最新语言表示方法XLNet
作者:张贵发
研究方向:自然语言处理
介绍
近期,由卡耐基梅隆大学和谷歌大脑提出的全新 XLNet 在 20 个任务上超过了 BERT 的表现,而且还开放了源码,今天我们来讨论一下这篇论文。
论文地址:https://arxiv.org/pdf/1906.08237.pdf
github: https://github.com/zihangdai/xlnet
Context (文本内容)
Autoregressive vs Autoencoding (自回归与自编码)
XLNet: Best of both worlds
Permutation Language model
Two-Stream self-attention mechanism
Recurrence mechan
我们将快速讨论下关于文本处理两种主要方法的背景,自回归与自编码,然后进一步延申之两者的最好结合-----xlnet

实践证明无监督的学习是种坚如磐石的方法。从无背景中学习,随着语言模型的兴起,出现了许多很好的文本表示的模型如word2vec、glove等。我们有两种具有竞争力的方法自回归(AR)与自编码(AE),我们发现两种方法都存在一些限制。
AR(自回归)
AR语言模型试图用自回归模型来估计文本语料库的概率分布,具体来说,给定一个文本序列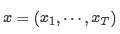
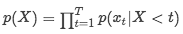
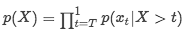

The animal didn’t cross the street because it was too tired.
The animal didn’t cross the street because it was too narrow
如我们给定的例子中,只看前文,我们很难猜测it指代的具体内容,编码的时候我们要看整个句子的上下文,只看前面或者只看后面是不行的。
AR模型的两个问题:
顺序依赖,t依赖t-1时刻。(或者反向)
单向信息流(如例子中指代信息,不能确定)
由于AR语言模型只被训练为对单向上下文(向前或向后)进行编码,因此它不能有效地对深层双向上下文进行建模。相反,下游语言理解任务通常需要双向上下文信息。这导致了AR语言建模和有效的预训练之间的差距。
AE(自编码)
单向信息流的问题 ,只能看前面,不能看后面,其实语料里有后面的信息,只是训练语言模型任务特殊要求只能看后面的信息,这是最大的一个问题。那么我们可以改变我们的训练任务。

基于AE的预训练是从损坏的输入中重建原始数据。一个值得注意的例子是Bert,它是最先进的预训练方法。给定输入token序列,token的某一部分将被一个特殊符号[mask]替换(如dog、likes),并且模型经过训练,可以从损坏的版本中恢复原始token。bert可以利用双向上下文进行重建。作为一个直接的好处,这弥补了前面提到的AR语言建模中的双向信息缺口,从而提高了性能。

基于自编码的架构,我们可以同时catch到两边的依赖。但是同时存在一些限制:
在预测屏蔽token时,输入中有其他屏蔽token
如果屏蔽token是相互依赖的呢
通过自动编码的架构,意味着我们在输出中有一个序列,在输入确定的序列中添加一些噪声,通过mask,因此当你想要预测这些mask的时候,你有左边的输入标记和在右边有什么限制。当你预测令牌之一的输入,右边也是mask的token,所以你是失去了部分信息,这是有限的,第二个问题是有两个连续的masked token像 new york,new york 是有内部依赖的,你想预测new york的结果非常好,重要的是要知道new是第一个令牌,new york与york new可能是两个城市。这与他们的位置关系存在严格的限制。
另外,在训练期间,BERT在预训练时使用的[MASK]等人工符号在实际数据中不存在,从而导致预训练的网络差异。
XLNet
面对现有语言预训练目标的优缺点,本文提出了一种广义自回归方法XLNET,它既利用了AR语言建模的优点,又避免了AE的局限性。
xlnet是基于自回模型上的,但是它不只是向前或向后,而是双方的排列来获取依赖信息。避免单向信息流。
作为一种广义的AR语言模型,XLNet不依赖于数据破坏。避免mask丢失信息。避免与训练与微调的差异弊端。
融合了transformerXL的方法(SOTA LM)
Permutation Language Modeling

首先,我们不希望花更长的时间只是向后或只是向后,我们更关注形成新的序列,如给定序列[1,2,3,4],我们的目标是预测3,首先根据这个因子为4的序列进行全排列,形成24种情况。上图列出了其中4中排列情况,每一种的计算如下:
第一,左侧没有值,是句子的开端,无需计算
第二,
第三,
第四,
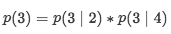
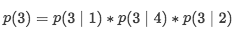
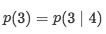
如果是传统的AR会直接计算 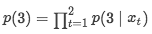
这样的处理方式,解决了单向注意力流问题,还避免了mask标记带来的问题。
那么怎么使它工作呢?
首先是位置编码,我们需要很好的位置计算,因为我们混合了一切,外部从左到右,或者从右到左,我们需要有一些位置,好在tansfomer中已经解决了这样的问题,标志只是正弦信号,他们使用了相对位置。这里提一下bert用的是绝对位置。

有了序列的选集,那我们该选择哪一个进行训练呢?
我们有4个因子就有24中排列,因此分解它很疯狂,对样本进行抽样,随机抽样,可能性是上图的公式,Zt是一切可能,这里表示24(4!)种分解,z是其中之一,本质上,对于文本序列X,我们一次采样一个分解顺序z,
并根据分解顺序分解似然 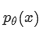
Two-Stream self-attention
接下来,怎么真正的处理context和position呢?

其实思路很简单,预测的时候就是保持住position不变,同时移除预测位置的context embedding。训练的时候保留context embedding。Two-Stream Self-Attention巧妙地结合了两个处理。
在预测当前xt的时候,fix住position,移除context embeding。
当预测其他内容时候,再保留context embedding信息。
假设我们使用标准的SoftMax公式参数化下一个token分布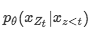

其中
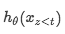 表示在适当屏蔽后transformer网络产生的表示。现在注意,表示
表示在适当屏蔽后transformer网络产生的表示。现在注意,表示


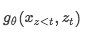 是一种新的表示形式,它另外以目标位置zt作为输入。
是一种新的表示形式,它另外以目标位置zt作为输入。

如上图所示当作为内容表示时
,简称h_zt,其作用与transformer标准隐藏状态相似。这种表示同时对上下文和x_zt本身进行编码。自己的context embedding参与到了计算。公式如下:


查询表示 g_θ(x_{z<t},z_t) ,简称g_zt,只访问上下文信息x_{z<t} 和位置z_t,而不访问内容x_zt,本位置的context embedding不参与计算,如上所述。公式如下:

计算上,第一层查询流用可训练向量初始化,即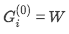
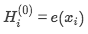

假设bert和xlnet都选择这两个令牌[new york]作为预测目标,并最大化log p(new york is a city)。另外,假设xlnet对factorization的order(is,a,city,new,york)进行采样。在这种情况下,bert和xlnet趋向与以下目标:

验证了我上文关于bert的限制问题。
关于bert或者self-attention的理解可参考我之前的文章:一步步理解bert
注意本地FineTuning的话,需要安装SentencePiece
pip install SentencePiece
执行上述命令即可,不然会报异常。
本文由作者投稿并且原创授权AINLP首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。


