为什么『无监督集成学习』乏人问津?

本文原作者阿萨姆,原载于知乎专栏《数据说》。AI研习社已获得转载授权。
终于有机会给大家聊聊每天折磨我的主题 - 无监督集成学习(Unsupervised Ensemble)。其实这是个很有意思的领域,但因为各种各样的原因一直都处于萎靡不振的情况。比较尴尬的是,工业界非常需要好的无监督集成算法,但学术界的兴趣更多的还是在那些吸睛的领域上。
相信大家都听说过无监督学习(unsupervised learning),就是使用没有标签的数据进行学习,比较常见的应用有聚类算法如K-means。举个简单的例子,如果给了你经济数据,并给了你今天的股票价格,让你预测未来那就是监督学习。如果只给你经济数据,直接让你预测未来那就是无监督学习。一般来说,无监督学习的难度要远高于监督学习。
而集成学习大家也不陌生,比如Kaggle中常见的GBDT还有工业界常用的随机森林(random forests)都是集成学习。集成学习的精髓就是一个好汉三个帮,使用多个基学习器来降低模型的泛化误差中的偏差(bias)和方差(variance)。
但当我们把这两个概念合起来,什么是无监督集成学习?简单来说,无监督的集成学习就是对没有标签的数据使用集成算法。但或许你也发现了,百分之九十九的教科书都不会提到这个主题,大部分时候你只会在论文中看到这个名词。引发这个现象的原因有很多,今天跟大家抛砖引玉的介绍几个它备受冷落的原因。
没有标签导致序列模型(sequential model)失效
对于有监督的集成学习来说,比较出名的框架(元算法)有两种:
bagging:从训练数据中多次重复采样生成多个子数据集(sub-sample),同时在每个子数据集上训练基学习器,最后将基学习器的结果整合。
boosting::将多个基学习器按照顺序在训练数据上进行训练,每次训练后,调整训练数据中误分样本的权重,以不断的提高分类器的能力。
在这两种框架中都可以使用不同的基学习器,只要遵循上面的步骤即可得到不错结果。而对无监督学习来说,boosting是一个序列模型,基学习器并不是同时训练,而是有先后顺序。而无监督学习中我们没有标签,于是无法在训练完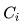
当然,科研人员们也不是吃素的,面对没有标签的boosting也开发出了一些替代品[1](http://t.cn/RWMHfHl),比如用启发式算法(heuristic algorithm)。但实际效果非常不稳定,不容易获得可靠的结果。
没有标签导致难以评估模型
但我们得到基学习器以后,需要观察其学习成果如何,一般是直接与标签进行对比。然而无监督学习导致了很难对结果进行评估,即使不做集成学习这也是很难的一件事情。
因此,不同场景下我们只好选择不同替代品。对于聚类来说,如果我们使用了混合高斯来拟合数据,那么最大似然就成了评价依据。如果我们选择了K-means算法,那么一个数据点距离其所属团(cluster)的中心距离就是评价标准。如果我们是用Isolation Forest,那么将一个数据点隔离(isolate)所需要的树的深度就成了它的评估标准。因此,无监督学习中的评估标准非常混乱,不像监督学习中可以直接与标签进行对比。
同时,因为没有标签的缘故,在无监督学习中我们一般很难使用交叉验证(cross validation),甚至也不会区分训练集和测试集因为没什么差别。
融合基学习器的困难
集成学习中最重要的一步就是将基学习器的结果融合在一起,常见的方法有:
取平均(Averaging),也叫做majority vote,就是对所有基学习器结果求平均少数服从多数。比如预测一个数字,可能是0-9,如果十个基学习器中八个认为结果是0,那么最终结果是0。
加权平均:和平均法类似,但不同的基学习器根据其性能有不同的权重,能力越强的分类器权重越大,常见于boosting算法中。
对投票结果再进行分布拟合,或者对结果进行极值分析(extreme value analysis),暂时不表。
在监督学习中,即使每个基学习器的类型不同,最终的输出可能都是预测分类,比如0或者1。而无监督学习不同,基学习器的预测结果可能有不同的含义,比如K-means的输出结果是距离,而Isolation Forest输出的是深度,都不在一个维度上。虽然我们可以将每个基学习器的结果都“变成”0和1这种一致的形式,但转化过程中势必会损失信息,对于本身就很难的无监督学习这是难以接受的。因此在无监督集成中,为了将不同基学习器得到结果统一往往会使用:
1、正规化(normalization):可以计算z-score,将每个基学习器的结果投射到正态分布上(均值为0,标准差为1),即
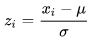
假设你有三个基学习器 c1,c2,c3, 他们的输出结果都有不同的含义,如距离、概率、误差的平方。
假设c1是kmeans,对于你的数据X,它会输出距离最近的cluster的中心的距离
。那么就可以使用上面的公式近似的把这些距离拟合到正态分布上,同理可以对c2,c3产生的数据进行相似的处理。
此处需要注意,投射到正态分布上可能不符合本身的数据分布,但中心极限定理告诉我们数据量大的时候也可以这样近似。但这不是最佳的方法,因为基学习器的输出并非独立同分布。这么做只是为了让后续的集成操作在“同一维度上”,实属无奈之举。
2、概率化:如果基学习器的输出本身就是概率,那是最佳情况因为概率可以直接进行集成。特定情况下,用不同的分布融合的生成模型,如GMM产生数据点来自于不同高斯分布的概率[2](http://t.cn/RWMTeQx)。
那么将不同的基学习器转化到同一个标准下以后,我们就需要把结果融合。集成的方法有很多种,具体情况取决于你使用的集成方法是倾向于降低方差、偏差、还是两者都有。对于类似bagging的集成,即使在无监督学习下的目标依然是降低方差,一般比较常见的做法有有取基学习器中的最大值,或者依然取平均。
总结
无监督集成学习的重点就是期望基学习器有好的准确性(accuracy)和多样性(diversity),这样集成的结果才会好。但因为无监督学习没有标签,我们无法很好的衡量准确性,而只能衡量多样性(high variability)。然而准确性和多样性是一对欢喜冤家,他们直接会决定模型泛化误差的方差和偏差。
这篇文章的目的是给大家介绍一下无监督集成学习中常见的困难,如果有空也希望更多的介绍相关的内容。这个领域的应用很广但相关研究很少,比如风险预测和聚类等,很适合想要填坑的朋友来挖坑灌水。
这篇文章仓促写成,难免有所疏漏,希望大家在评论中指出。感谢 ʕ•ᴥ•ʔ


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
微软发布SynNet,迁移学习&无监督学习,完美应用于机器阅读
▼▼▼




