汝果欲学诗,功夫在诗外——论GPT-2无监督预训练的暴力美学


“由于 GPT-2 [1] 模型过于强大,导致它有可能像 DeepFake[2] 一样被滥用,因此我们重申 OpenAI 的组织宣言,将不予发布 GPT-2 的数据集、标准模型、和训练代码。” 作者 Alec Radford 在论文和博客中这样说道。
GPT-2 有多强大?让我们从一个例子开始——机器写作——以人写的一个段落作为开始,把续写任务完全交给机器。人写的部分是:
“In ashocking finding, scientist discovered a herd of unicorns living in a remote,previously unexplored valley, in the Andes Mountains. Even more surprising tothe researchers was the fact that the unicorns spoke perfect English.”
对于这样的开头,机器续写道:
“Thescientist named the population, after their distinctive horn, Ovid’s Unicorn.These four-horned, silver-white unicorns were previously unknownto science...However, Pérez also pointed out that it is likely that theonly way of knowing for sure if unicorns are indeed the descendants of a lostalien race is through DNA.“But they seem to be able to communicate in Englishquite well, which I believe is a sign of evolution, or at least a change insocial organization,” said the scientist.”
这样的文字,在词法、句法、流畅度各个方面无不令人惊叹。而且要注意到,我所摘取的只是续写的一小部分,要是再算上其中省略的那大段文字,这真可以称得上是“谎话连篇,张口就来”。
除了这个案例,GPT-2 更是一举刷新了多个语言模型任务的新记录!表1列举了 GPT-2 的战果,总共8个任务拿下7个最佳,而且在某些任务上将此前最佳甩开了好几个身位。表中,117M、245M、762M、和1542M表示同样方法不同参数量的 GPT-2 模型。
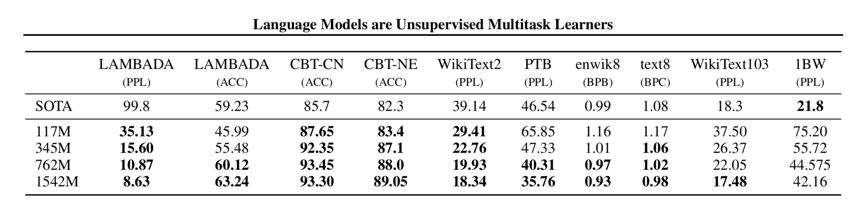
表1,GPT-2在语言模型任务上的表现惊人
GPT-2 为何能如此强大,一切要从它的前身 GPT[3] 说起。讲了这么多,还没有提到 GPT 的全名:Generative Pre-Training,其论文标题是 ImprovingLanguage Understanding by Generative Pre-Training。顾名思义,我们必须先讲讲那些没有冠上这个专名的 Generative Pre-Training。
“如果说我的模型比别人效果更好,那是因为我站在 Pre-Training 的肩膀上。”
在 NLP 中使用语言模型 Pre-Training 来辅助下游任务,历史由来已久。
使用 word embedding 来替代 one-hot 作为词的编码方式,令下游任务的输入从一开始就带有丰富的信息,是研究者们首先想到的方案。率先出场的是怀旧派选手 NNLM[4] ,它以从左到右的语言模型为目标,产出 word embedding。值得一提的是,这篇 Bengio 宗师的文章早在2003年就发表了,而 word embedding 真正声名鹊起却是十年之后的事情,不免令人唏嘘。2013年,Word2Vec[5] ,以极其直观的方法、高效的计算、却配以良好的疗效,俘获了工业界和学术界的一致好评。与 NNLM 只参考了上文不同,Word2Vec 还参考了下文,它以 CBOW 和 Skip-Gram 两种方式训练,产出 word embedding。随后诞生的 Glove[6] 与 Word2vec 方法不同效果相当,但因为方便并行训练效率更高,成为目前 wordembedding 的最佳代表。
使用预训练好的 wordembedding,替代 one-hot 作为词的编码,自然是赢在了起跑线上。但光是起跑线还不够,Elmo[7] 要多送一程。word embedding 其实也可以算作网络的一层:将 one-hot 作为输入,embedding 查表操作就是一次全连接。Elmo 的多送一程,就是把这个 word embedding 层做得更深:加一个从左到右的双向 LSTM,和一个从右到左的双向 LSTM。在预训练结束后,所有的这些层,不光是底层的 embedding,还有上层的两个 LSTM 层,都一起参与下游任务。从一层扩展到多层,或许是一个非常自然的想法,但上层引入的 LSTM 网络将牢记序列特征,使输入词在 Elmo 框架中获得多层次性的、有序的、共现跨度长的特征。这种改变给下游任务带来的提升是质的飞越。
要说2018年最佳的 NLP 成果,Bert[8] 当之无愧。Elmo 的预训练网络,或许还是以下游任务的辅助挂件的地位而存在,Bert 的预训练网络则是下游任务的引擎。什么是引擎?加满油,装上轱辘就差不多能跑了。Bert 灌入超大规模数据作油,给下游任务预留好特殊接入锚点作为轱辘,它,跑起来了。与Elmo 的预训练相比,Bert 使用 Transformer 替代 LSTM 作为特征抽取器,实现了更有效的双向结构,除了语言模型之外还以预测下一句作为训练目标。Bert 的预训练结果如此强大,以至于下游任务只需要用单层全连接量级的模型来做Fine-Tune。超大的数据、巨大的网络、巧妙的预训练方法,造就 Bert 在 NLP 榜单上大杀四方、占领多个任务山头的战果。
“当你谈到Bert,请一定要想到我。”
GPT 和 Bert 神似,或者说 Bert 和GPT 神似,因为 GPT 实际出现在 Bert 之前。与 Bert 的相似在于,都是以预训练网络作为下游任务的引擎,都使用了超大规模的数据做预训练,都使用 Transfomer 作为特征抽取器,都对下游任务的输入做相似的重构。
数据集
Fine-Tune阶段的数据是各个任务上官方所提供的数据集,不必多言。这里只讲一讲预训练数据。GPT 使用 BooksCorpus 数据集,它包含了7000本书,共计 5GB 文字。这样超大的数据规模,是 GPT 成功的关键之一。Elmo 所使用的 1B Word Benchmark 数据集与之体量相当,但被重新整理成单句,因而丢失了长序列的样本,是它没有被 GPT 选用的原因。
模型
由图1来看看 GPT 的网络结构。这是一个典型的 Transformer Encoder, 包含 12 个堆叠的 block:selfattention + FF + LN。
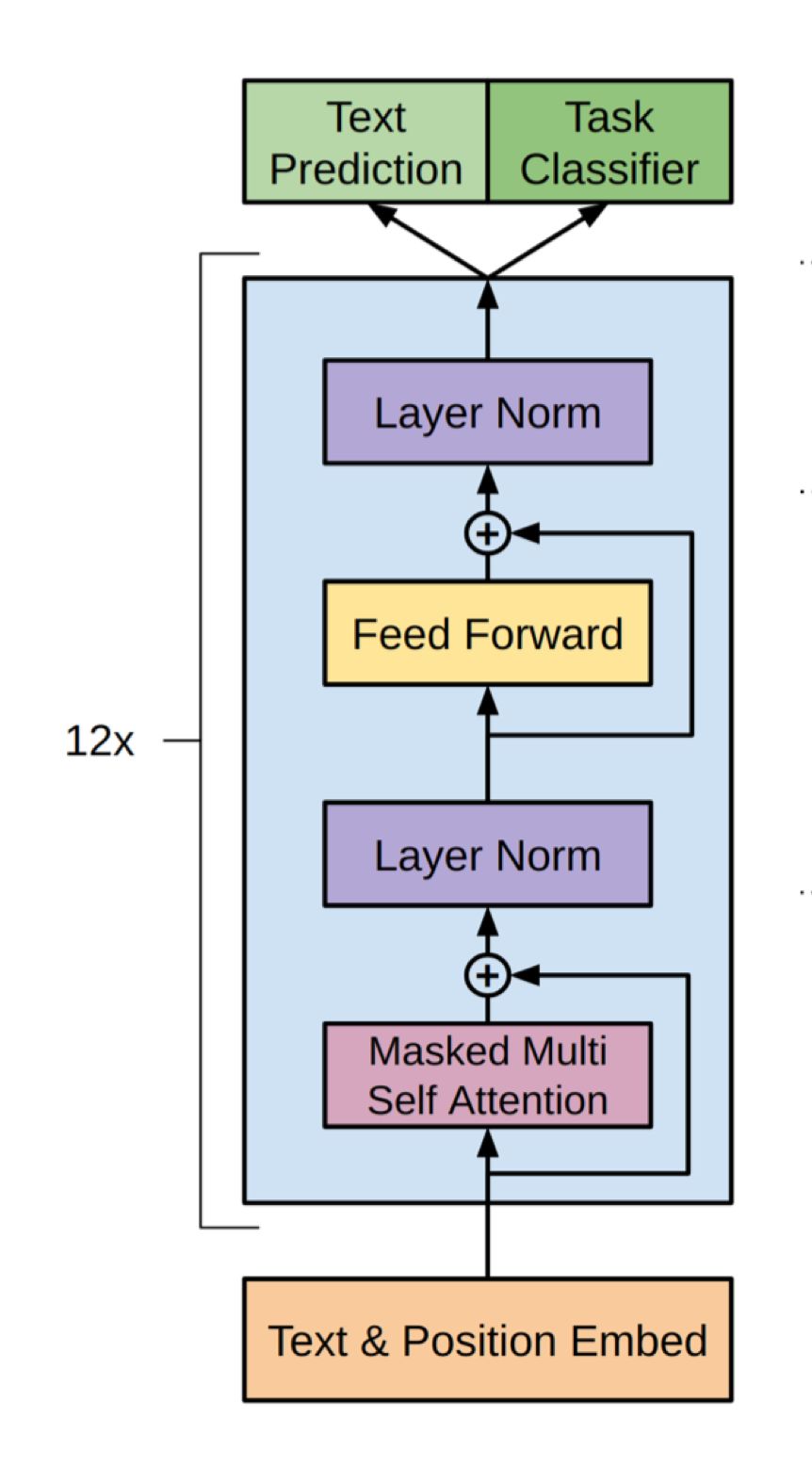
图1,GPT 的网络结构
>>> 预训练过程
在预训练阶段,只以语言模型为训练目标,即图中的 Text Prediction。公式1描述了这个典型的从左到右的语言模型:在给定上文的条件下预测下一个词。
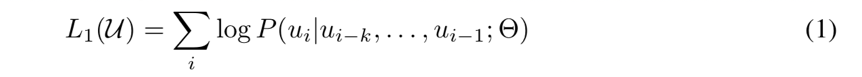
在公式2中,h0 表示网络第一个隐层,U 表示输入序列,We 表示 token embedding 矩阵,Wp 表示 position embedding。h1 到 hn 是各层 Transformer block 的输出隐层。最终以 sotfmax 计算下一个词的概率。
>>>Fine-Tune 过程
在 Fine-Tune 阶段,输入的样本是(序列 x1...xm,标签 y)。给定一个序列,预测标签的概率如公式3所示。
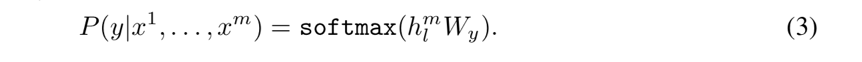
TaskClassifier 的训练目标是最大化全体有监督训练样本出现的概率,即图1中的 Task Classifier。
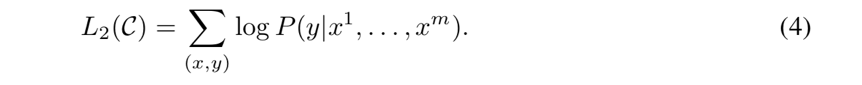
在这个阶段,语言模型的训练目标也被一并启用。
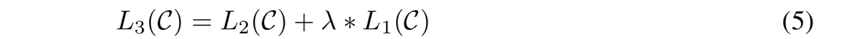
重新看一遍网络结构和 Fine-Tune 阶段的公式,就会发现,引入的参数,只有 Wy。这就是前面讲 Bert 所提到的,这个预训练,和别的辅助挂件哪怕是超级辅助挂件不同,是引擎。
但你可能又要说了,输入一个长长的序列,却只能得到一个单标签 y,能解决的下游任务岂不非常有限。不是,通过对输入序列进行重构,GPT 能够解决很多问题。图2描述了对于不同类型的任务如何去做输入重构,可以看出,它既可以解决分类这样单序列输入的问题,又可以解决像 QA 这样多个序列输入的问题。其中蓝色部分是特殊 token。
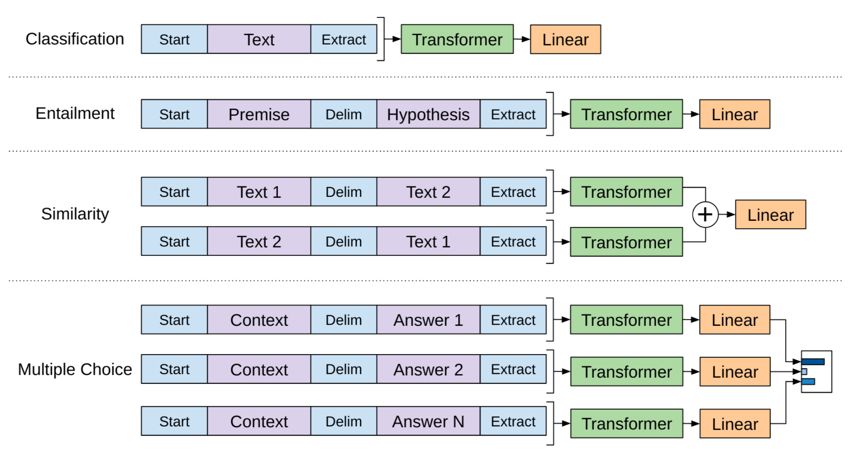
图2,重构输入以适应不同下游任务
GPT效果
GPT 战斗力拔群,战线也颇长。在其参与的15个测试集中,GPT 创下了12个新记录。这15个测试集覆盖了自然语言推理、语义相似分析、阅读理解、常识推理等多个任务类型。
在 COP、RACE、ROCStories 三个数据集上大幅拔高最佳纪录,意味着 GPT 在获取通识和掌握长段落方面很有天赋。因为这三个数据集是关于“常识推理”和“阅读理解”的,它们强烈依赖于广博的通识,和多句推理。值得一提的是,GPT 的输入序列可以长达 512。
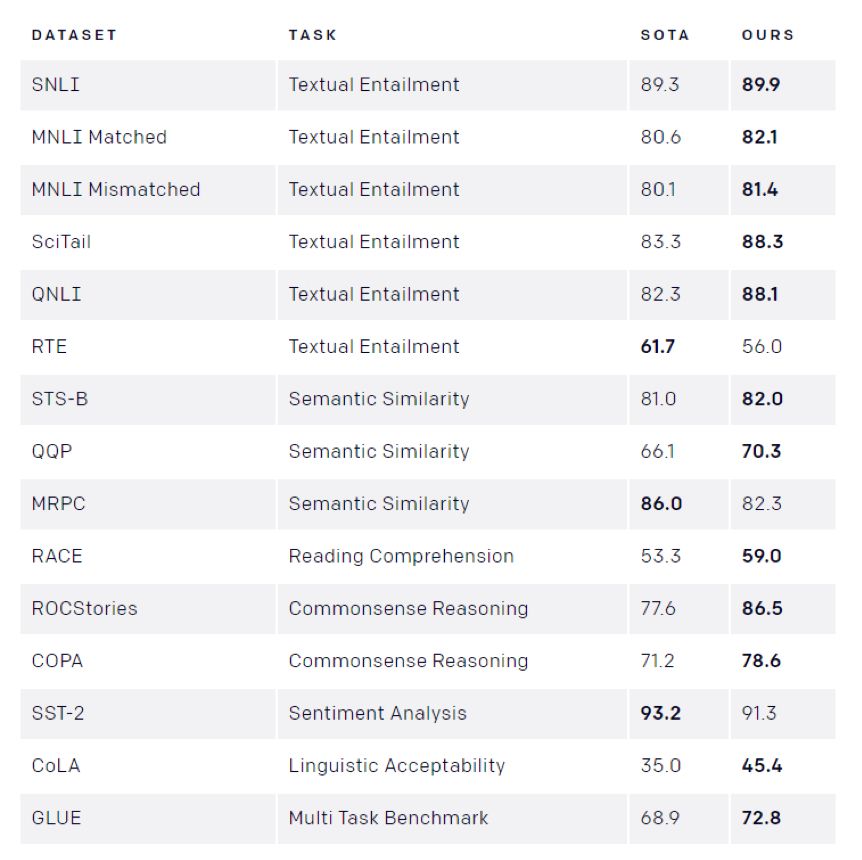
表2,GPT在多项 NLP 任务上超越前人
最难能可贵的是,GPT 极为简洁。要解决这么些不同任务,在 GPT 上的差别,仅仅在于构造输入序列的方式。也就是说,一旦站到了巨人的肩膀上,唯一需要做的就是睁开眼睛。
“说到巨人,我第一个不服”
15 亿参数,8百万网页共计 40GB 文本数据,要说 GPT-2 是第一巨人,恐怕没人不服。GPT-2 是 GPT 的直接高配版:10倍参数,10倍数据,把它叫 GPT-X 大概来得更直指人心。
GPT-2 训练,且只训练了一个无监督语言模型,不对任务做任何特殊 Fine-Tune。即便在这样的情况下,它依然强势刷新了很多语言模型的 benchmarks,在阅读理解、机器翻译、QA、和摘要方面也表现优良。
数据集
这是一个比更大还更大的数据集。GPT-2构造了一个新数据集,WebText。这些无监督样本,全部来自于 Reddit 的外链,而且是那些获得至少三个赞的外链,共计4500万链接。使用 Dragnet 和 Newspaper 两种工具来抽取网页内容。过滤 2017 年12月之后的网页。删去来自 Wikipedia 的网页。去重。最后还做一些琐碎的没有明说的所谓启发式清洗工作。如此得到8百万网页共计 40GB 文本数据。
WebText 数据集的特点在于全面而干净。全面性来源于 Reddit 本身是一个门类广泛的社交媒体网站。干净来源于作者的有意筛选,至少三赞意味着获取的外链是有意义的或者有趣的。
模型
为何把准备数据讲得这么详细?因为这几乎是实验以外唯一的工作。特别是在模型的改动上,几乎微乎其微。输入序列使用类似 BPE 的做法,序列最大长度从 GPT 的512再度增长至1024。将 Layer Normalization 从每个 Transformer block 的最后一层移到了第一层,并在最后一个 block 的最后叠加一个额外的 Layer Normalization。为模型参数做特殊的初始化。
效果
GPT-2 惊人的效果已经在开篇的续写案例和表1中体现了。这里将表1再贴一遍,以示敬意。注意到,标准模型 1542M 在8个测试集上斩获7个记录,而最小的模型 117M 也能在其中4个测试集上挑起大梁。而且牢记,GPT-2 没有 Fine-Tune,没有 Fine-Tune,以及没有 Fine-Tune。这是何等的暴力美学!
表1,GPT-2在语言模型任务上的表现惊人
作者观察到,GPT-2 在小数据集上表现突出,比如 PTB 和 WikiText2 它们只有1到2百万训练 token。
同时,GPT-2 也在长句数据集上表现突出,比如 LAMBADA 和 CBT。
唯有 1BW 测试集没有取得很好的效果,甚至按照参数规模增大和 PPL 降低的关系来看,GPT-2 永远不可能通过增大参数规模来企图赶超 SOTA。这根本原因是,1BW 也是一个庞然大集,前文提到它与 GPT 所采用的 4GB BooksCorpus 数据集体量相当,后者人为打破了长段落结构。这种关键方向上的差别,乘以两个数据集的巨大体量,或许导致模型具有极大偏置,再加上GPT-2 毫无 Fine-Tune,因而不如专门训练的 SOTA。
GPT-2 倔强地坚持仍然在无监督训练的条件下,参与非语言模型类的下游任务,包括阅读理解、机器翻译、QA、和摘要等。虽然没有达到 SOTA 的同等水平,甚至和 SOTA 还有不小距离,但完全无监督训练也表现超出预期,打出了自己的风采。
例如,在阅读理解任务 CoQA上,GPT-2 通过 greedy decoding 可以达到 51 F1 值,这已经超过了3个baseline 系统的表现,当然距离 Bert 创下的 91F1 仍然十分遥远。 另一个有趣的尝试是在机器翻译任务,GPT-2 只用数据集中那些形如“英语句子=法语句子”的样本来无监督训练语言模型,随后直接投入英法翻译的测试任务中。在 WMT-14 English-French 任务中取得 5 BLEU 的成绩,在 WMT-14 French-English 任务中取得 11.5 BLEU 的成绩,前者稍稍比按照双语词典逐字翻译差一点,后者可以超过好些无监督机器翻译的 baseline,但远远差于这项任务的 33.5 BLEU 的记录。
数据为王
相比于 GPT,GPT-2 在模型上几乎毫无建树,而它敢于以完全无监督的方式挑战各大任务,其底气就来自于更有效的数据。所谓的有效又指的是什么?
量大。只要数据大,什么任务都不怕。用足够量大的数据做训练,是深度学习称霸 NLP 任务的首功之臣,已经是从业者的一致观点。GPT-2 所利用的数据十倍于 GPT,高达 40GB。而它扩张模型参数也到 GPT 的十倍,不是目的,而是手段,是为了编码这十倍数据的手段。当然,GPT 所使用的 BooksCorpus、Elmo 使用的 1B word Benchmark、以及 Bert 所使用的 BooksCorpus + English Wikipedia,也都已经是超大的数据了。
广博。作者在 GPT 的论文中讲到,”我们所使用的 BooksCorpus 数据集是有偏的,真实世界自然语言的主题和表达方式都不全长成书本那样“。而到了 GPT-2,作者就解决了这一问题,Reddit 是一个覆盖主题十分广博、表达方式千千万万的数据来源。
干净。与BooksCorpus、1B word Benchmark、EnglishWikipedia 这些相对成熟的数据集相比,从 Reddit 里获取数据的所面临的一大问题,是数据质量参差不齐。因此,GPT-2 挑选 karma 至少三的内容,再做了一系列清理工作,就是为了让数据更加干净。
数据对于模型有多么重要,从GPT-2 那个没有成功拿下的任务也可以反面佐证。GPT-2 在 1B word Benchmark 上就落后 SOTA 不是一星半点,从正面戳中大数据量 Pre-Training 的命门——成也数据,败也数据。一方数据养一方模型,模型能力是一口数据一口数据喂大的,用长序列数据喂大的模型要去短序列数据集上挑战专门训练的 SOTA,也实在为难。当然,这样的论断也可能是武断的,因为 SOTA 是有监督的,而 GPT-2 若是加上有监督的 Fine-Tune,也未必不会超越 SOTA。
Pre-Training 或成为标配
想搞好 NLP 任务,就要先爬上大语言模型 Pre-Training 的肩膀,或许将成为从业者的共识。
在图像领域,基于Imagenet 预训练,再专攻下游任务,早已成为一种主流。人们对于深度学习能够抽取层次化特征的认知就来自于CNN 解决图像任务的原理:第一层抽取线条,第二层抽取轮廓……而以 Elmo 为开始的这些深层网络预训练,与 Imagenet 预训练何其相似。
汝果欲学诗,功夫在诗外。GPT-2 的作者在论文中讲到,无监督的语言模型也可以直接参与下游任务,因为本质上,有监督训练的最优解也正是无监督训练的最优解,而下游任务只是使用一个子集去验证而已。GPT-2 的论文标题是,“Language Models areUnsupervised Multitask Learners”,也正是这个意思。在大数据上训练得到的语言模型,甚至可以汲取数据中的广博知识,辅助下游任务,这一点在 GPT 的常识推理任务中就有优势体现。
那么,剩下的问题,就是如何能让模型收敛到那个最优解。
模型仍然是关键一步
答案或许是,利用越来越庞大的网络,编码越来越庞大的数据。而作者宣称,即便 GPT-2 在参数上十倍于 GPT,五倍于 Bert,却依然在 WebText 数据集上是欠拟合的。
网络越叠越大,也许没有尽头,而在找到更高效的网络之前,我们的最佳选择仍然是 Transformer。在 Elmo 使用两个双向 LSTM 做为预训练的核心部件之后,GPT、Bert、GPT-2无一例外选用了 Transformer。Transformer 因为使用 self-attention 而拥有跨度更长的视野,而这是 RNN 类模型一直以来的短板:RNN 饱受梯度消失和爆炸的困扰,虽然在 LSTM 和 GRU 中通过类似残差的连接得以缓解,但仍然不如 Transformer 来得彻底。要知道,GPT 两兄弟和 Bert 都能直接以篇章作为输入,而 Elmo 则只以句子作为输入。另一方面,RNN 类网络并行困难速度缓慢的问题,在 Transformer 中已经荡然无存。天下武功,无坚不摧,唯快不破。Glove 能够被更多人青睐,而它不见得比 Word2vec 效果好多少,就在于它快。快,意味着能在同样的时间内让预训练收敛到更优化的状态,在实际的生产系统中抢占更有利的位置。
而 Transformer 和 Transformer 也是不同的。为区别于 GPT,Bert 使用 Transformer 的方法从单向升级成双向。单向是指从左到右的单向语言模型,而双向则是既有上文也有下文的。Bert 的实验结果专门论证了这种双向的升级具有独特的优势。GPT 没有使用双向,一来模型的创新并非作者的重心所在,二来 Ber t的双向也实在颇有一番技巧。GPT-2 没用双向,或许是作者有意为之:“既然我要论证超大规模数据无监督预训练的有效,就干脆不要引入别的因素”。而作者在文章末尾也坦然承认,“我们曾用 GPT 的预训练加Fine-Tune 模式斩获一些新纪录,也有计划使用 GPT-2 加上 Fine-Tune 去挑战 Bert 所参与的那些测试,但对于更多数据带来的优势能否弥补单向之于双向的劣势,我们尤未可知”。
算力之殇
GPT 模型,产出于8块 P100 GPU,跑40个 epoch 需要一个月时间。
Bert-large,如果也用8块 P100 GPU,也跑40个 epoch,大概需要长达1年的时间。而它实际是在 TPU 上训练的,但也需要64块TPU 芯片耗时4天才能完成。
至于 GPT-2,没人提到过要用上多少块卡、消耗上多少时间,才能训练出如此的暴力美学。
参考:
[1] GPT-2,https://openai.com/blog/better-language-models/
[2] DeepFake,https://zh.wikipedia.org/wiki/Deepfake
[3] GPT, https://openai.com/blog/language-unsupervised/
[4] NNLM, http://www.jmlr.org/papers/v3/bengio03a
[5] Word2Vec, https://code.google.com/archive/p/word2vec/
[6] Glove, https://nlp.stanford.edu/projects/glove/
[7] Elmo, https://allennlp.org/elmo
[8] Bert,https://github.com/google-research/bert

微信ID:WeChatAI

登录查看更多
相关内容
Arxiv
15+阅读 · 2018年10月11日



相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日