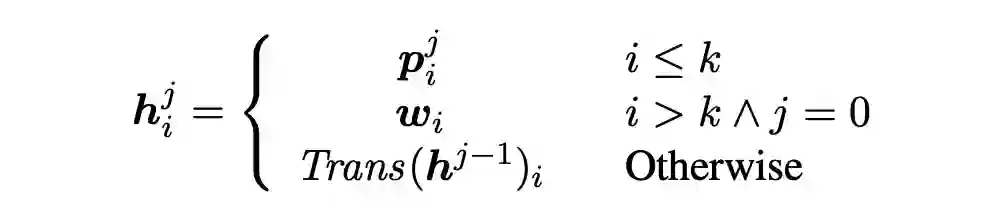![]()
©作者 | 李雪峰
单位 | 北京邮电大学
研究方向 | 序列标注
![]()
PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks
ACL 2022
https://arxiv.org/pdf/2202.12499.pdf
https://github.com/GaryYufei/PromDA
![]()
Abstract
本文重点关注低资源自然语言理解(NLU)任务的数据增强。作者提出了基于 prompt 的数据增强模型(PromDA),它只在冻结的预训练语言模型(PLM)中训练小规模的软提示(即一组可训练的向量)。这避免了人工收集未标记的域内数据并保持生成的合成数据的质量。此外,PromDA 通过两个不同的视图生成合成数据,并使用 NLU 模型过滤掉低质量的数据。
四个基准的实验表明,PromDA 生成的合成数据成功地提高了 NLU 模型的性能,这些模型始终优于几个竞争基线模型,包括使用未标记的域内数据的最先进的半监督模型。PromDA 的合成数据也与未标记的域内数据互补。NLU 模型在结合起来进行训练时可以得到进一步的改进。
![]()
Introduction
深度神经网络通常需要大规模的高质量标记训练数据来实现最先进的性能。然而,在许多情况下构建标记数据可能具有挑战性。在本文中,作者研究了低资源自然语言理解(NLU)任务,包括句子分类和序列标记任务,其中只有少量标记数据可用。之前的一些工作经常让模型产生一些“有标签的数据”,再喂给下游模型训练。这种也就是我们熟知的 self-training 的训练方式;也有一些工作使用自动启发式规则(例如随机同义词替换)扩展原始的小训练数据,从而有效地创建新的训练实例。然而,这些过程可能会扭曲文本,使生成的句法数据在语法和语义上不正确。
为了解决上述困境,许多现有的工作求助于应用语言模型(LMs)或预训练语言模型(PLMs)用于低资源环境中的数据增强。给定标记的数据,可以直接微调 PLM 以生成新的合成数据,而无需额外的人力。然而,我们认为,在低资源 NLU 任务中,使用少量训练数据(尤其是当样本少于 100 个时)直接微调 PLM 的所有参数可能会导致过度拟合,而 PLM 只会记忆训练实例。结果,生成的合成数据可能与原始训练实例非常相似,并且无法为 NLU 模型提供新的训练信号。
最近,一些工作提出了 prompt-tuning,它仅将错误反向传播到 soft prompt(即,预先添加到 PLM 输入的一系列连续向量),而不是整个模型。他们表明,及时调整足以与完整的模型调整竞争,同时显着减少要调整的参数数量。因此,快速调优非常适合解决上述低资源生成微调中的过拟合问题,在保证生成质量的前提下,相对于小标记数据产生更多新样本。
基于此,作者提出了一种基于 prompt 的数据增强方法。这种方式固定住整个预训练模型的参数,仅仅调整 soft prompt 的相关参数。此外,我们观察到 soft prompt 的初始化对微调有显着影响,尤其是在资源不足的情况达到极端程度时。为了更好地初始化数据增强任务的提示参数,我们提出了与任务无关的 Synonym Keyword to Sentence 预训练任务,以直接在其预训练语料库上预训练 PLM 的提示参数。
此任务模拟从部分片段信息(例如关键字)生成整个训练样本的过程。与之前的工作类似,我们可以微调 PLM 以生成以输出标签为条件的完整合成数据。我们将此称为输出视图生成。为了提高生成样本的多样性,我们引入了另一个名为 Input View Generation 的微调生成任务,它将从样本中提取的关键字作为输入,将样本作为输出。由于从小训练数据训练的 NLG 模型仍有一定机会生成低质量样本,我们利用 NLU 一致性过滤来过滤生成的样本。
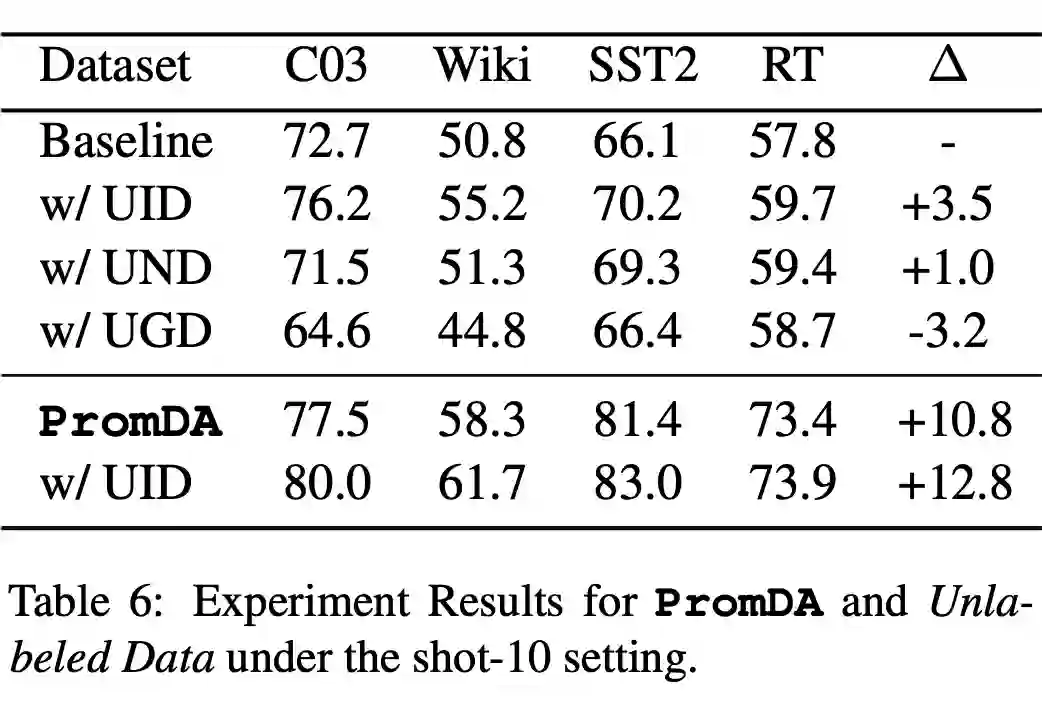
我们在四个基准上进行了实验,实验结果表明,在来自 PromDA 的合成数据上训练的 NLU 模型始终优于几个竞争基线模型,包括最先进的半监督 NLU 模型 MetaST。此外,我们发现来自 PromDA 的合成数据也与未标记的域内数据互补。当两者结合时,NLU 模型的性能可以进一步提高。最后,我们进行了多样性分析和案例研究,以进一步确认 PromDA 的合成数据质量。
![]()
Prompt-based Data Augmentation
![]()
(1)prompt-based learning
(2)持续的合成数据生成视图
(3)一致性过滤
在正式描述文中提出的方法之前,先对数据增强这个任务进行定义。数据增强就是在已有的少量有标注的样本的情况下,合成大量有标注的训练数据。最终模型进行训练任务时,将使用这两部分数据。
3.1 Prompt-based learning
作者这里选择了使用 soft prompt 的方式。具体来说,作者在训练的时候将任务描述都换成 soft prompt;训练的时候当然也只更新这一部分的参数。不同于只在输入层加参数的做法,作者在每一层 transformer 上都加了一层 MLP 作为 soft prompt 部分参数学习。具体来说,每一层的隐状态可以表示如下:
![]()
3.2 Pre-training for Prompt Initialization
作者认为 soft prompt 的影响巨大。为此,作者设计了一种同义词预测任务,任务描述如下:
-
给定一段文本,我们首先使用一种无监督算法 Rake(大致类似于 text-rank 这种)抽取文本中的关键词
-
使用查出的同义词重构原来的文本
这就是一个使用同义词预训练 soft prompt 的方法;这个训练过程使用与下游任务类似的语料;这个过程只训练一次,最后在下游少样本有标注数据上 fine-tuning 一下即可。
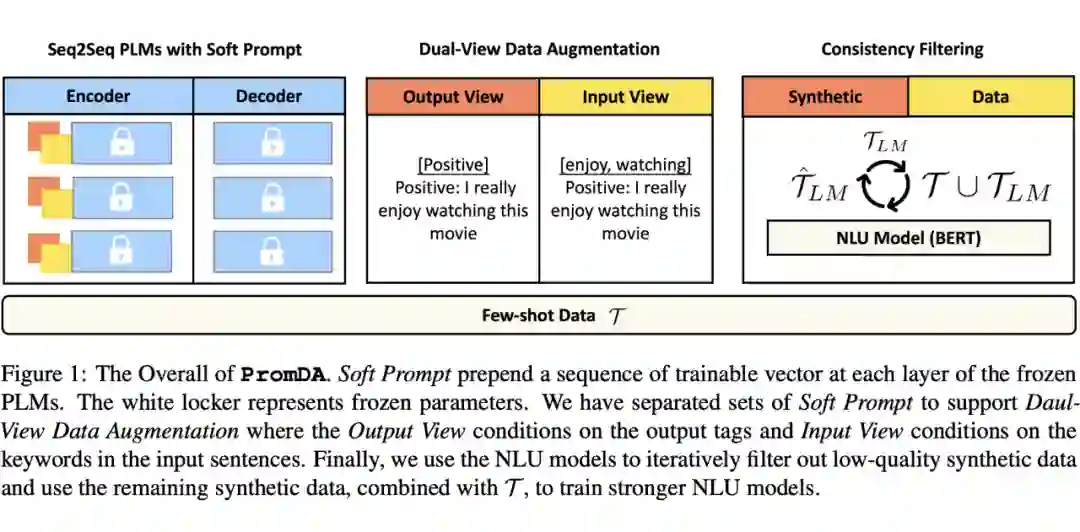
3.3 Dual-View Data Augmentation
![]()
作者设计了一种双视图的数据方式,即:输入视图和输出视图。输入视图基于关键词生成合成的数据;输出视图则基于输出的标签。上面的图展示了这一过程。
作者认为这种方式可以获得足够高质量的合成数据用于数据增强
Dual View via Prompt Ensemble
作者训练了 K 组 soft prompt,创建了 K 个共享相同冻结 PLM 的模型。并将两个视图看成独立的部分,这样就可以包括各种现实世界的知识。
3.4 Consistency Filtering
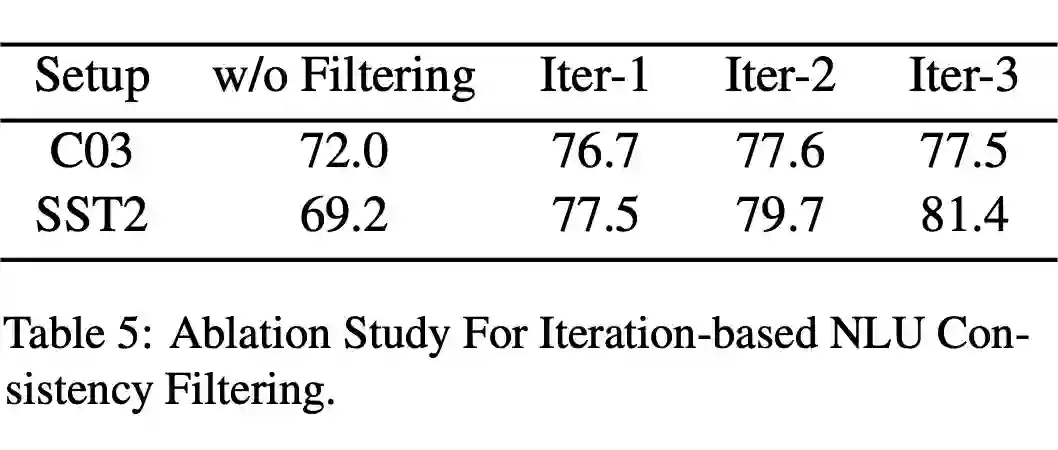
作者认为这种合成数据由于仅仅使用了少量的数据,因此有可能生成低质量的样本。作者因此提出了一种一致性过滤的方式。其实就是让 NLU 模型对于这种数据再打一个标签,如果和 PromptDA 模型的预测保持一致就保留,否则就舍弃这个数据。经过 r 轮迭代之后,就会获得稳定的模型和数据。
3.5 Experiment
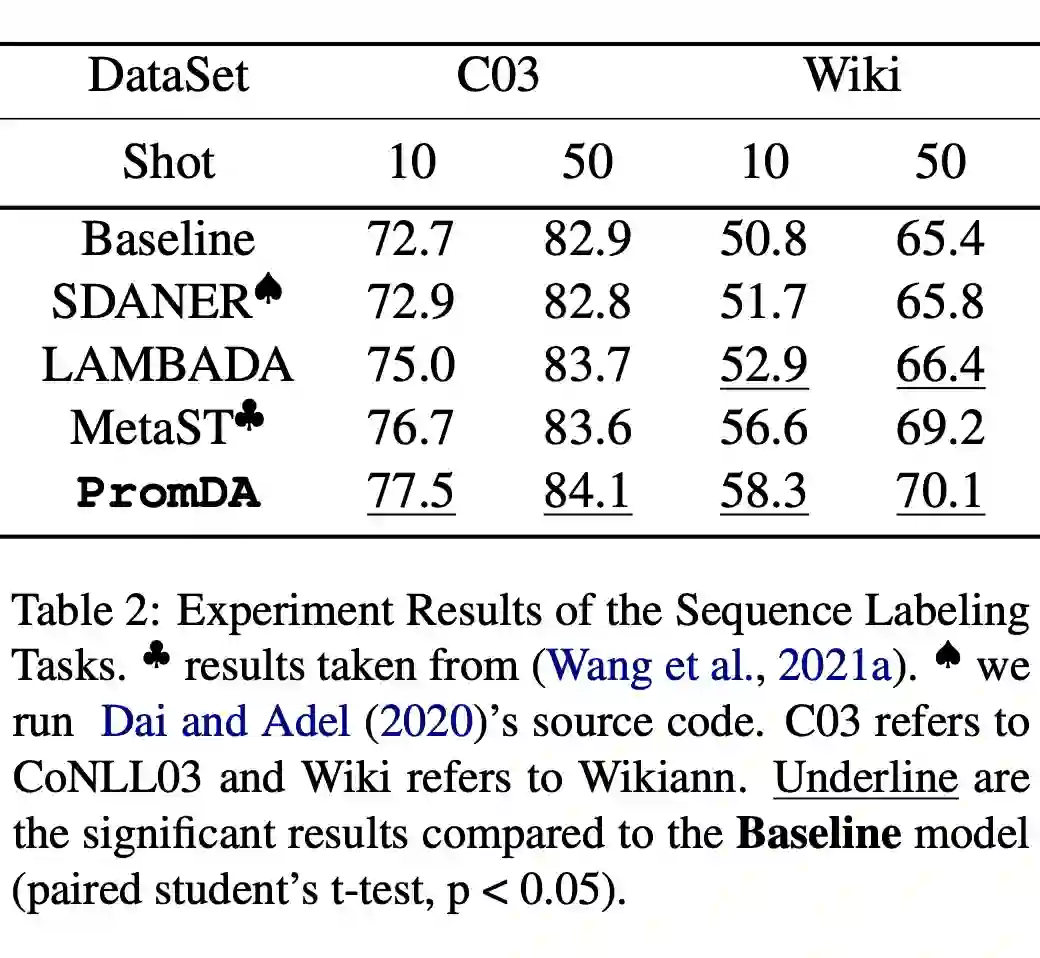
![]()
▲ 模型在序列标注上的表现
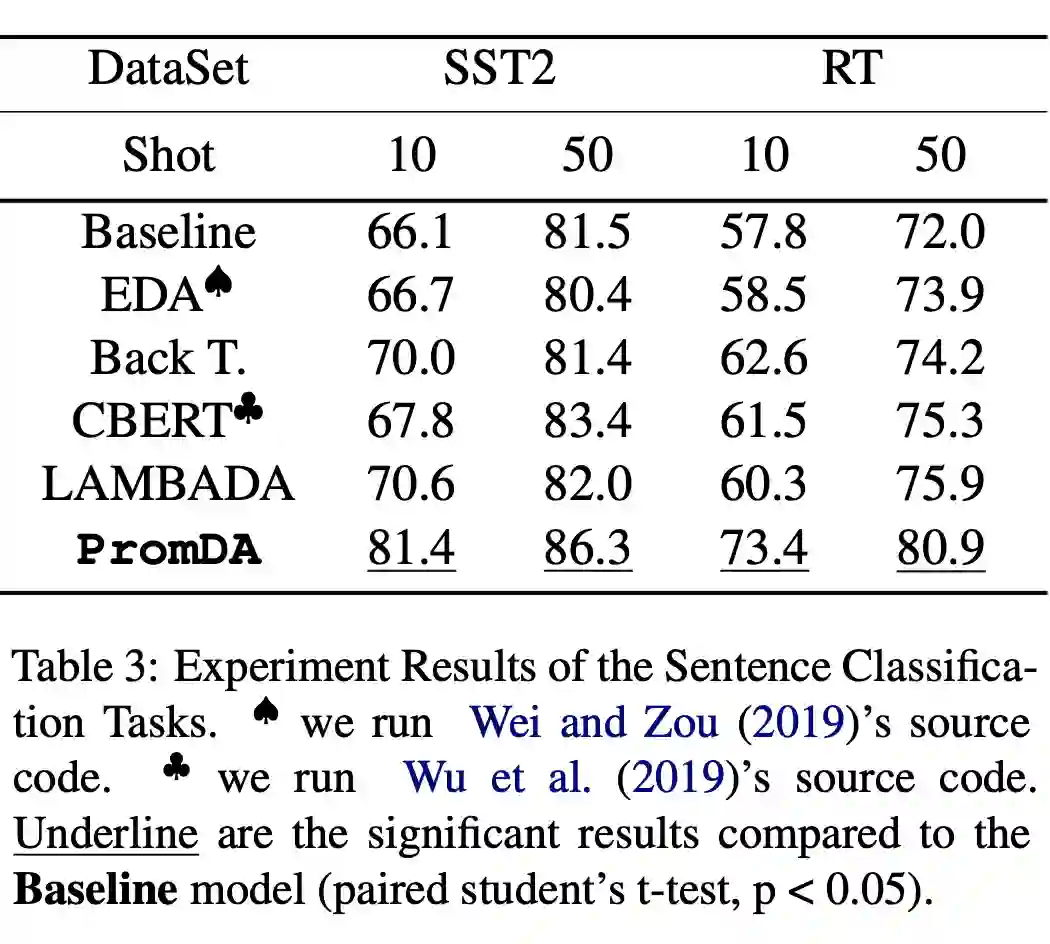
![]()
▲ 模型在句子分类任务上的表现
![]()
▲ 消融实验(预训练和多视图)
![]()
▲ 消融实验(一致性过滤)
![]()
▲ 使用未标注数据的结果
![]()
▲ 生成数据的多样性分析
![]()
Conclusion
在本文中,作者第一个提出了基于提示的预训练语言模型 PromDA,用于低资源 NLU 数据增强。四个基准的实验表明了我们提出的 PromDA 方法的有效性。未来,作者计划将 PromDA 扩展到其他 NLP 任务,包括问答、机器阅读理解和文本生成任务。
PaperWeekly独家周边盲盒
限量 200 份,免费包邮送
周边盲盒将随机掉落
众多读者要求返场的爆款贴纸
炼丹师必备超大鼠标垫
让你锦鲤护体的卡套组合
扫码回复「盲盒」
立即免费参与领取
👇👇👇
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()