Alibaba at Interspeech 2021 | 达摩院语音实验室9篇入选论文解读

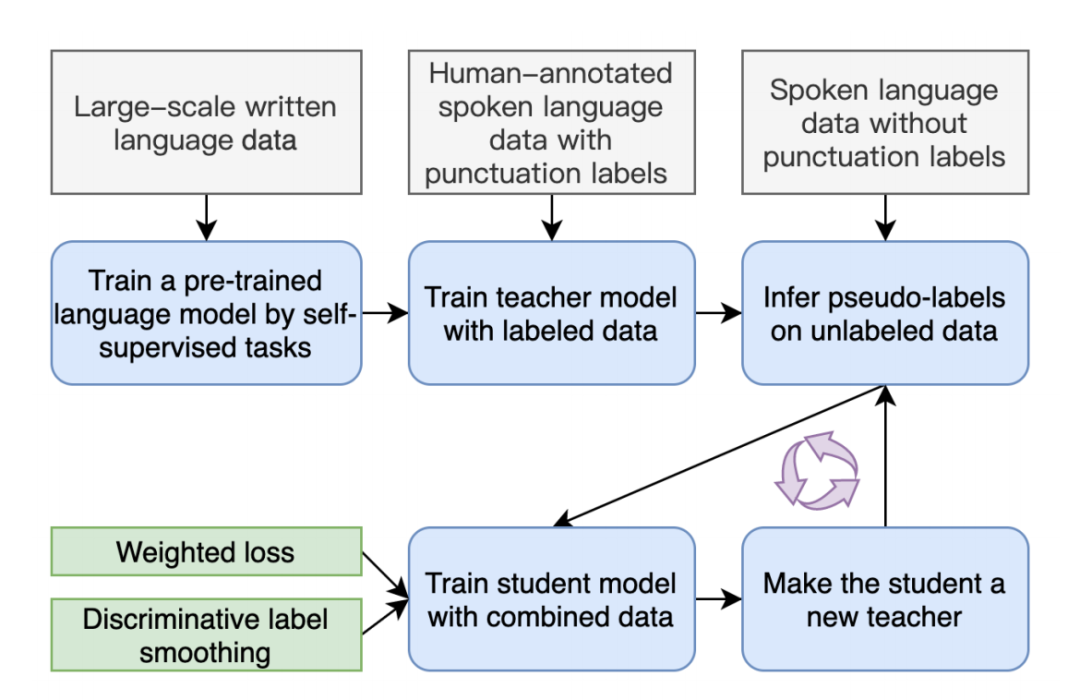
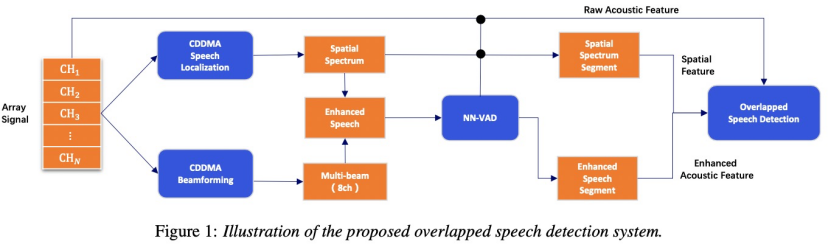
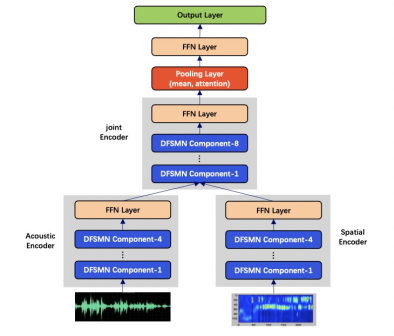
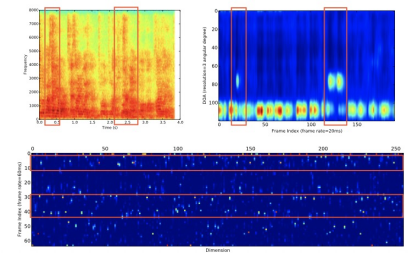
登录查看更多
相关内容

INTERSPEECH是关于口语处理科学和技术的全球最大、最全面的会议。INTERSPEECH会议强调跨学科的方法,涉及语音科学和技术的各个方面,从基础理论到高级应用。
官网地址:http://dblp.uni-trier.de/db/conf/interspeech/index.html
专知会员服务
36+阅读 · 2020年4月14日





相关VIP内容
专知会员服务
36+阅读 · 2020年4月14日
相关资讯
相关论文