OpenAI「假新闻」生成器GPT-2的最简Python实现
选自GitHub
机器之心整理
由 OpenAI 推出的文本生成模型 GPT-2 最近引发了人们的广泛关注,这种算法不仅在很多任务上超过了此前的最佳水平,还可以根据一小段话自动「脑补」出大段连贯的文本,并模拟不同的写作风格。它看起来可以用来自动生成「假新闻」。
然而这个 GPT-2 模型内含多达 15 亿个参数,过高的算力要求让大多数开发者望而却步。而且 OpenAI 还曾「出于对模型可能遭恶意应用的担忧,并不会立即发布所有预训练权重。」一时引发机器学习社区的吐槽。
近日,由 Buzzfeed 数据科学家 Max Woolf 开源的「GPT-2 精简版」出现在 GitHub 上。这是一个简单的 Python 软件包,它封装了 OpenAI GPT-2 文本生成模型(特别是它是具有 1.17 亿超参数的「较小」版本)的现有模型微调和生成脚本。此外,这个软件包让我们可以更容易地生成文本,生成一个文件以便于管理,从而允许前缀强制文本以给定的短语开头。
项目链接:https://github.com/minimaxir/gpt-2-simple

文本生成示意
该 Python 包包含以下内容,并对其进行了最小程度的低级更改:
来自 OpenAI 官方 GPT-2 库的模型管理(MIT 许可证)
来自 GPT-2 中 Neil Shepperd fork 的模型微调(MIT 许可证)
来自 textgenrnn 的文本生成输出管理(MIT 许可证)
为了微调,该项目强烈建议你使用 GPU,虽然你用 CPU 也可以生成(但速度会慢很多)。如果你在云端训练,强烈建议你使用 Colaboratory notebook 或带有 TensorFlow 深度学习图像的谷歌计算引擎 VM(因为 GPT-2 模型位于 GCP 上)。
你可以使用 gpt-2-simple 在这个 Colaboratory notebook 中免费用 GPU 来重新训练模型,该 notebook 还演示了这个软件包的其它功能。
Colaboratory notebook 地址:https://colab.research.google.com/drive/1VLG8e7YSEwypxU-noRNhsv5dW4NfTGce
安装
gpt-2-simple 可以通过 PyPI 来安装:
pip3 install gpt_2_simple
你还要为你的系统安装相应的 TensorFlow(如 tensorflow 或 tensorflow-gpu)
使用
将模型下载到本地系统的示例,在数据集上对它进行微调,然后生成一些文本。
警告:模型是预训练的,因此任何微调模型都是 500MB。
import gpt_2_simple as gpt2
gpt2.download_gpt2() # model is saved into current directory under /models/117M/
sess = gpt2.start_tf_sess()
gpt2.finetune(sess, 'shakespeare.txt', steps=1000) # steps is max number of training steps
gpt2.generate(sess)
生成模型的检查点默认在/checkpoint/run1 中。如果你想从该文件夹中加载模型并从中生成文本:
import gpt_2_simple as gpt2
sess = gpt2.start_tf_sess()
gpt2.load_gpt2(sess)
gpt2.generate(sess)
与 textgenrnn 一样,你可以用 return_as_list 参数生成并保存文本供以后使用(如 API 或机器人)。
single_text = gpt2.generate(sess, return_as_list=True)[0]
print(single_text)
如果你想在 checkpoint 文件夹中存储或加载多个模型,可以把 run_name 参数传递给 finetune 和 load_gpt2。
注意:如果你想在另一个数据集上进行微调或加载另一个模型,先重启 Python 会话。
gpt-2-simple 和其它文本生成程序的区别
GPT-2 用来生成文本的方法与 textgenrnn 等其它安装包(特别是纯粹使用 GPU 生成完整文本序列并随后对其进行解码的安装包)使用的方法略有不同,这些方法在没有破解底层模型代码的情况下无法轻易修复。
所以:
一般来说,GPT-2 更擅长在整个生成长度上维护上下文,从而能够有效地生成对话文本。文本在语法上通常也是正确的,并且有适当的大写和较少的打印错误。
原始 GPT-2 模型在大量来源的文本上进行训练,使该模型包含输入文本中看不到的趋势。
GPT-2 针对每个请求最多只能生成 1024 个 token(约是 3-4 段英语文本)。
GPT-2 在到达特定的结束 token 时无法提前停止。(暂时解决方法:将 truncate 参数传递给 generate 函数,以便只收集文本,直至到达特定的结束 token。你可能想适当地缩小 length。)
较高温度(如 0.7-1.0)能够更好地生成更有趣的文本,而其它框架在温度 0.2-0.5 之间运转更好。
当对 GPT-2 进行微调时,它并不清楚较大文本中文档的开头或结尾。你需要使用定制的字符序列来显示文档的开头或结尾。之后在文本生成中,你可以指定针对开始 token 序列的 prefix 和针对结束 token 序列的 truncate。
通过设置一个可分成 nsamples 的 batch_size,你可以使用 GPT-2 生成并行文本,从而加快生成速度。GPT-2 与 GPU 配合得很好(可以在 Colaboratory K80 上将 batch_size 设置为 20)!
计划工作
注意:除非需求另有规定,否则本项目的范围非常小。
允许用户生成超过 1024 个 token 的文本。
允许用户使用 Colaboratory 的 TPU 进行微调。
允许用户使用多个 GPU(如 Horovod)。
对于 Colaboratory,允许模型在训练期间自动将检查点保存至 Google Drive,以防止超时。
使用 gpt-2-simple 的示例
ResetEra:生成视频游戏论坛讨论
地址:https://www.resetera.com/threads/i-trained-an-ai-on-thousands-of-resetera-thread-conversations-and-it-created-hot-gaming-shitposts.112167/
项目创建者:Max Woolf
基于 GPT-2 的「故事生成器」
GPT-2 强大的模型不仅吸引了众多机器学习从业者的关注,其「脑补」故事的能力也让人们不禁有了很多大胆的想法。为了让更多人能够接触最新技术,另一个开发者 eukaryote 最近还推出了一个新网站:This Story Does Not Exist
链接:https://www.thisstorydoesnotexist.com/
这是一个基于 GPT-2 的文本生成器。在这里,每个人都可以输入一段文字,看看人工智能会给你讲一段什么样的故事,比如:
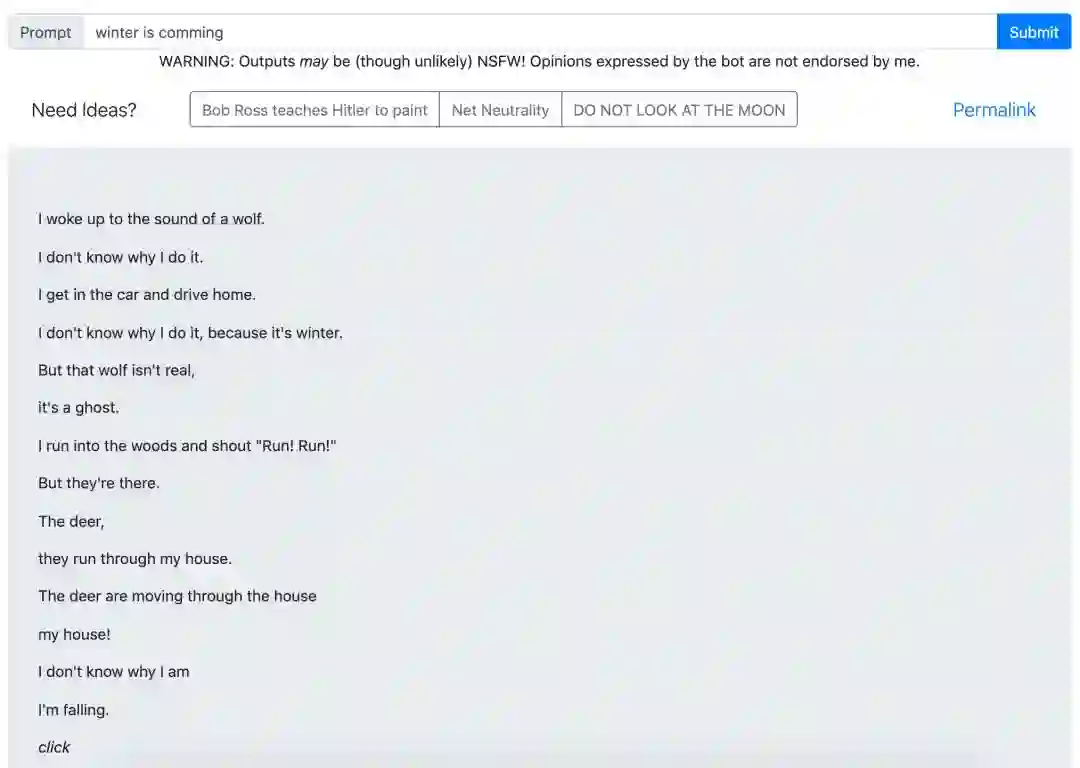
改写冰与火之歌的结局,就靠你了!

本文为机器之心整理,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


