘任务,让模型持续进行学习。
另一方面,文心又依托于百度功能完备的产业化大生产平台输出到百行千业,为行业使用大模型带来更大的便捷。
文心大模型开放了配套大模型开发、轻量化和部署的工具,推进产业落地应用,激发创意。
依托百度飞桨平台自主研发的端到端自适应分布式训练框架与4D混合并行技术,以及百舸AI异构计算平台,解决了大模型训练过程中多个世界性难题,使大模型训练速度提升、模型效果更优。
在落地应用上,文心若仅提供API调用只能满足离技术较近行业的少量需求。
因此,百度还会提供配套的数据标注、模型轻量化、边缘部署等一系列工具和平台。
如此开发出的产业级知识增强大模型,核心价值在于驱动AI的规模化应用。

人工智能在与众多这些产业结合时,场景非常分散、长尾。
针对高频次、容易流程化和标准化的场景,可以直接提供开发好的AI能力,如保险行业的合同处理,可以靠智能文档分析能力完成。
但还有很多如制造业、教育等行业中更碎片化的场景,数字化基础薄弱,行业知识更依靠人类专家经验、师徒间口口相传。
这就回到了文章开头的问题,为什么要把AI大模型能力做到向公众开放?
数量众多的场景,要是靠AI工程师去一个一个去深入调研、做适配,无法解决所有的问题。
只有让有需求的人都能认识、接触、亲手用上大模型,才能激发创意,取得应用落地上的更大突破。
为此,百度飞桨提供了零门槛AI开发平台EasyDL,拥有从数据采集、标注、清洗到模型训练、部署的一站式AI开发能力,无需编程和算法基础就能使用。
对更复杂的需求,也有BML全功能AI开发平台,提供开发环境、功能组件和高性价比的算力资源。
通过不断降低门槛,构建大模型生态,文心大模型对外调用量超5000万次,服务了6万+开发者、企业、科研机构。
为了让更多人看到大模型、了解大模型、用上大模型,百度举办了面向公众的AI创意赛。
此外还有面向产业的首席AI架构师培养计划,已向业界输送247位AI架构师,遍布工业、农业、金融、交通、能源等数十个行业。
人工智能高校师资培训,免费培训AI专业教师3000余人,助力700多个高校开设深度学习课程,培养了数万名在校生。
去年底,还宣布成立百度松果学堂,打造源于产业的AI人才培养平台,致力于让每个人都能更便捷地获取AI知识,学习AI技术。
所有积累的行业知识、产业应用、人才都将汇聚在文心大模型生态,以及背后更大的百度飞桨深度学习生态中进一步推动AI落地,形成正向循环。
到底什么才是一个好的大模型?
当今,各大研究机构、科技公司都争相打造自己的大模型。
参数规模上千亿、训练数据也上千GB。单体稠密模型之外,也有稀疏模型路线,参数更是突破万亿。
各大基准测试榜单也不断被刷新,超越人类平均水平已是过去式,追上人类最佳水平成了新的目标。
层出不穷的进展让人眼花缭乱,到底该如何评价一个大模型的优劣?
若是单纯比参数大小,缺失了成本和效率的维度。若只看跑分高低,也看不出真正落地时的效果。
如此看下来,一个大模型好坏的新标准也呼之欲出:
能否在性能领先的同时支撑大量产业应用。
从这个角度看,开发者数量超过6万、在数百个场景中落地应用的文心大模型,真正可称作“产业级”大模型。
而且百度打造大模型,从技术和难度上来说,并无意外之处。
但最值得关注的还是入场的初心和立场。
据称文心大模型问世,核心是来自于产业实际的需求,并非闭门造车的结果。
一方面,产业有需求,于是百度有了响应,并且很快实现了技术工程化,再通过飞桨快速实现了产业应用。
另一方面,产业的反馈证明了大模型的价值。在文心落地中,不仅各类大小企业实现了产业化升级,而且侧面证明了大模型在商业化落地上的可能性和可行性之路。
在AI模型中,输入、输出以及反馈是缺一不可的关键要素,而文心大模型的实践,同样完成了这样的闭环。
但这种路径在大模型上是否可复制?
答案或许还不能言之凿凿。
首先要考虑的是技术能力,其次还得有产业生态,最后还能真正从开发者的反馈中获得认可。
文心之路,多少有点百度飞桨的“凡尔赛”意味,其所具备的要素,并非其他玩家兼具。
但至少,一条大模型的商业化落地路径,现在已经清晰可见。
文心模式,就是这条路线。
参考资料:
[1] https://arxiv.org/abs/2204.06130
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



