一行代码提升迁移性能 | CVPR 2020

只需要一行代码,立刻提升迁移性能。
这就是我们出的新方法:批量核范数最大化(Batch Nuclear-norm Maximization)。

论文原址:https://arxiv.org/pdf/2003.12237.pdf
-
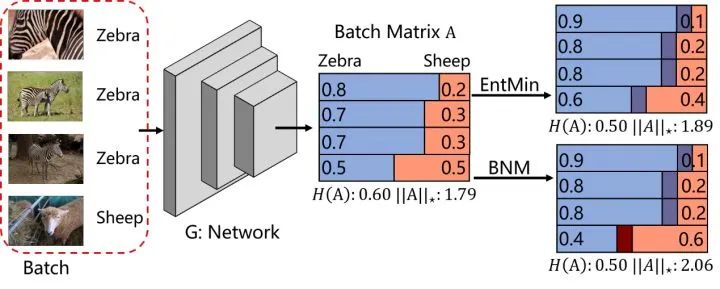
判别性
-
[0.9,0.1]判别性较高, -
[0.6,0.4]判别性较低。
-
多样性
-
[0.9,0.1]与[0.1,0.9]线性无关, -
[0.9,0.1]与[0.8,0.2]近似线性相关。
-
BNM
-
核范数与F范数相互限制界限, -
核范数是矩阵秩的凸近似。
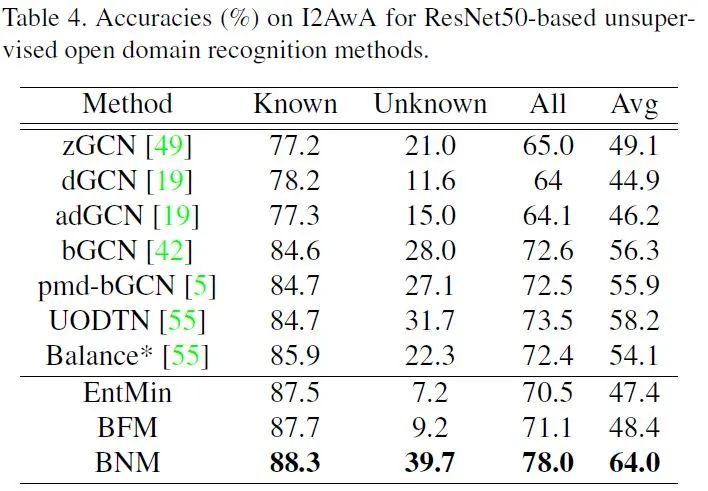
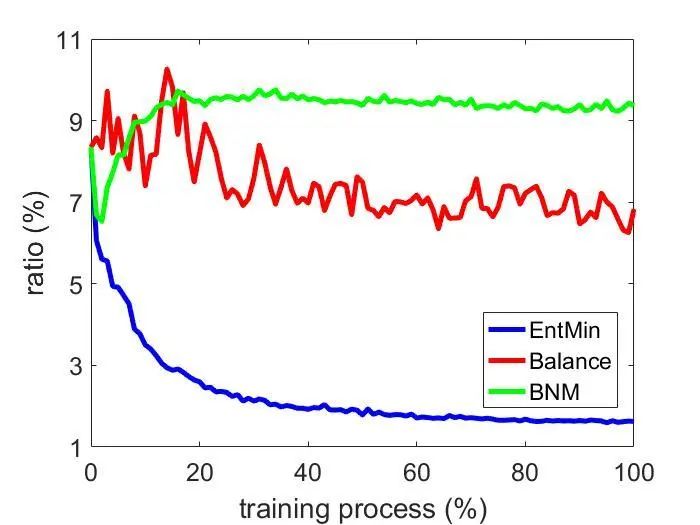
L_BNM = - torch.norm(A,'nuc')L_BNM = -tf.reduce_sum(tf.svd(A, compute_uv = False))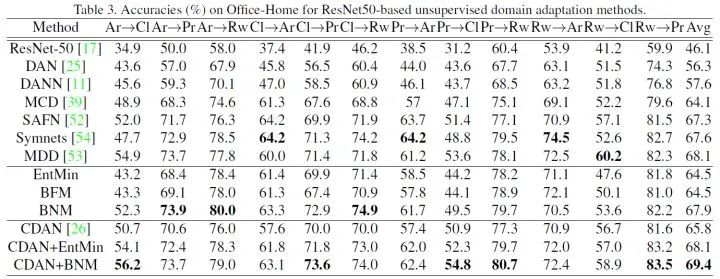
点击“阅读原文” 查看往期直播回放视频
登录查看更多
相关内容

Arxiv
4+阅读 · 2019年4月15日



相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年4月15日