ACL 2022 | 腾讯AI Lab入选20篇论文:写作助手和交互翻译背后的技术创新
感谢阅读腾讯AI Lab微信号第146篇文章。本文介绍腾讯 AI Lab 被 ACL 2022 收录的研究成果。
国际最受关注的自然语言处理自然语言处理(NLP)顶级会议 ACL 2022 于今年 5 月 22 日至 27 日举行,包括爱尔兰都柏林的线下会议及线上会议两部分。
腾讯 AI Lab 共有 20 篇论文被收录(含 5 篇 findings),涵盖对话与文本生成、机器翻译、文本理解、语言模型等方向。本文为部分入选论文解读。
腾讯 AI Lab 自然语言处理团队的研究内容囊括从自然语言理解到生成的整个链条,及对 AI 系统可解释性以及算法底层机制等理论研究,并持续向 NLP 及 AI 社区分享其领先研究成果。此前已发布多项系统及数据:
https://texsmart.qq.com/
https://transmart.qq.com/
https://effidit.qq.com/
https://ai.tencent.com/ailab/nlp/zh/embedding.html
对话与文本生成
1. 一种独立于模型的个性化对话生成数据处理方法
A Model-Agnostic Data Manipulation Method for Persona-based Dialogue Generation
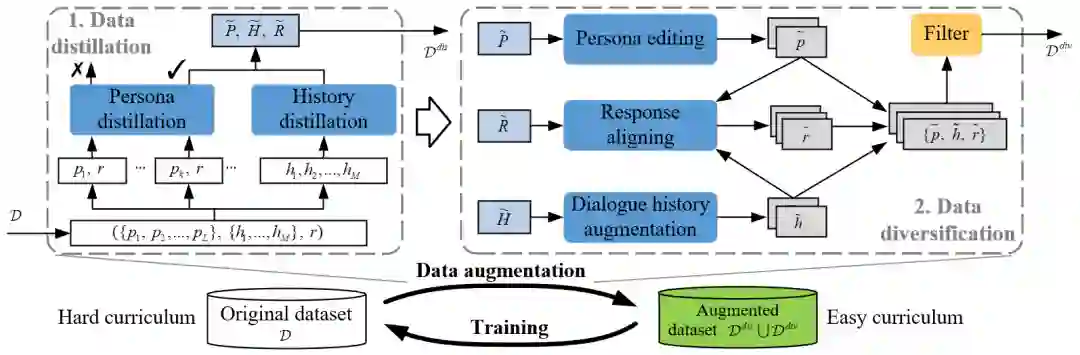
本文由腾讯AI Lab主导,与悉尼大学合作完成。为了更好地构建智能对话机器人,越来越多的研究开始考虑把显式的人物个性信息包含到生成模型中。但是这类人物个性化对话的数据大小通常受限,进而限制了直接使用现有数据所训练出的对话生成模型的性能。本文作者认为,此类任务中数据上的挑战主要来源于两个方面:首先,收集此类数据来扩充现有数据集的代价很大;其次,该数据集中每一个样本的学习难度都要比传统对话数据更高。
因此,本文针对以上两点问题,提出了一种新的个性化对话数据处理方法,该方法独立于模型因此可以和任意一种个性化对话生成模型结合进而提升其性能。本文首先对原始数据样本进行蒸馏,剔除难以学习的样本进而让模型可以更容易地拟合蒸馏后的样本分布。之后,使用多种不同的方法来有效地增强蒸馏后的样本,使其变得更多样进而缓解其数量不足的问题。最后,目标模型会使用我们构建的数据课程进行训练,即先在增强后的蒸馏数据上进行训练,之后再在原始样本上进行训练。
实验表明,该方法可以有效地提升两种对话生成模型(Transformer和GPT2)在此类任务上的性能。
2. 基于词汇知识内化的神经网络对话生成
Lexical Knowledge Internalization for Neural Dialog Generation
本文由腾讯AI Lab主导,与香港大学,华东师范大学,上海人工智能研究院合作完成。本文提出使用知识内化的方法来把词汇知识嵌入补充到神经对话模型当中。相较于基于知识的对话模型直接依赖于一个外部检索到的知识,该方法尝试将关于每个输入单词的词汇知识嵌入到对话模型的参数当中。为了应对规模巨大的词汇知识,本文采用了对比学习的方法,并利用维基百科的弱监督信息构建了一个词级别的词汇知识检索器。该方法在多个数据集和模型架构上验证了有效性。
3. 迈向抽象而接地的播客转录文本摘要
Towards Abstractive Grounded Summarization of Podcast Transcripts
本文由腾讯AI Lab主导,与中佛罗里达大学合作完成。播客最近迅速普及,播客转录文本的摘要对内容提供者和消费者都有实际好处,可以帮助消费者快速决定是否会收听播客,并减少内容提供者编写摘要的认知负担。然而,播客摘要面临重大挑战,包括与输入相关的事实不一致。口语记录中的语音不流畅和识别错误加剧了这个问题。
本文探索了一种新颖的抽象摘要方法来缓解这些挑战。具体来说,我们的方法学习生成一个抽象的摘要,同时将摘要段对应转录的特定部分,以允许对摘要细节进行全面检查。我们在大型播客数据集上对所提出的方法进行了一系列分析,并表明该方法可以取得了可观的结果。接地的摘要在定位包含不一致信息的摘要和转录片段方面带来了明显的好处,从而显著地在自动和人工评估指标,都提高了摘要质量。
4. 边讲边学:基于叙事预训练的零样本对话理解
Learning-by-Narrating: Narrative Pre-training for Zero-Shot Dialogue Comprehension
本文由腾讯AI Lab主导,与北卡罗来纳大学教堂山分校合作完成。对话理解需要捕获话语中的各种关键信息,这些信息有可能分散于多轮对话的不同位置或者隐含在话语中。因此,对话理解模型需要综合多种自然语言理解能力,例如复述、总结、常识推理、隐含知识推理等。
本文提出了一个“边讲边学”(leaning-by-narrating)的预训练策略。该策略通过在预训练过程中引导模型对输入对话的内容进行叙述,从而使模型学习并理解对话中的关键信息。然而,目前还没有公开的大规模对话-叙述平行语料库能够支持这种预训练策略。为此,我们首先收集了大量电影字幕及情节摘要数据,通过将二者进行自动切分和对齐,从而构建了一个对话-叙述平行语料库-DIANA。然后,在该语料库上对模型进行生成式预训练,并在四个对话理解的下游任务中对模型性能进行评估。
实验结果表明,该模型在零试学习的场景下性能显著优于先前的模型。同时发现DIANA中蕴含着多种类型的知识,可以提高模型在多种细粒度对话理解层面的能力。

5. 开放式文本生成的事件转换路径规划
Event Transition Planning for Open-ended Text Generation
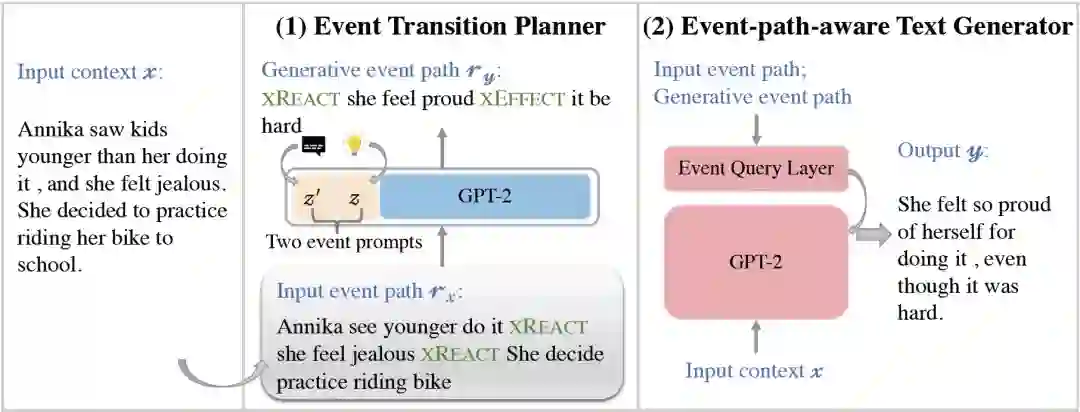
本文由腾讯AI Lab主导,与香港大学、山东大学、上海人工智能研究院合作完成,被会议接收为Findings长论文。开放式文本生成任务,例如对话生成和故事完成,需要模型在有限的先前上下文中生成连贯的延续,给当今的神经自回归文本生成器带来了新的挑战。尽管这些神经模型擅长生成流畅的文本,但它们很难建模给定上下文中的事件与可能发生的事件之间的因果关系。
为了弥合这一差距,本文提出了一种新颖的两阶段方法,可明确地建模开放式文本生成中的事件转移规划。该方法可以理解为一种经过特殊训练的从粗到细的算法,其中事件转换规划器提供“粗略”的事件骨架,而第二阶段的文本生成器会细化骨架。在两个开放式文本生成任务上的实验表明,该方法在连贯性和多样性方面有效地提高了生成文本的质量。
机器翻译
1. 弥合无监督神经机器翻译训练和推理之间的数据差距
Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation
本文由腾讯AI Lab主导,与上海交通大学合作完成。作为无监督神经机器翻译的重要组成部分,回译利用目标语言的单语数据生成伪平行数据。无监督神经机器翻译模型在这些源端是翻译句子的伪平行数据上进行训练,但往往对自然书写的源端文本进行翻译推理。源端数据在训练和推理之间的差异阻碍了无监督神经机器翻译模型的翻译性能。
通过精心设计的实验,我们确定了源端数据差异性的两个代表性特征:(1)风格差异(即翻译与自然文本风格)导致较差的泛化能力;(2)内容差异诱使模型产生偏向目标语言的幻觉内容。
为了缩小这种数据差异,我们提出了一种在线的自训练方法,它同时使用{自然的源端句子,翻译的目标端句子}的伪平行数据来模拟推理的场景。在多个广泛使用语言对上的实验结果表明,我们的方法通过弥补风格和内容上的差距,超过了两个强基线模型(XLM和MASS)。
2. 理解和提高针对机器翻译的序列到序列预训练模型
Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation
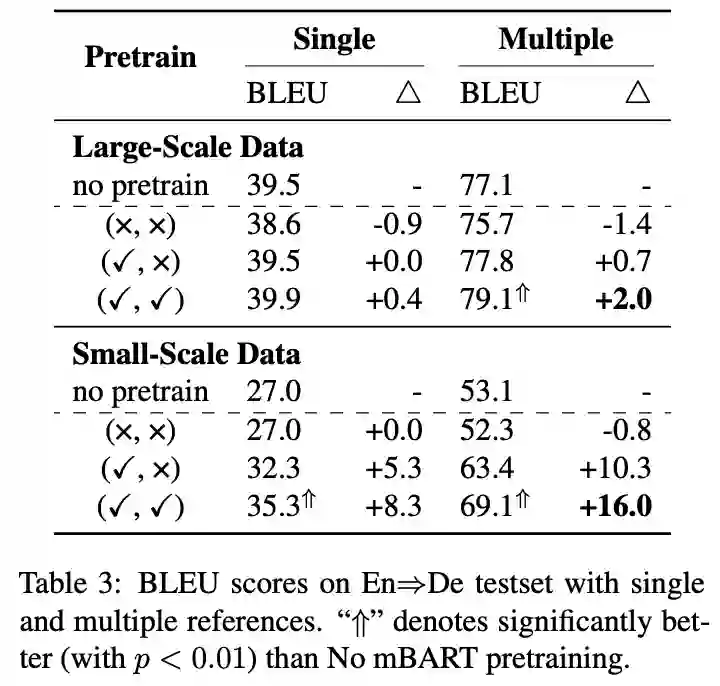
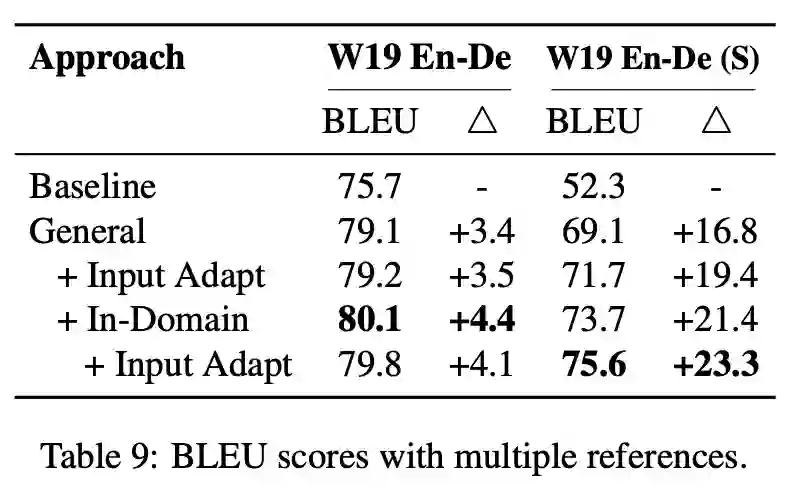
本文由腾讯AI Lab主导,与香港中文大学和阿尔伯塔大学合作完成。本研究旨在理解和改进针对机器翻译系统的序列到序列的预训练研究,特别是针对预训练解码器。我们发现序列到序列的预训练是一个双刃剑:一方面这个模块可以提高翻译模型的译文的准确性和多样性;另一方面,由于预训练和下游翻译任务的不同,预训练解码器会引入生成风格的偏移以及过度自信的问题,从而限制模型性能。
基于以上的发现,我们提出了两种简洁而有效的方法来提高预训练模型在下游翻译任务上的表现,包括领域内预训练和输入自适应。前者将预训练模型在领域内单语数据上继续训练,从而缩小预训练模型与下游翻译任务数据分布上的差异。后者对下游翻译任务的输入数据进行加噪,并将加噪数据与原始数据混合训练翻译任务模型,从而更好的将预训练模型的知识迁移到下游翻译任务模型。我们在多个翻译任务上进行了实验,验证了我们的方法可以有效地提高模型翻译效果和鲁棒性。
3. BiTIIMT:一种基于双语文本填充的交互式机器翻译方法
BiTIIMT: A Bilingual Text-infilling Method for Interactive Machine Translation
本文由腾讯AI Lab主导,与南京大学合作完成。交互式机器翻译(INMT)通过人工干预,可以保证高质量的译文输出。现有的交互式系统通常采用约束解码算法(LCD):它可以采用一种灵活的方式进行翻译,从而避免了自左向右翻译范式的约束。然而,由于约束解码的原因,这种交互系统在翻译效率和翻译质量上存在明显的不足。
本文提出了一种新颖的交互翻译系统,即基于双语文本填充的交互翻译模型。它的基本思想是一个双语文本填充(BiTI)任务:对于给定的源语言和人工校对的翻译译文片段,自动地进行句子填充从而获得更好的译文。通过将这个任务转化为序列到序列的任务,本文提出了一种简单有效的方法来进行实现。这种实现方法的优势是,它的解码效率与标准NMT的效率相同,而且它可以充分地利用人工校对的信息进行准确的词预测。
实验结果表明,该方法在翻译质量、效率和一致性上都优于词约束解码方法。
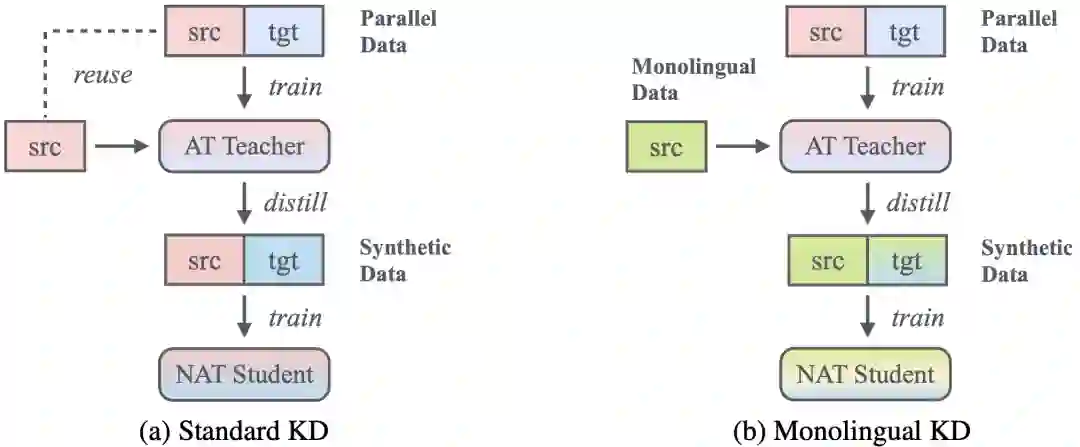
4. 低频词重分布:充分利用单语数据增强非自回归翻译
Redistributing Low-Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
本文由腾讯AI Lab主导,悉尼大学合作完成。知识蒸馏(KD)是训练非自回归翻译(NAT)模型的首要步骤。它可以简化NAT的模型训练,但代价是丢失翻译低频词的重要信息。本文提出了一个有吸引力的替代方案:单语KD。该方案利用从原始平行数据训练的AT老师来蒸馏额外的单语数据,从而训练AT学生。单语KD能够将原始双语数据的知识(隐式编码在AT教师模型中)和新的单语数据知识传递到NAT学生模型。在8个WMT基准数据集上对2个先进的NAT模型进行的大量实验表明,单语KD通过改善低频词翻译而始终优于标准KD方法,且不引入任何计算开销。
同时,单语KD具有良好的可扩展性,当给定更多计算开销,其可以通过与标准KD融合、反向单语KD融合或扩大单语数据规模来进一步增强。大量的分析表明,这些技术可以有效地融合,从而进一步召回在标准KD中丢失的有用信息。令人鼓舞的是,我们的方法融合标准KD后,在WMT14英-德和德-英数据集上分别获得了30.4和34.1 BLEU值。
该项工作的代码和模型已开源:
https://github.com/alphadl/RLFW-NAT.mono
5. 可视化模型学习到的语言学信息和任务性能之间的关系
Visualizing the Relationship Between Encoded Linguistic Information and Task Performance
本文由腾讯AI Lab主导,与中国科学技术大学和日本奈良先端科学技术大学合作完成,被会议接收为Findings长论文。Probing是一种很流行的方法,它可以分析一个训练好的神经网络模型是否学习到语言学信息,但是,它无法回答改变模型学习到的语言学信息是否会影响任务的性能。为此,本文从帕累托最优的角度出发,研究语言学信息与任务性能之间的动态关系。它的基本思想是尝试解决这样一个优化问题:优化出一个模型参数的子集使得它的每个元素都满足语言学信息和任务性能两方面的近似最优性。据此,本文将这个问题转化为一个多目标优化问题,并提出了一个方法来优化帕累托最优的模型参数子集。
本文在两个自然语言处理的主流任务上(机器翻译和语言模型)进行了实验,并展示了多种不同语言学信息与任务性能之间的关系。实验结果表明,本文提出的方法优于一个基线方法。同时,经验结果表明适量的句法信息有利于两个任务,但是更多的信息未必导致更好的任务性能,因为模型的结构也是一个重要的因素。
6. 机器翻译自动度量评价中的数据变化性问题
Investigating Data Variance in Evaluations of Automatic Machine Translation Metrics
本文由腾讯AI Lab主导,与中国科学技术大学,日本奈良先端科学技术大学和意大利特伦托大学合作完成,被会议接收为Findings短论文。在度量评价时,往往关注一个领域的单个数据集;比如,每年WMT度量评价任务上,新闻领域通常只给出了一个数据集。本文进行了定性和定量的分析实验,结果表明度量的表现对所采用的数据具有敏感性,即度量的排序随着所采用的数据变化而变化,即使这些数据都来源于相同的领域。随后本文进一步分析了导致这个问题的两个可能原因,即,非显著的样本点和独立同分布假设的违背。最后,本文建议,在评价度量时需要注意数据变化的问题并避免采用一个数据进行比较,否则得出的结论可能会有数据变化的问题。
文本理解
1. 重新思考负采样-一种处理实体漏标注问题的方法
Rethinking Negative Sampling for Handling Missing Entity Annotations
本文由腾讯AI Lab独立完成。负采样可以有效地处理命名实体识别中的漏标注问题。本文的一个贡献是,从抽样错误和不确定性两个角度出发,分析了负采样方法的有效性。实验表明,较低的抽样错误率和较高的不确定性是负采样有效的关键。基于命名实体稀疏性的特点,本文研究了抽样错误率为0的概率,推导出了这个概率的一个下界,它与句子的长度相关。
根据上述分析,本文还提出了一种自适应的加权抽样方法,它可以进一步提升负采样的性能;这是本文的另外一个贡献。在模拟数据和标注完整的数据集(CoNLL-2003)上, 本文提出的负采样方法取得了更好的F1值以及更快的收敛;另外,在真实的漏标注数据(EC)上,该负采样方法获得了最好的效果。
2. 利用情境常识提高机器阅读理解
Improving Machine Reading Comprehension with Contextualized Commonsense Knowledge
本文由腾讯AI Lab主导,与康奈尔大学合作完成。为了在机器阅读理解 (MRC) 任务中表现出色,机器阅读理解模型通常需要具备给定文档中未明确提及的常识知识。本文旨在剧本中提取一种新的结构化知识,并将其用于改进 MRC。我们专注于剧本,因为它们包含丰富的语言和非语言信息,并且在短时间内由不同形式传达的两条相关信息可能可以作为一条常识知识的元素(argument)对,因为其在日常交流中共同发挥作用。
为了减少人工命名关系带来的成本,我们建议通过将这样的元素对置于上下文中来隐式表示它们之间的关系,并将其称为情境知识。 为了使用提取的知识来改进 MRC,我们比较了几种微调策略来使用基于情境知识构建的弱标记 MRC 数据,并进一步设计了具有多个teachers的teacher-student范式,以促进弱标记MRC 数据中的知识转移。
实验结果表明,我们的范式优于其他使用弱标记数据的方法,并且在中文多选 MRC 数据集 C3 上将最先进的基线模型准确率提高了 4.3%,其中大多数问题需要未在文中明说的先验知识。我们还试图通过简单地微调生成的student模型来将知识转移到其他任务,在关系抽取数据集 DialogRE 上带来 2.9% 的 F1提升,体现了情境知识对于需要的文档理解的非 MRC 任务的潜在的价值。
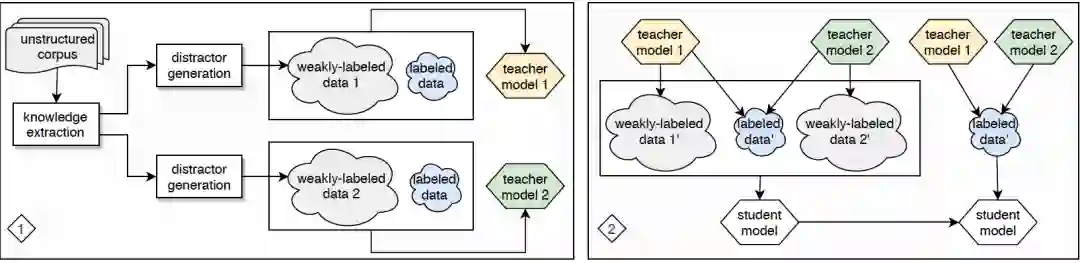
3. 作为廉价监督信息的变分自动编码在AMR指代消解的应用
Variational Graph Autoencoding as Cheap Supervision for AMR Coreference Resolution
本文由腾讯AI Lab主导,与耶鲁大学合作完成。对 AMR 之类的语义图的共指解析旨在对表示同一实体的图节点进行分组, 这是构造文档级形式语义表示的关键步骤。借助关于 AMR 共指解析的注释数据,深度学习方法最近在这项任务中显示出巨大的潜力,但它们通常需要大量训练数据并且注释数据的成本很高。
本文提出了一种基于变分图自动编码器(VGAE)进行 AMR 共指解析的通用预训练的方法,该方法可以利用任何通用 AMR 语料库,甚至可以AMR模型自动生成的 AMR 数据。在标准数据集的实验表明,预训练方法实现了高达 6% 的绝对 F1 点的性能提升。此外,我们的模型比之前的最先进模型显著地提高了 11% F1 点。
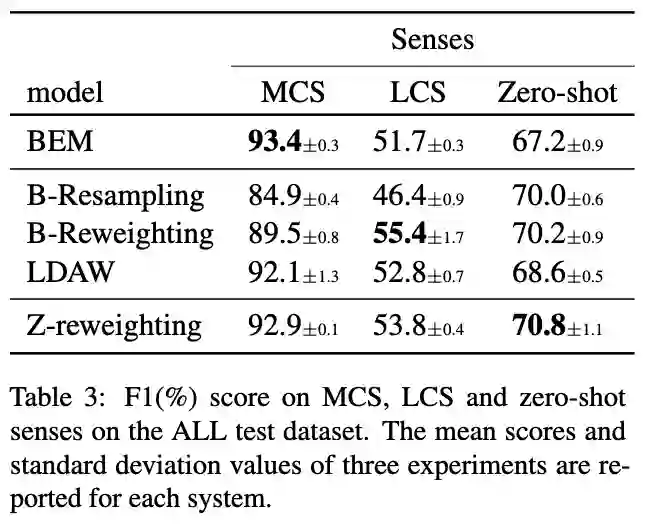
4. 基于 Zipf's law 的少样本语义消歧
Rare and Zero-shot Word Sense Disambiguation using Z-Reweighting
本文由腾讯AI Lab与香港科技大学合作完成。语义消歧(WSD)一直是自然语言里面最核心的问题之一。现有模型通常依赖于大型的预训练模型和大量的标注数据来取得效果的提升。但是这类监督学习的方法通常会面临数据不平衡分布的问题,以至于这些模型在比较常见的词上面效果很好,但是在一些低频词上面效果却很差。
本文提出了一个基于 Zipf's law 的数据采样策略,来帮助模型更地平衡高频词与低频词上训练的效果问题。实验结果表明,在不损害高频词WSD效果的同时,该方法能够大大提升模型在低频词和zero-shot词上面的表现。
语言模型
1. 从中文GPT的预训练模型到拼音输入法的适配探究
Exploring and Adapting Chinese GPT to Pinyin Input Method
本文由腾讯AI Lab主导,与新加坡管理大学、浙江大学合作完成。本文主要研究了将中文GPT的预训练模型适配到拼音输入法的问题。我们发现,在GPT的广泛使用中,仍然缺少对拼音输入法的探索。经过对生成过程加上拼音的限制,全拼场景下的GPT的效果十分突出,在传统的数据集上就能达到SOTA。然而,对于首字母的情形,GPT的效果出现大幅下滑,这与同声母字的候选大幅增加相关。
本文采取两种策略来解决这个问题,一方面让模型充分使用上下文信息和拼音信息,另一方面增强训练过程中对同声母字的辨析。为了助力拼音输入法的评测,团队基于最新的语料,构建了跨15个领域的270k的测试集合,集合的样本覆盖多种上文的长度和预测长度组合。对模型的分析和消融显示,模型的两个策略都对最后的效果有促进作用。实验结果对输入法的研究具有参考意义。
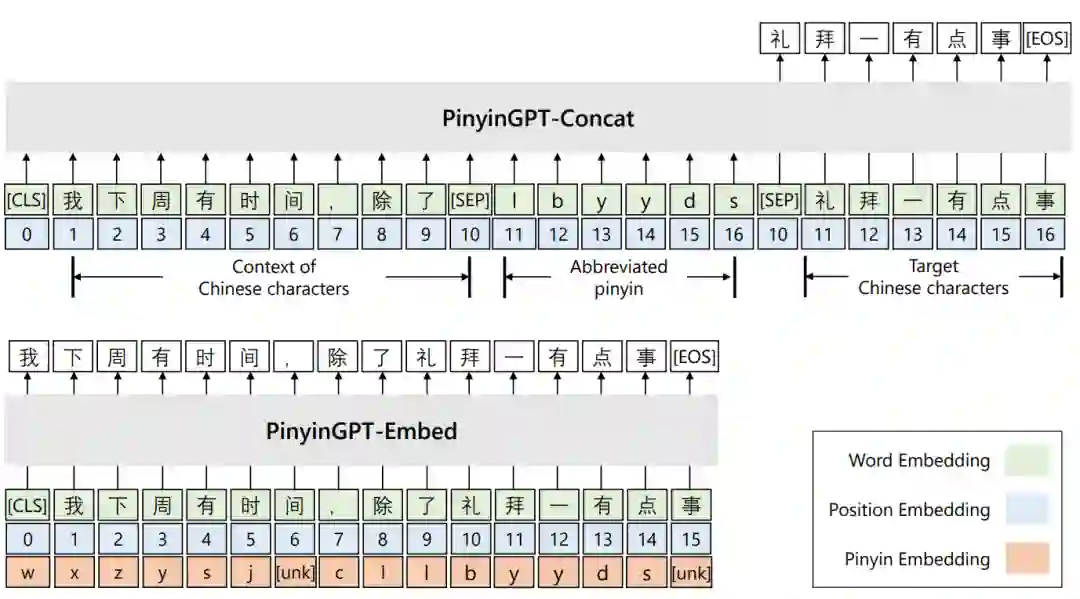
2. CoCoLM:复杂常识知识强化的语言模型
CoCoLM: Complex Commonsense Enhanced Language Model
本文由腾讯AI Lab与香港科技大学合作完成,被会议接收为Findings长论文。大规模预训练模型展示出了很强的知识表征能力,但是现有研究仍然表明即便这些模型展示出了非常强的低阶常识知识的能力,他们表征更复杂的高阶常识的能力仍然有所欠缺。
为了解决这个问题,本文提出将利用有的常识知识来增强语言模型对于常识的理解能力。具体来说,我们设计了一个三阶段的模型。第一阶段为general purpose的预训练,第二阶段为针对常识知识的预训练,第三阶段为fine-tuning。实验结果表明这样的一个结构能够帮助我们获得一个常识知识增强的语言模型CoCoLM,并在多个下游常识理解任务上取得显著的提升。
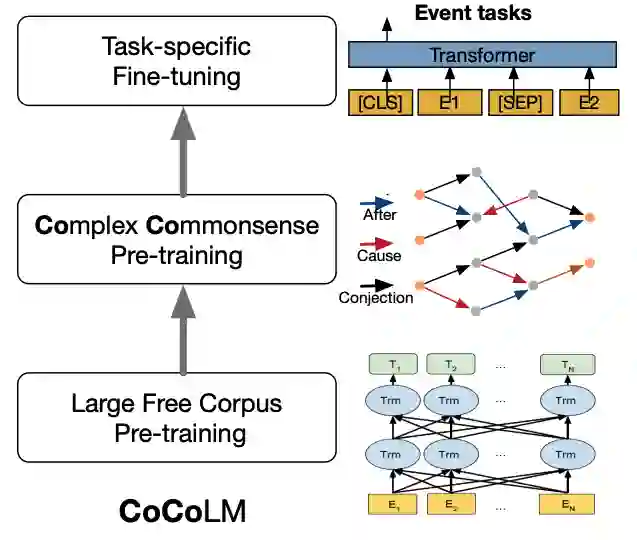
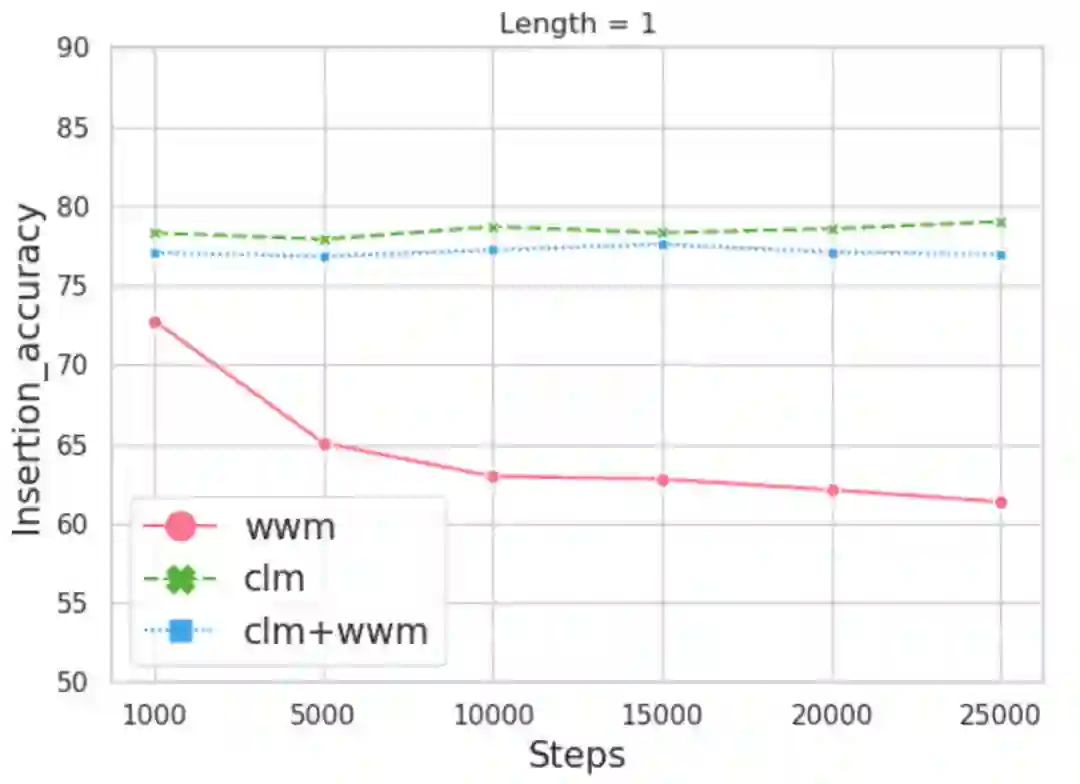
3. 全字掩蔽一直是中文BERT更好的掩蔽策略吗:在中文语法纠错任务上的探查
“Is Whole Word Masking Always Better for Chinese BERT?”: Probing on Chinese Grammatical Error Correction
本文由腾讯 AI Lab主导,与复旦大学合作完成,被会议接收为Findings短论文。全字掩蔽(WWM)是一次性地把一个字所对应的所有子词全部进行掩蔽,这种策略能够得到更好的英文BERT模型。但是对于中文来讲,每一个字都是无法分割的最小字符,它没有子词的概念。中文的词和英文的词区别在于,中文的词是由不同的字组合而成。这样的区别促使我们去研究是否WWM能够使得中文BERT具有更好的内容理解能力。
为此,该项工作引入了两个跟中文语法纠错相关的探针任务,它们利用预训练模型本身的方式去修正或者插入一些中文字或词。我们构建了一个数据集用来完成这两个任务,它具有10,448个句子和19,075个字的标签。我们训练了三个模型,它们分别采用了字掩蔽(CLM),WWM, 以及同时采用CLM和WWM。
本文的主要发现包括:第一,当只有一个字需要被修正或插入,采用CLM训练的预训练模型表现更好。第二,当连续的两个字及更多字需要被处理时,WWM起到了关键性的作用。第三,当对句子级别的下游任务进行微调时,几种掩蔽策略表现相当。

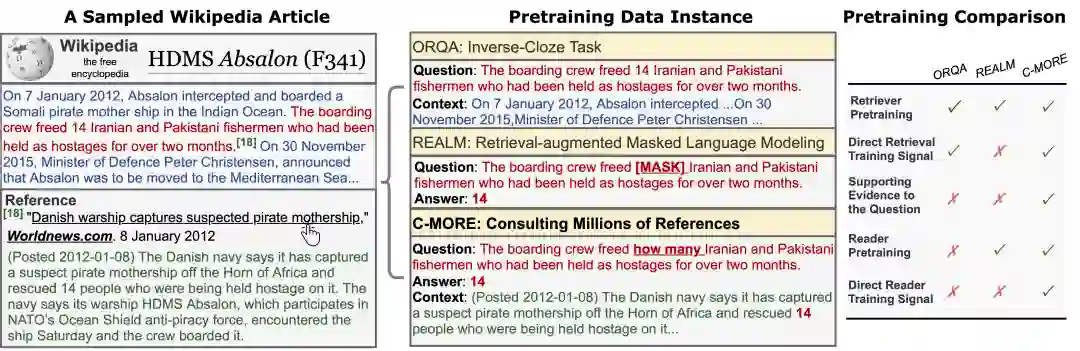
4. 通过查询百万参考文献回答开放领域问题的预训练
C-MORE: Pretraining to Answer Open-Domain Questions by Consulting Millions of References
本文由腾讯AI Lab主导,与俄亥俄州立大学合作完成。本文研究了如何预训练两阶段开放式问答系统(retriever+reader)。关键的挑战是如何在没有特定任务标注的情况下构建大量高质量的上下文问答三元组(question-answer-context triplet)。
具体来说,三元组应该通过以下方式与下游任务保持一致:(i)覆盖广泛的领域(对于开放领域应用),(ii)将问题与其语义相关的上下文联系起来,并提供支持证据(用于训练retriever),以及(iii)在上下文中识别正确答案(用于训练reader)。已有的预训练方法通常达不到其中一项或多项要求。
在这项工作中,我们通过查阅维基百科(Wikipedia)中引用的数以百万计的参考文献,自动构建了一个满足所有三个标准的大规模语料库。构建的语料库对retriever和reader都有显著的好处。相较于已有方法,我们经过训练的retriver在top-20 accuracy上提高了2%-10%,整个系统的accuracy最高提高了4%。

* 欢迎转载,请注明来自腾讯AI Lab微信(tencent_ailab)
