搞事!ICLR 2018七篇对抗样本防御论文被新研究攻破,Goodfellow论战
机器之心报道
机器之心编辑部
ICLR 2018 大会的接收论文中,8 篇有关防御对抗样本的研究中,7 篇已经被攻破了——在大会开幕三个月之前。来自 MIT 和 UC Berkeley 的研究者定义了一种被称为「混淆梯度」(obfuscated gradients)的现象。在面对强大的基于优化的攻击之下,它可以实现对对抗样本的鲁棒性防御。这项研究引起了深度学习社区的讨论,GAN 提出者 Ian Goodfellow 也参与其中,并作了反驳。
GitHub 链接:https://github.com/anishathalye/obfuscated-gradients
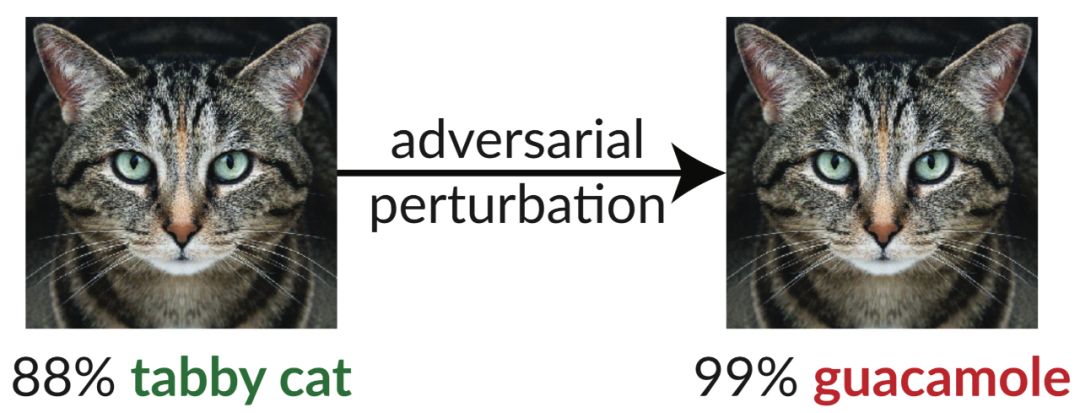
上图展示了一个「对抗样本」:仅仅加入了一些轻微的扰动,这张猫的图片就可以愚弄 InceptionV3 分类器,使其将图片分类为「鳄梨酱」。这类「欺骗性图像」可以轻松地利用梯度下降法生成(Szegedy et al. 2013)。
为了解决神经网络对抗样本的问题(Szegedy et al., 2013),近期人们对于构建防御对抗样本,增加神经网络鲁棒性的研究越来越多。尽管人们对于对抗样本的认识已经提升,相关的防御方法也有提出,但迄今为止并没有一种完整的解决方法出现。对于 MIT 和 UC Berkeley 的研究人员来说,目前正被审核的所有对抗样本防御论文中提到的方法(Papernot et al., 2016;Hendrik Metzen et al., 2017;Hendrycks & Gimpel, 2017;Meng & Chen, 2017;Zantedeschi et al., 2017)都可以被更加强大的优化攻击(Carlini & Wagner, 2017)击败。
基于迭代优化的对抗攻击测试基准如 BIM(Kurakin et al., 2016a)、PGD(Madry et al., 2018)和 Carlini 与 Wagner 的方法(Carlini & Wagner, 2017)近期已经成为评估防御能力的标准,最新的防御方式似乎能够抵御基于优化的最强攻击。
论文作者宣称他们找到了很多防御机制鲁棒地抵抗迭代攻击的一个普遍原因:混淆梯度。缺乏好的梯度信号,基于优化的方法就不能成功了。在论文中,作者确定了三种类型的混淆梯度。某些防御方式会导致破碎的梯度,有意地通过不可微分运算或无意地通过数字不稳定性,可以得到不存在或不正确的梯度信号。一些防御是随机性的,导致依赖于测试时间熵的随机梯度(攻击者无法接触)。另一些防御会导致梯度消失/爆炸(Bengio et al., 1994),导致无法使用的梯度信号。
研究人员提出了克服这三种现象造成的混淆梯度的新技术。在研究中,一种被称为后向传递可微近似(Backward Pass Differentiable Approximation)的方法解决了不可微分运算导致的梯度破碎。我们可以使用 Expectation Over Transformation 计算随机防御的梯度(Athalye et al., 2017),通过再参数化和空间优化来解决梯度消失/爆炸问题。
为了调查混淆梯度的普遍程度,并了解该攻击技术的适用性,研究人员使用 ICLR 2018 接收论文中的防御对抗样本论文作为研究对象,研究发现混淆梯度的使用是一种普遍现象,在 8 篇论文里,有 7 篇研究依赖于该现象。研究者应用新开发的攻击技术,解决了混淆梯度问题,成功攻破其中的 7 个。研究人员还对新方法对这些论文的评估过程进行了分析。
此外,研究者希望这篇论文可以为对抗样本方向提供新的知识基础、攻击技术解释,避免未来的研究落入陷阱,帮助避免未来的防御机制轻易被此类攻击攻破。
为了保证可复现,研究人员重新实现了 8 篇防御研究的方法,以及对应的攻击方法。下表展示了这 8 篇防御研究方法在攻击下的稳健程度:
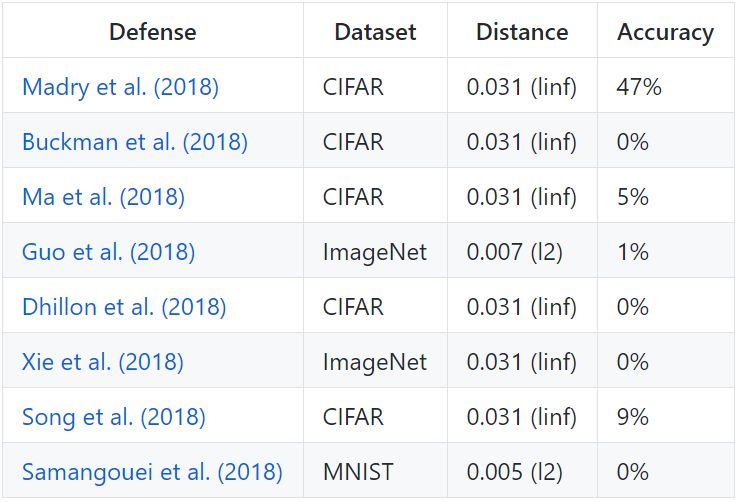
七篇论文中,我们能够看到唯一一个显著提高对抗样本防御鲁棒性的研究是论文《Towards Deep Learning Models Resistant to Adversarial Attacks》(Madry et al. 2018),如果不使用威胁模型以外的方法就无法攻破它。即便如此,这种方法也已被证明难以扩展到 ImageNet 的规模(Kurakin et al. 2016)。其他论文全部或多或少地依赖于「混淆梯度」。标准攻击应用梯度下降使网络损失最大化,为给定图片在神经网络中生成对抗样本。这种优化方法需要有可用的梯度信号才能成功。基于混淆梯度的防御会破坏这种梯度信号,使得优化方法失效。
研究人员定义了三种基于混淆梯度的防御方式,并构建了绕过它们的攻击方法。新的攻击方式适用于任何有意或无意的,不可微分运算或其他阻止梯度信号流经神经网络的防御法。研究人员希望未来研究能够基于这种新提出的方法进行更加有效的安全评估。

图 1. 不同失真水平的等级。第一行:正常图像。第二行:对抗样本,失真=0.015。第三行:对抗样本,失真=0.031
讨论
在对 ICLR 2018 的几篇论文攻击成功之后,是时候来对评估防御对抗样本方法的新规则了。MIT 和 UC Berkeley 的研究人员给出的建议仍然大体遵循前人的研究(Carlini & Wagner, 2017a;Madry et al., 2018)。
6.1 定义(逼真的)威胁模型
构建防御时,定义限制对抗样本的威胁模型非常关键。之前的研究使用单词 white-box、grey-box、black-box 和 no-box 来描述威胁模型。
本论文作者没有再次尝试重新定义词汇,而是概括防御的多个方面,它们对于对抗样本可能是已知的,但对于防御样本是未知的:
模型架构和权重;
训练算法和数据;
带有随机性的防御对抗样本,不管对抗样本是否知道所选随机值的确切序列或者仅仅是分布;
假设对抗样本不知道模型架构和权重,查询访问被允许。那么模型输出为 logits、概率向量或预测标签(即 arg max)。
尽管对抗样本的很多方面可能是未知的,但威胁模型不应该包含非逼真的约束。研究者认为任何有效的威胁模型都是对模型架构、训练算法所知甚少的,并且允许查询访问。
研究者认为限制对抗样本的计算能力并无意义。如果两个防御对抗样本具备同样的鲁棒性,但其中一个生成对抗样本需要一秒,另一个需要十秒,则鲁棒性并未提高。只有当对抗样本的计算速度比预测运行时有指数级提升时,将运行时作为安全参数才是可行的。但是,把攻击时间增加几秒并无太大意义。
6.2 研究结果应具体且可测试
定义完清晰的威胁模型之后,防御应该具体而可测试。例如,这些防御方法可以声称在失真度=0.031 时,对抗样本的鲁棒性为 90% 至最大,或声称平均两种对抗样本的失真度增加了基线模型的安全程度(在这种情况下,基线模型需要有明确的定义)。
不幸的是,研究者评估的大多数防御方法仅声明鲁棒性而未给出特定界限。这个建议最大的缺陷就是防御不应声称对无界攻击具备彻底的鲁棒性:不限制失真度,则任何图像可以随意转换,且「成功率」为 100%。
为了使防御声明可测试,防御必须是完全具体的,并给出所有超参数。发行源代码、预训练模型以及论文也许是使声明具体的最有效方法。8 篇论文中有 4 篇具有完整的源代码(Madry et al., 2018; Ma et al., 2018; Guo et al., 2018; Xie et al., 2018)。
6.3 评估自适应攻击(adaptive attack)
加强对现有攻击的鲁棒性(同时又是具体而可测试的)用处不大。真正重要的是通过具有防御意识的攻击积极评估自身的防御以证明安全性。
具体而言,一旦彻底认定一个防御,并且对手受限于威胁模式之下,攻克这一防御的尝试就变的很重要。如果它能被攻克,那么就不要设法阻止特定的攻击(即通过调整超参数)。一次评估之后,可接受对防御的调整,但调整之后要接受新的攻击。这样,通过最终的自适应攻击得出评估结果就类似于在测试数据上评估模型。
论文:Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples

论文链接:https://arxiv.org/abs/1802.00420
摘要:我们发现了一种「混淆梯度」(obfuscated gradient)现象,它给对抗样本的防御带来虚假的安全感。尽管基于混淆梯度的防御看起来击败了基于优化的攻击,但是我们发现依赖于此的防御并非万无一失。对于我们发现的三种混淆梯度,我们会描述展示这一效果的防御指标,并开发攻击技术来克服它。在案例研究中,我们试验了 ICLR 2018 接收的 8 篇论文,发现混淆梯度是一种常见现象,其中有 7 篇论文依赖于混淆梯度,并被我们的这一新型攻击技术成功攻克。
「混淆梯度」引发争议
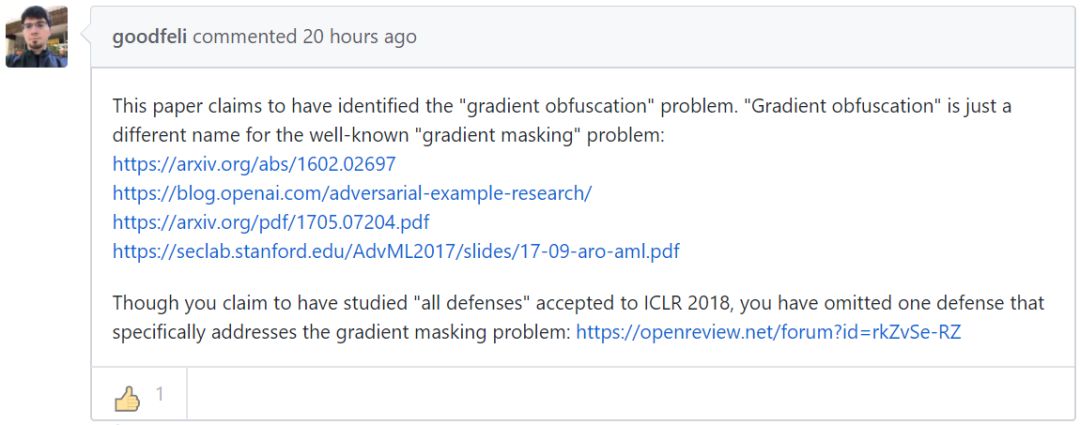
这篇论文甫一出现,立刻引起了研究社区的关注,GAN 提出者 Ian Goodfellow 也参与了讨论。Goodfellow 指出「混淆梯度」的概念实际上与此前人们提出的「梯度遮蔽(gradient masking)」概念相同。同时 ICLR 2018 中的一篇论文《Ensemble Adversarial Training: Attacks and Defenses》(Goodfellow 也是作者之一)实际上解决了这一问题。不过,这一观点并未被 MIT 与 UC Berkeley 的论文作者完全接受。
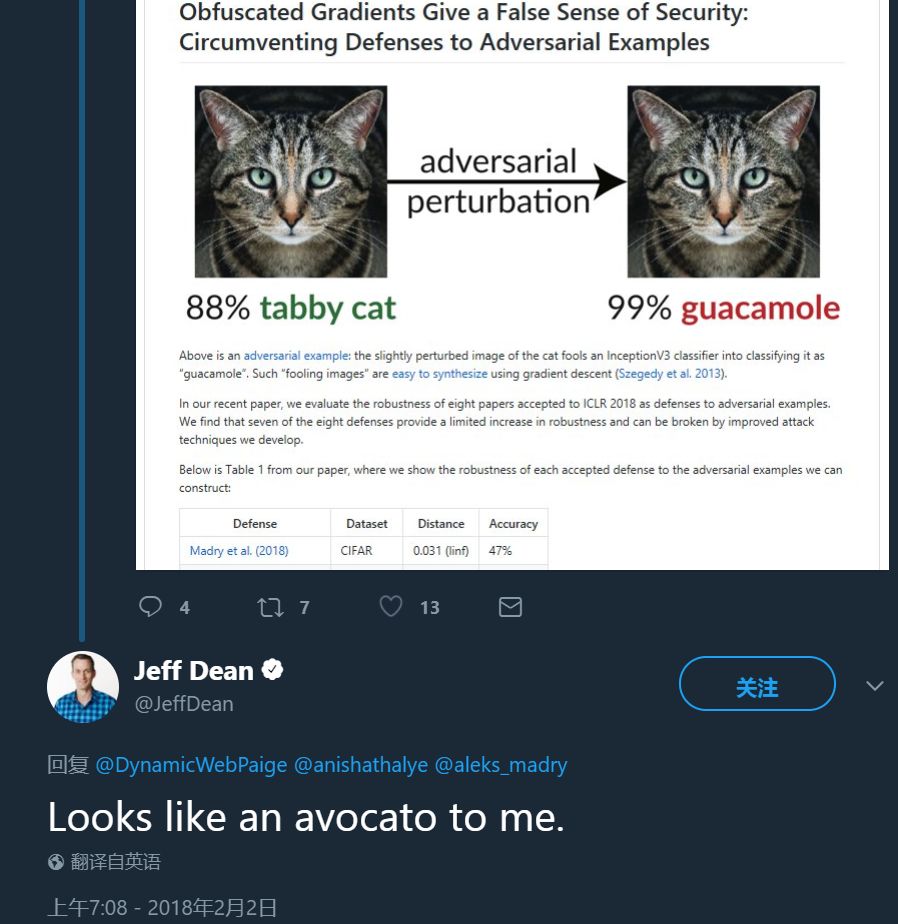
该研究也引发了谷歌大脑负责人 Jeff Dean 的关注与吐槽:「这看上去确实是鳄梨啊。」
新研究的第一作者,MIT 博士生 Anish Athalye 致力于研究防御对抗样本的方法。也是此前「3D 打印对抗样本」研究的主要作者(参见:围观!MIT科学家调戏了谷歌图像识别网络,后者把乌龟认成来福枪)。多篇 ICLR 接收论文在大会开始三个月前就遭反驳,看来,人们在防御对抗样本的道路上还有很长一段路要走。

本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com