模型的Robustness和Generalization是什么关系?
链接 | https://www.zhihu.com/question/410332622/
编辑 | 机器学习与推荐算法
最近在看一些利用对抗学习技术提升模型鲁棒性以及泛化能力的文章,然后看到了知乎有相关的讨论,特此整理一下供大家学习交流。
模型的Robustness和Generalization是什么关系?
https://www.zhihu.com/people/mai-kang-ming
经验上来说,毫无疑问他们两者是存在联系的。体现的比较明显的领域在于弱监督学习(例如,半监督学习),会使用各种各样的数据增强(例如,加入噪声,反转,裁切,甚至对抗等),让模型变得对输入的细微扰动不敏感,从而减少过拟合(因为在标注数据少的情况下,过拟合是容易发生的),提升泛化性能。类似的工作比如
-
Tarvainen and Valpola 2017: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results Miyato et al. 2019: Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
但是,把鲁棒性做的极端一点,即使是大幅度的扰动,也无法改变模型的输出,那么模型就会变成过平滑/随机模型,从而降低预测性能。
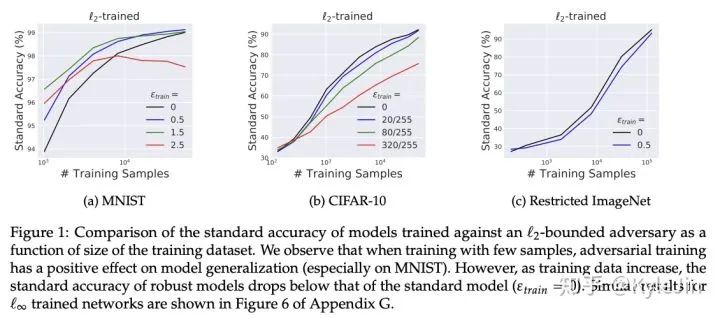
这篇文章的结果是这么说的:
首先,经验上来说,在训练数据不足的时候,加入robustness(例如,对抗样本训练)会对模型的泛化起到积极的作用。但是,当数据量变大/变得复杂,这个效果就消失了(哪怕是在稍微复杂一丢丢的数据集,例如CIFAR10,CIFAR100上,这个效果就从未体现出来)。这是好理解的,在简单/小数据上,过拟合/欠鲁棒发生了,但是程度可能非常有限。
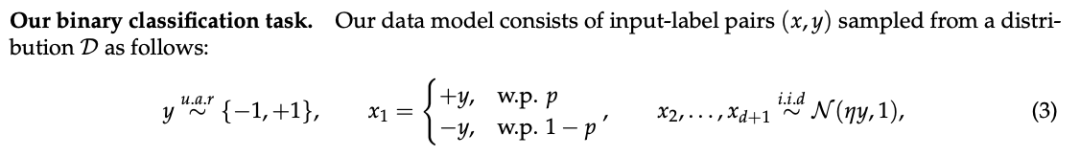

作者在这个简单的数据集下证明了robustness和accuracy是存在矛盾的,很符合我们通过实验观测的结果。
2. Theoretical evidence for adversarial robustness through randomization.
https://papers.nips.cc/paper/9356-theoretical-evidence-for-adversarial-robustness-through-randomization.pdf
本文中作者证明了,如果想通过随机化的方式增强鲁棒性,那么必然面对精确度的损失(作者用预测的期望熵来衡量)
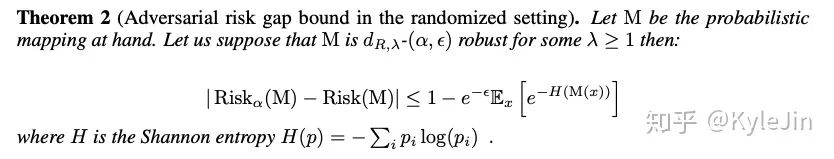
符号很复杂,不过表达的意思就是,如果加入较大的噪声让模型变鲁棒,那么H(M(x)),即模型输出的熵一定变大。当然,本文作者只探讨了“随机化”一种方式对robustness-generalization关系的影响。
在现实中,一般模型是都欠鲁棒的,一个间接的证据就是很多看起来很离奇的正则化都可以让模型test accuracy变高,例如mixup(Zhang et al. 2018), StochasticDepth(Huang et al. 2016), Shake-shake (Gestaldi et al. 2017)等等,所以在实际应用中鲁棒性应该是越强越好。
在权衡的另一端,鲁棒性的一个很强的例子是对对抗样本鲁棒(adversarial robustness),是一个非常强的约束,从而会导致test accuracy大幅下降。这体现了过鲁棒-无法泛化,在刚才提到的paper里也有论证这一点。
知乎作者:心似风往
Part 2 直接提到有关robustness 和 generalization的问题文章
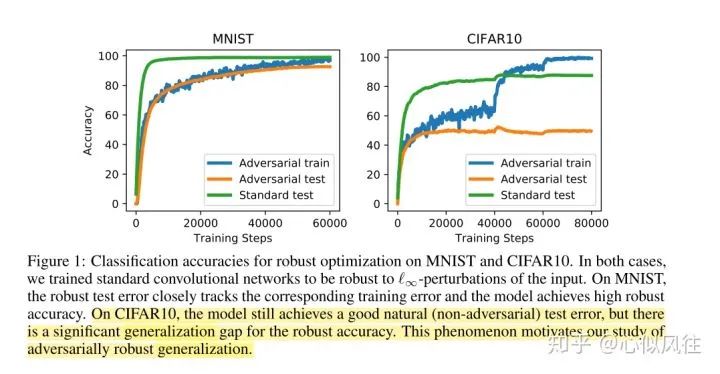
1.Defining the Stability of a Learning Algorithm
2.Generalization Bounds for Stable Learning Algorithms:
the empirical error and the leave-one-out error differ from the true error in a similar way.
3.Stable Learning Algorithms: discussion6
For regularization algorithms, we obtained bounds on the uniform stability of the order of β =O( 1/λm).
4.we obtained bounds on the generalization error of the following typeR ≤ Remp +O ( 1/λ √m)
总结:Our main result is an exponential bound for algorithms that have good uniform stability. We then proved that regularization algorithms have such a property and that their stability is controlled by the regularization parameter λ. This allowed us to obtained bounds on the generalization error of Support Vector Machines both in the classification and in the regression framework that do not depend on the implicit VC-dimension but rather depend explicitly on the tradeoff parameter C.
参考:
^Robustness may be at odds with accuracy https://arxiv.org/pdf/1805.12152.pdf
^theoretically principled trade-off between robustness and accuracy https://arxiv.org/pdf/1901.08573.pdf
^adversarial examples-are-not-bugs, they are features https://papers.nips.cc/paper/8307-adversarial-examples-are-not-bugs-they-are-features.pdf
^Understanding and Mitigating the tradeoff between robustness and accuracy https://arxiv.org/pdf/2002.10716.pdf
^A Closer Look at Accuracy vs. Robustness https://arxiv.org/pdf/2003.02460.pdf
^Adversarial Training Can Hurt Generalization https://arxiv.org/pdf/1906.06032.pdf
^Adversarially Robust Generalization Requires More Data http://papers.nips.cc/paper/7749-adversarially-robust-generalization-requires-more-data.pdf
^Stability and generalization http://www.jmlr.org/papers/volume2/bousquet02a/bousquet02a.pdf
推荐阅读



