赛尔原创 | Pointer Networks在自然语言处理领域中的应用
作者:哈工大SCIR硕士生冷海涛
1.引言
在自然语言领域中,seq2seq模型已经被应用到很多任务中并取得了一定的效果。但是对于seq2seq模型中的decoder部分,使用者必须预先定义好一个固定大小的output dictionary。这导致了seq2seq模型没有办法应用到一些由输入数据决定output dictionary的问题,比如组合问题。由此O Vinyals[1] 等人在2015年提出了基于attention机制的Pointer Networks模型来解决组合问题。
2.Pointer Networks 模型简介
和常规的seq2seq模型比较起来,Pointer Networks主要在decoder部分发生了变化。这里以LSTM为例。对于给定的训练对(P,Cp),其中P={P1,...Pn} 是n个向量组成的序列,Cp={C1,…,Cm(P)},其中m(P)的大小在1到n之间。同时,我们定义encoder和decoder的隐层分别为(e1,…,en)以及(d1,…,dm(P))。因而有:
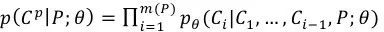
而我们的优化目标则是:
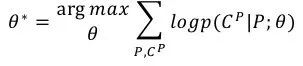
其中公式中的 θ 代表了模型中的参数。
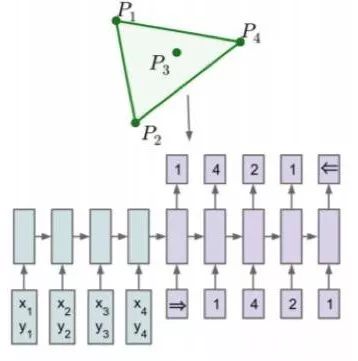
图1 seq2seq模型
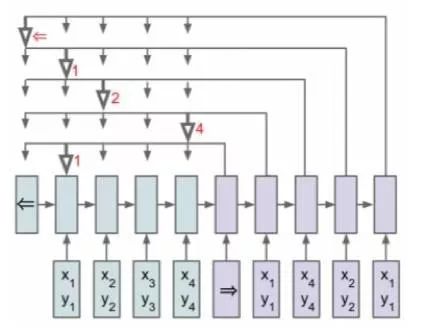
图2 Ptr-Net模型
在如图1这样的传统seq2seq模型中,我们使用了一个固定大小的softmax分布来计算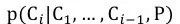
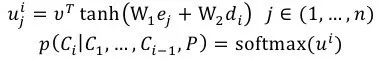
其中向量 ui 在经过 softmax 规范化后得到的概率分布便是基于输入内容的输出预测分布。公式中的v, W1, W2 都是可学习的参数。在这个过程中,我们直接使用得到的softmax结果去拷贝encoder对应的输入元素作为的decoder输入的向量。
3.Pointer Networks 在NLP上的应用
Ptr-Net最早提出来的时候,是用来解决旅行商、凸包等组合问题,但近两年来,Ptr-Net也广泛应用到NLP的各个任务上。
3.1文摘任务
以前大多数的extractive summarization 都是基于人工特征来完成的,而在ACL2016上,Cheng[2]等发表的Neural Summarization by Extracting Sentences and Words针对extractive summarization任务提出了data-driven的方法,在该论文中的模型分为了如图3所示的sentence level以及如图4所示的word level两个粒度。其中sentence level把问题看做了一个序列标签问题,每个句子分别标记上提取或者不提取。而对于word level问题,作者认为其是介于abstractive summarization和extractive summarization之间的一个生成问题,而生成的词局限于原文档中出现的词。本文将介绍word level这个模型。
图3 sentence level
图4 word level
如图3所示encoder部分使用了层次化的思想,先利用CNN从词语到句子,再利用RNN(LSTM)从句子到文档。下面详细介绍一下图4的decoder部分。在decoder中的第t步我们需要计算得到的是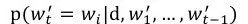
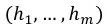
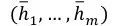
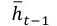
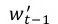
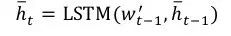
接着利用得到的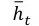
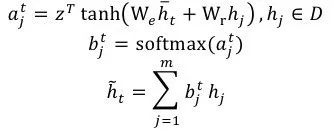
然后再利用通过attention操作得到的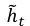
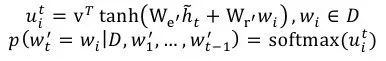
在上述公式中,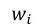
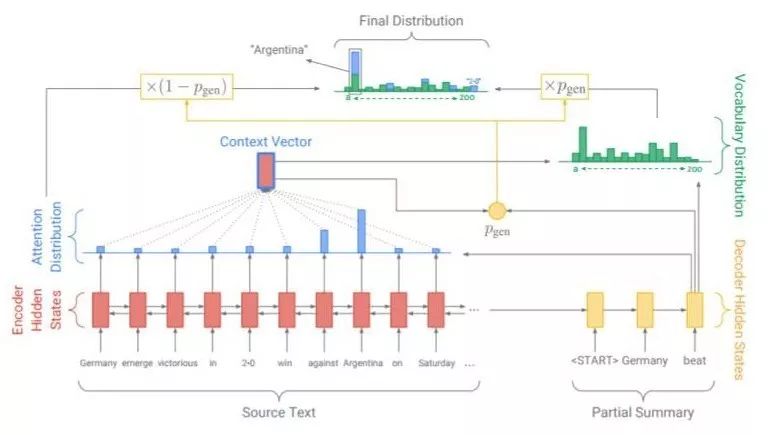
图5 pointer generator
而对于abstractive summarization,在ACL 2017发表的论文 Get To The Point: Summarization with Pointer-Generator Networks中,Abigail See[3]等人提出了pointer-generator。Pointer-generator混合了seq2seq+attention模型以及Pointer Networks模型,相比普通的seq2seq+attention模型,混合模型能够从原文中直接复制词语,因而可以提高摘要的准确率并处理OOV词语,同时还保留下了生成新词语的能力。如图5所示,在该混合模型中,词语的概率分布是由两部分组成的,即seq2seq模型softmax后的结果与Ptr-Net产生的概率分布叠加得到。
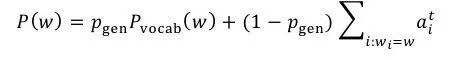
当w是一个OOV的时候,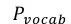
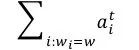
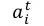
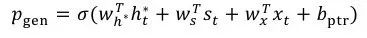
其中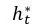
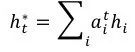
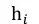
3.2信息抽取任务
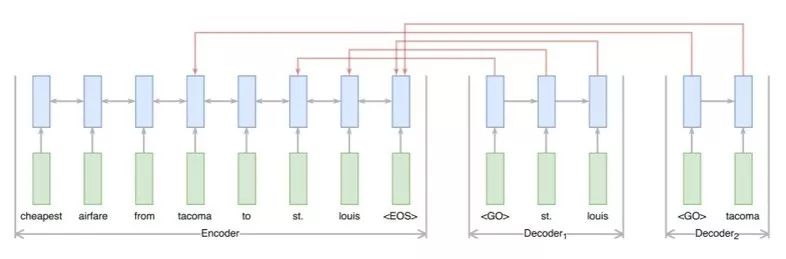
图6 信息抽取模型
大部分结果显著的信息抽取方法是依赖于token-level标签的,但是得到这些标签是费时费力的,并且这些标签作为一个中间步骤,并不是任务期望的输出结果。因而在2017年,RB Palm[4]等人提出了End-to-End的信息抽取方法,该方法基于Ptr-Net的思想,在没有使用token-level标签的情况下便得到了非常有竞争力的结果。如图6所示,该模型的输入是N个词语x = x1,…,xN,模型中使用了一个共享的encoder,但是decoder则是有多个的,每一个decoder对应一个需要被抽取得到的信息。用k=1,…,K 表示decoder的序号。在每一步j,每一个decoder都需要计算出一个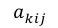
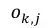
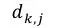
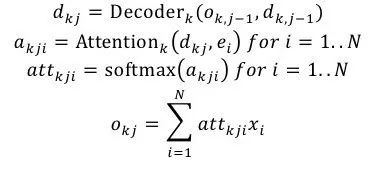
其中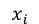
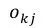
3.3句子排序任务
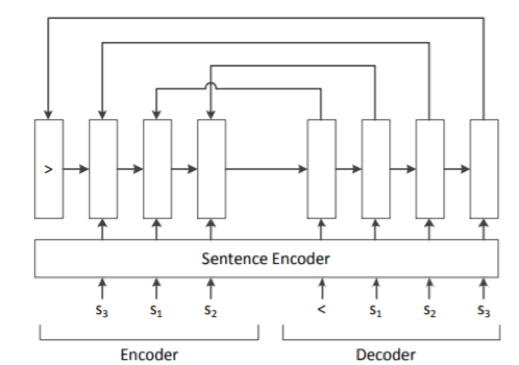
图7 句子排序模型
句子排序任务是把一系列的句子调整为连贯、可读性强的文本,是自然语言处理领域中十分重要而又困难的工作。一段好的文档是有很高的逻辑性和主题结构的,因而在许多任务当中都需要用到句子排序。L Logeswaran[5]和J Gong[6]等人,则提出了基于Ptr-Net的句子排序任务。如图7所示,模型的输入是若干句子 s=s1,…,sn,对于训练对(s,o),我们可以得到:
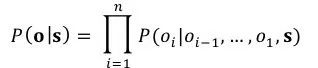
而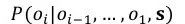
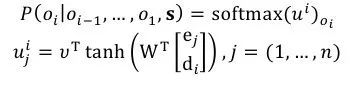
其中ej和di分别表示encoder第j步和decoder第i步的隐层。而v和W是可以学习的参数。而如图7所示中的sentence encoder部分则可以通过CNN, RNN等各种方法来完成。
4.结语
Ptr-Net的提出解决了传统seq2seq模型中output dictionary大小固定的问题。从其最初提出到现在,被应用到了NLP中的许多任务中,在一些任务中,Ptr-Net都完成了End-to-End的模型构建,避免了许多中间步骤,比如信息抽取以及句子排序,而在另外一些其他任务中,Ptr-Net则是很好的融入到生成模型中,将抽取机制带入生成模型中。根据已有工作,我们可以预期Ptr-Net在NLP任务中将会有较为广泛的应用前景。
5.参考文献
[1] Vinyals O, Fortunato M, Jaitly N.Pointer Networks. Computer Science, 2015.
[2] Cheng J, Lapata M. Neural Summarization by Extracting Sentences and Words. ACL2016.
[3] See A, Liu P J, Manning C D. Get To ThePoint: Summarization with Pointer-Generator Networks. ACL2017.
[4] Rasmus Berg Palm, Dirk Hovy, FlorianLaws, Ole Winther. End-to-End Information Extraction without Token-Level Supervision. SCNLP@EMNLP 2017 2017: 48-52
[5] Logeswaran L, Lee H, Radev D. Sentence Ordering using Recurrent Neural Networks. 2016.
[6] Gong J, Chen X, Qiu X, et al. End-to-EndNeural Sentence Ordering Using Pointer Network. 2016.
本期责任编辑: 丁 效
本期编辑: 刘元兴
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





