运用注意力机制的 Transformer 模型近几年在 NLP 领域获得了广泛应用。然而,由于参数量和计算量巨大,Transformer 模型难以在存储和算力有限的边缘硬件设备上高效部署。为了解决 Transformer 的低效问题,来自 MIT 的研究人员提出了 HAT: Hardware-Aware Transformers,针对不同的硬件设备的特性,为每个硬件搜索出一个高效的 Transformer 模型,从而在保持精确度的前提下大幅降低内存消耗。在同样的精度下,相比于基线 Transformer, HAT 可以获得 3 倍加速,3.7 倍模型压缩。
该论文已被自然语言处理顶会 ACL 2020 收录。此外,HAT 的所有代码和模型已经在 GitHub 上开源,作者也将在 7 月 8 日 / 9 日的 ACL 大会上线上宣讲他们的工作。
![]()
论文链接:https://arxiv.org/abs/2005.14187
GitHub:https://github.com/mit-han-lab/hardware-aware-transformers
B站介绍: https://www.bilibili.com/video/BV1mt4y197FL/
近年来,自然语言处理领域受 Transformer 的驱动获得了快速发展,Transformer 模型也被广泛应用于多种任务,例如机器翻译、聊天机器人、文本摘要等等。然而,Transformer 的高准确性需要非常高的模型参数量和计算量来支撑,这对于受到存储大小、算力和电池容量限制的边缘计算设备(比如手机和物联网硬件)来说是很大的挑战。例如,如果在树莓派上使用 Transformer-Big 模型,它需要运行 20 秒才可以完成一个 30 词长度的句子的翻译,这对于很多需要实时对话和反馈的场景来说是无法接受的。
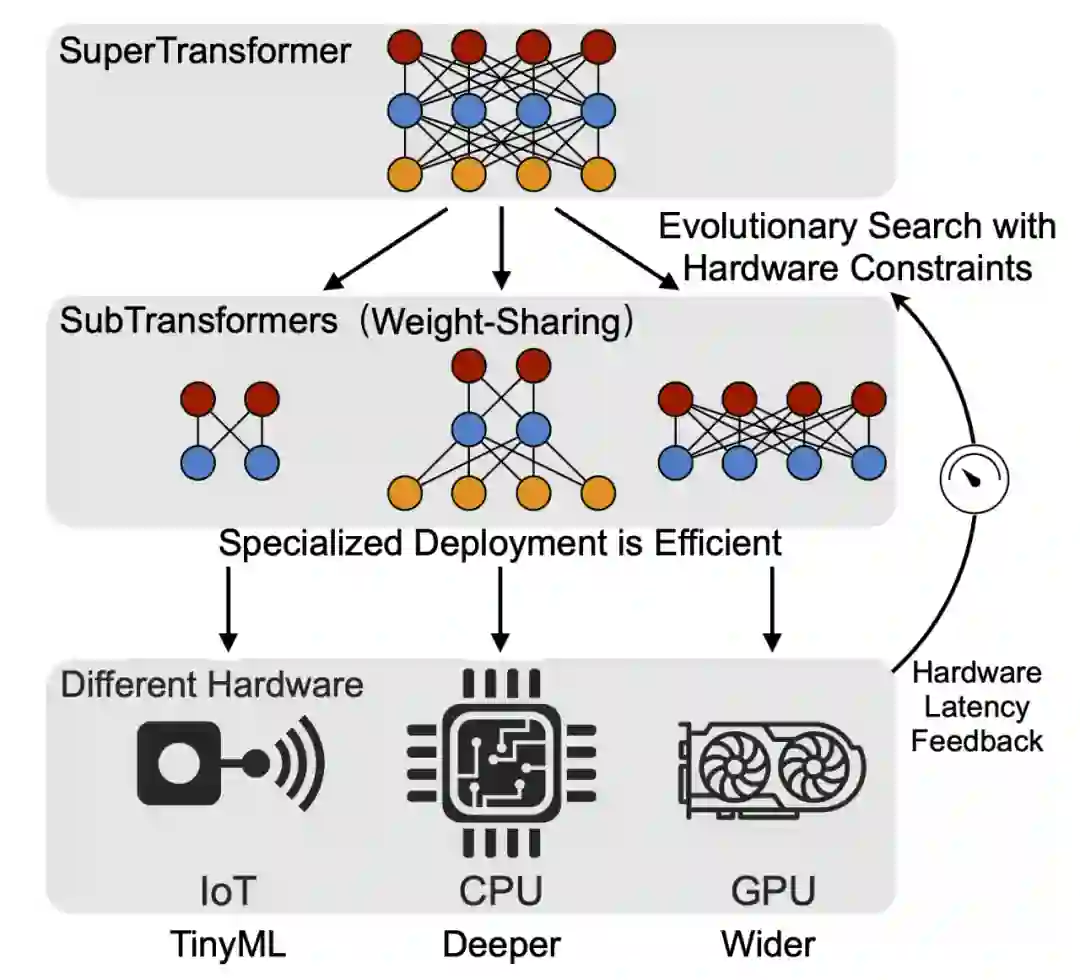
为了获得更高效和快速的 Transformer 模型,MIT 等机构的研究者提出了 HAT: Hardware-Aware Transformers,借助神经网络搜索(NAS)技术,在搜索过程中加入硬件反馈,来对每一个硬件平台设计一个专用的高效 Transformer 网络结构。
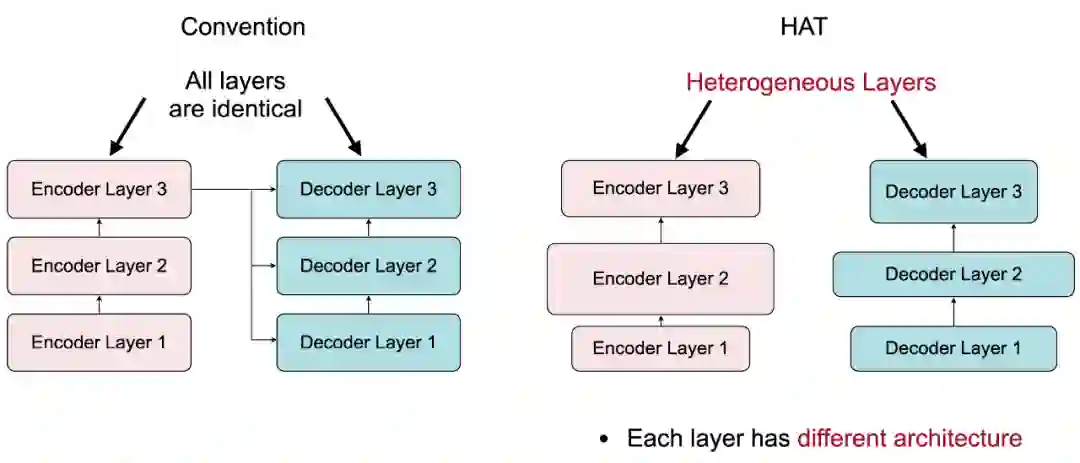
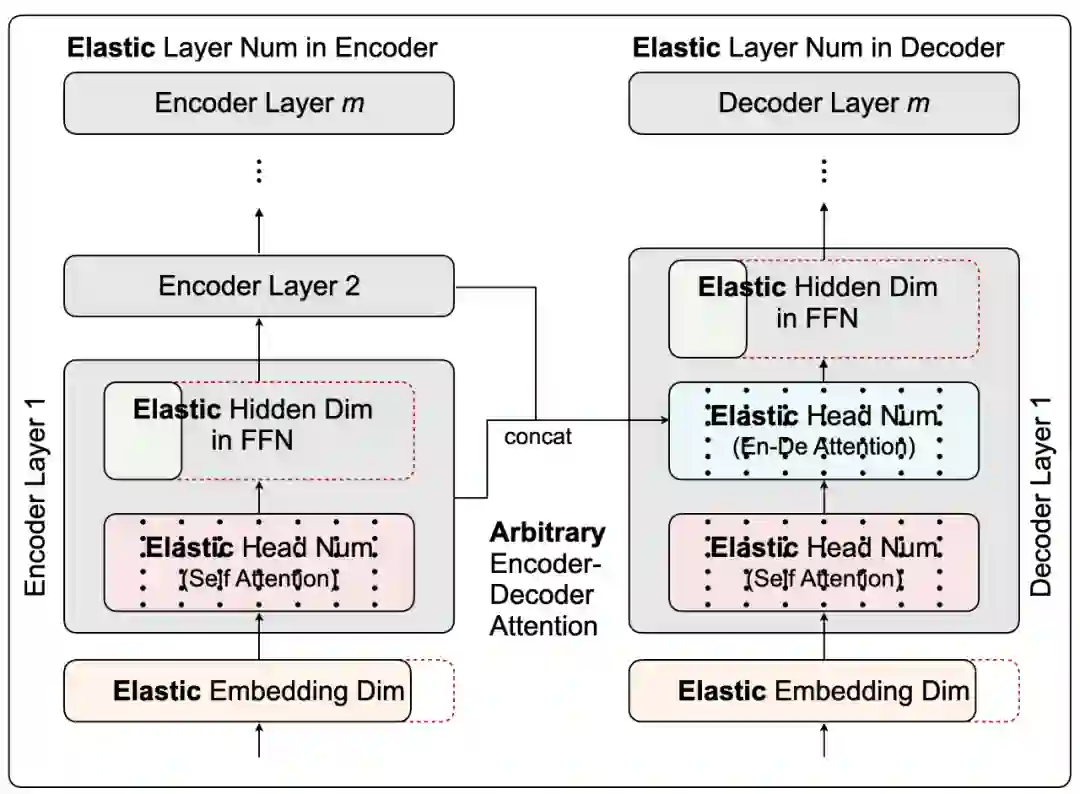
在搜索空间上,他们提出打破之前设计 Transformer 的两点陈规。首先,传统 Transformer 的所有解码层都从最后一层编码层获得输入,这样形成了一个从编码器到解码器的信息瓶颈,对小模型尤其不友好;对此,研究者提出“任意编码器 - 解码器注意力”(Arbitrary Encoder-Decoder Attention),允许解码器获得多个和任意某些个编码器的输出。从而使得编码器不同的抽象层的信息都可以被解码器获取和使用。另外,传统 Transformer 的所有层都有相同的网络结构,研究者提出“异构层”(Heterogenous Layers)来使得每层都可以有不同的隐藏层维度(Hidden Dim)和注意力头数 (Head Number),编 / 解码器也可以有不同的词向量长度 (Embedding Dim) 和层数等等。
在搜索算法上,为了能够减少搜索开销,实现环保 AI,他们采用权重共享的方法来训练出一个母网络 SuperTransformer 来涵盖在搜索空间中的全部可能模型,这样一来,其中的每个子网络 SubTransformer 可以直接继承母网络中对应部分的权重,快速估计子网络的精确度。之后,研究者使用进化搜索(Evolutionary Search),利用预先设定好的在目标硬件上的运行时间来作为限制,在母网络中搜索出一个满足运行时间并且精度够高的子网络,这就是他们想要得到的为目标硬件设计的专用 SubTransformer 网络。
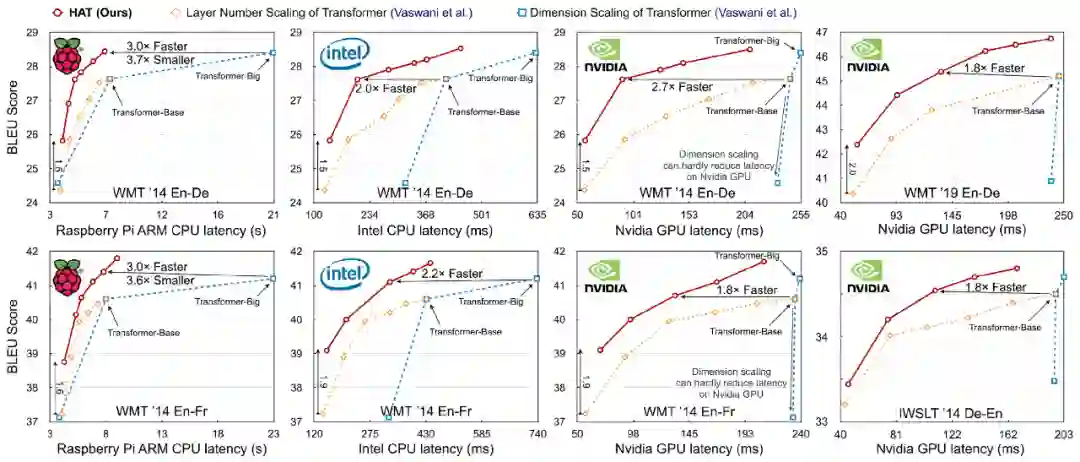
研究者在四个机器翻译任务(WMT‘14 EN-De(英语 - 德语)、WMT’14 EN-Fr(英语 - 法语)、WMT’19 EN-DE(英语 - 德语)和 IWSLT‘14 De-En(德语 - 英语)),以及三个不同的硬件平台(树莓派、Intel CPU 和 Nvidia GPU)上验证了论文所提方法的有效性。
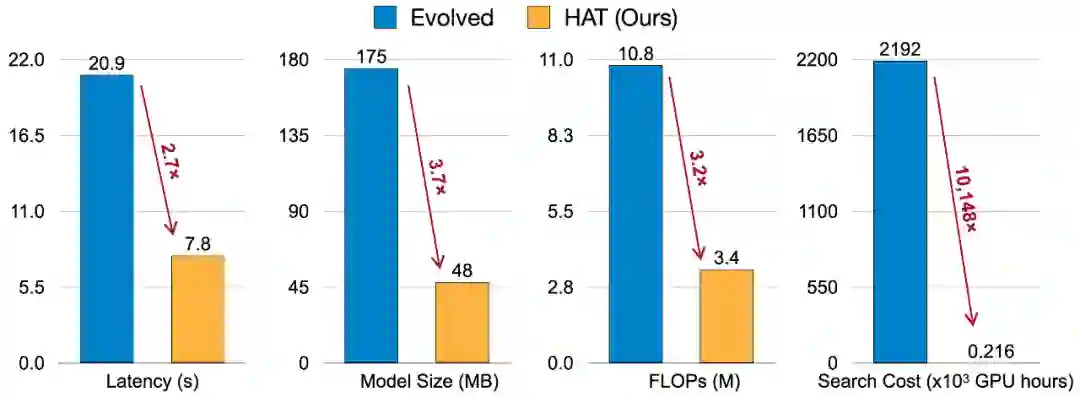
在同样的精度下,相比于基线 Transformer, HAT 可以获得 3 倍加速,3.7 倍模型压缩;相比于 Evolved Transformer,HAT 有 2.7 倍的加速和 3.6 倍的模型压缩,并且将搜索开销降到了 1.2 万分之一。同时,HAT 的方法也与其他模型压缩技术兼容,例如,研究者将搜索得到的 HAT 模型进行了 4-bit 压缩,进一步获得了仅为基线 Transformer 1/25 大小的模型。
![]()
在 Transformer 的性能测试中,研究者发现了两个常见且重要的陷阱:
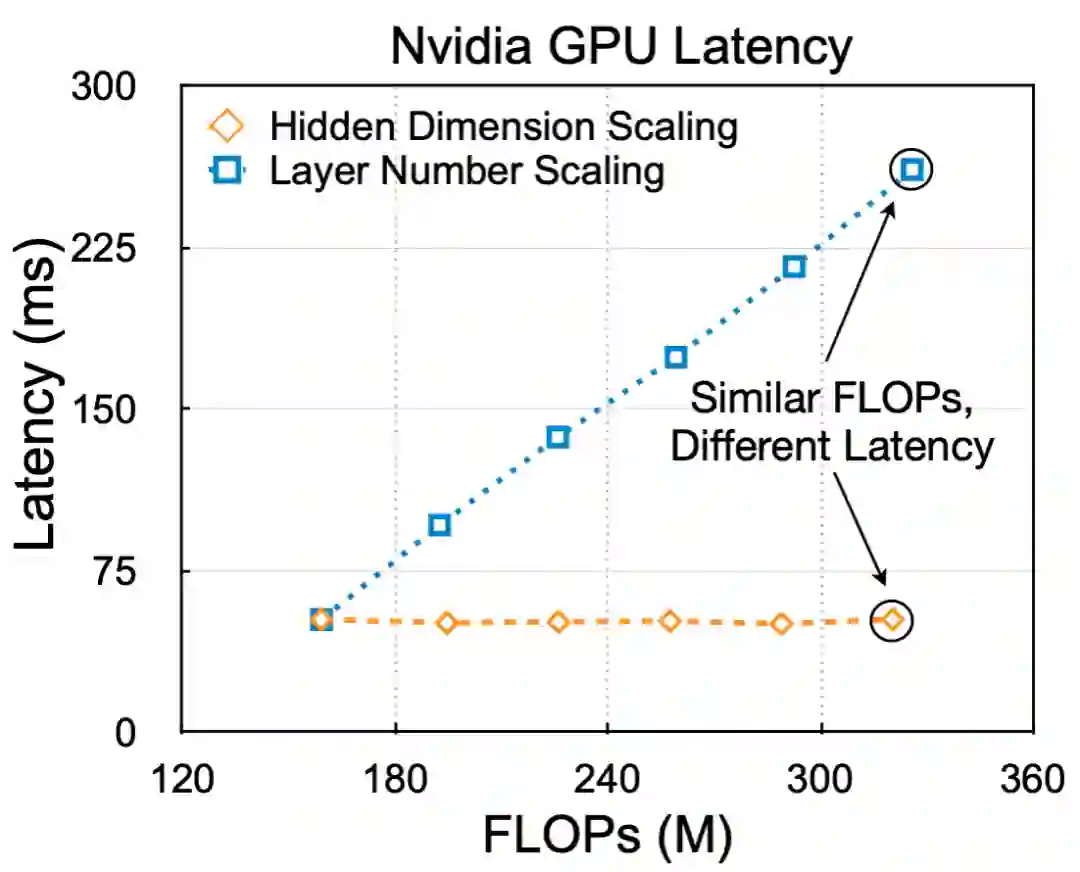
第一,计算量(FLOPs)不能反映真正的运行时间。例如,在下图中,圈出的两个模型具有相同的计算量,但是不同的隐藏层大小和层数,导致了两个模型的运行时间有 5 倍的差距。
![]()
图 2:计算量(FLOPs)不能反映真正的运行时间。
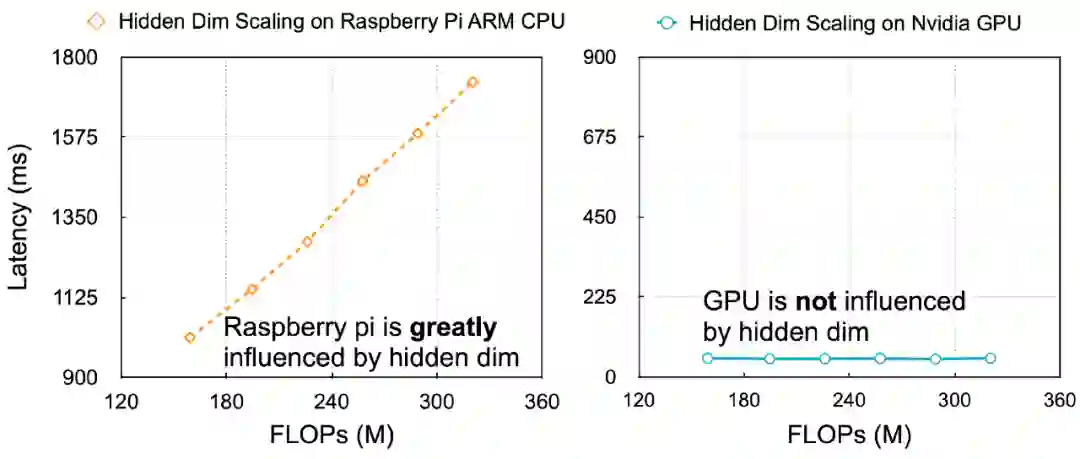
第二,不同的硬件需要有不同的高效模型设计策略。例如,在下图中,隐藏层的大小显著地影响树莓派的运行时间,但是对 GPU 的运行时间几乎没有影响。
基于以上两点,研究者提出将硬件运行时间反馈到模型设计中来,并且为每个硬件平台设计一个专用 Transformer 架构。
![]()
Hardware-Aware Transformers
通过打破传统 Transformer 设计的两个陈规,作者们构建了一个很大的搜索空间。
1. 任意编码器 - 解码器注意力(Arbitrary Encoder-Decoder Attention)
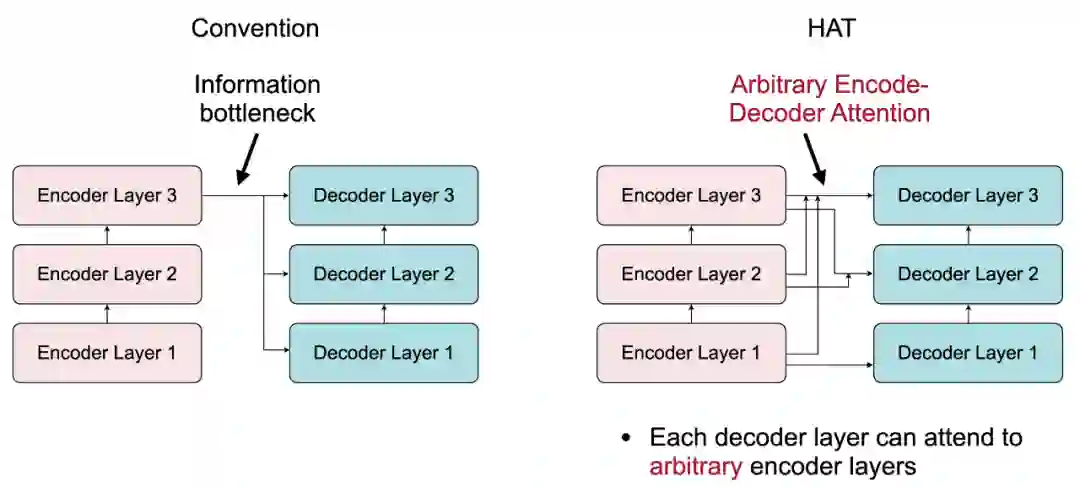
不同的编码器层抽取不同抽象层的输入信息,在基线 Transformer 中,所有的解码层都必须以编码器的最后一层作为输入。这使得编码器和解码器之间形成了一个信息瓶颈,并强制所有的解码层只从高度抽象层解码信息而忽略了低层信息,对小模型设计不友好。
研究者提出 “任意编码器 - 解码器注意力” 来打破信息瓶颈,并且学出编码器和解码器之间最合适的连接关系。每一个解码器层可以注意(attend)到任意且多个编码器层。从多个编码器层输出的 Key 和 Value 向量在句子长度的维度上进行拼接,并且被送到解码器中的“交叉注意力”(Cross-Attention)模块。因为这个机制没有引入多余的参数量,所以没有多余的内存开销。另外,它对运行时间的影响也几乎可以忽略。例如,当每个解码器层都注意两个编码器层时,Transformer-Big 模型在 GPU 上的运行时间仅仅升高了 0.4%。
![]()
2. 异构层(Heterogeneous Layers)
传统的 Transformer 对所有的层重复同样的网络结构。在 HAT 中,所有的层都可以有不同的结构,例如不同的头数(Head Number),隐藏层维度(Hidden Dim),词向量长度(Embedding Dim)等等。在注意力机制层中,Voita et al. (2019) 提出很多头是多余的,因此,研究者让头的数量成为弹性变化的(Elastic),每一层可以自行决定必要的头数。在 FFN 层中,输入特征向量被投射到一个更大的维度上(隐藏层维度)并被非线性函数激活。传统上,隐藏层维度的大小是词向量长度的 2 倍或者 4 倍。但是,因为每层需要的参数量会因抽取特征难度的不同而不同,所以固定的 2 倍或 4 倍是不合理的。因此在 HAT 中隐藏层维度也是弹性的。HAT 也支持弹性词向量长度,但要注意的是,编码器和解码器的词向量长度可以不同,但是在编 / 解码器内部的层之间,词向量长度保持一致。另外,编码器和解码器的层数也是弹性的。
![]()
为了得到高效模型,构建一个足够大的搜索空间至关重要。然而,完整训练搜索空间中的子网络来比较精确度的开销过大。之前的 SOTA 模型 The Evolved Transformer (So et al. 2019) 就是利用这种方法进行搜索。去年 ACL2019 中,Strubell et al. (2019) 指出了 Evolved Transformer 搜索排放的二氧化碳接近五辆汽车在整个使用寿命中的二氧化碳排放总量,造成了巨大的环境负担。MIT Technology Review 也对这一点进行了报导。
因此,为了可以实现环保 AI(Green AI),研究者采用 SuperTransformer 母网络来提供精确度的近似。母网络可以快速测试搜索空间中的任意子网络精度,而无需子网络训练。SuperTransformer 母网络是搜索空间中最大的模型,并且通过权重共享(Pham et al. 2018)包含了搜索空间中全部网络。所有的子网络 SubTransformer 共享他们在母网络中的共同部分。例如,所有子网络 SubTransformer 共享弹性词向量和隐藏层权重的前部,共享注意力层中的 Query、Key 和 Value,也共享编 / 解码器的共同前几层。
在训练过程中,研究者均匀地对在搜索空间中的所有子网络进行采样,得到梯度并且更新子网络对应部分的权重。所有的子网络获得了等量的训练并且均可以独立地完成任务。在实际中,母网络 SuperTransformer 所需的训练时间与单个基线 Transformer 相近,所以开销很低。
![]()
图 6: 母网络 SuperTransformer 权重共享。
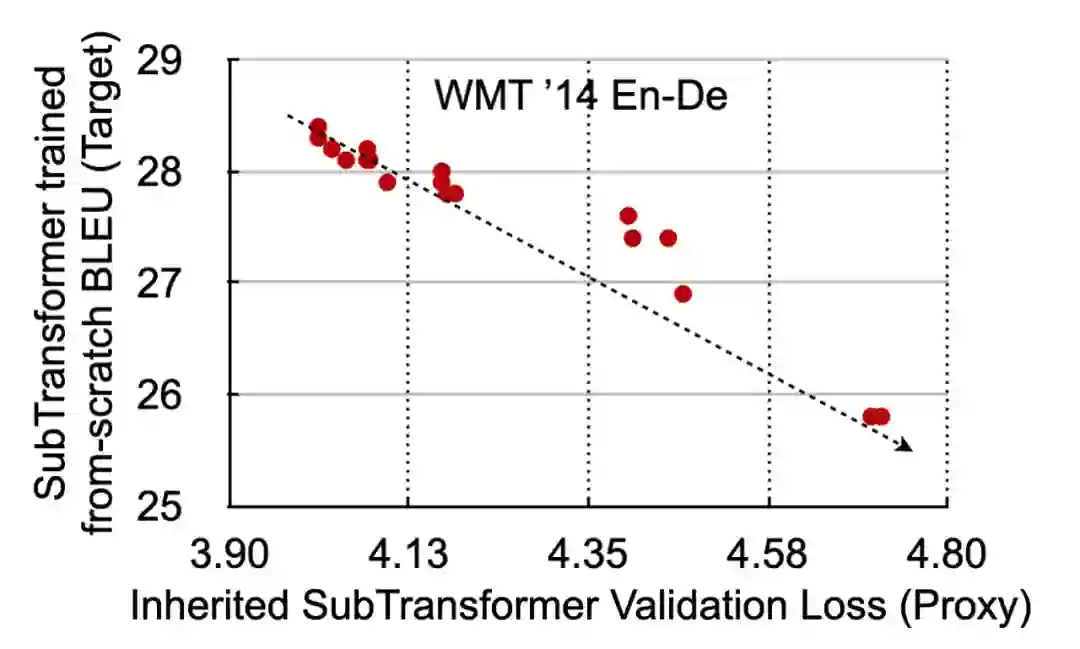
完成训练后的母网络是一个快速且精确的模型精度近似器(Performance Proxy)。给定一个子网络 SubTransformer,可以从母网络继承这部分权重,并且快速地测试得到 validation loss。这样就无需完整训练子网络。通过下图可以看到,近似器是非常精准的。子网络的 validation loss 越低,最终的完整训练得到的 BLEU 越高。
![]()
图 7: 母网络 SuperTransformer 提供精确的子网络 SubTransformer 精度近似。
进化搜索(Evolutionary Search)子网络
给定一个目标硬件上的运行时间限制,研究者使用进化搜索算法来搜索得到子网络 SubTransformer。
![]()
图 8: 进化搜索(Evolutionary Search)子网络。
进化搜索引擎利用 SuperTransformer 来获得子网络的 validation loss,并利用一个运行时间预测器来得到子网络在目标硬件上的运行时间。在每一步中,他们只将运行时间短于时间限制的子网络加入到种群(Population)中。具体而言,他们采用种群大小 125,母种群大小 25,重组 (Crossover) 种群大小 50,突变 (Mutation) 种群大小 50,0.3 突变几率。
有两种方法可以获取硬件运行时间。第一,线上测试法,在搜索的过程中即时测试子网络的运行时间。然而,这种方法有数个缺点。硬件每次运行的时间受很多因素限制,很不稳定,例如散热的影响。对于每个模型都需要运行数百次取平均来得到较精确的时间。另外,在进化搜索中,每一步都需要测试种群中的很多个子模型的时间,因此线上测试非常耗时,会成为整个搜索过程的瓶颈。
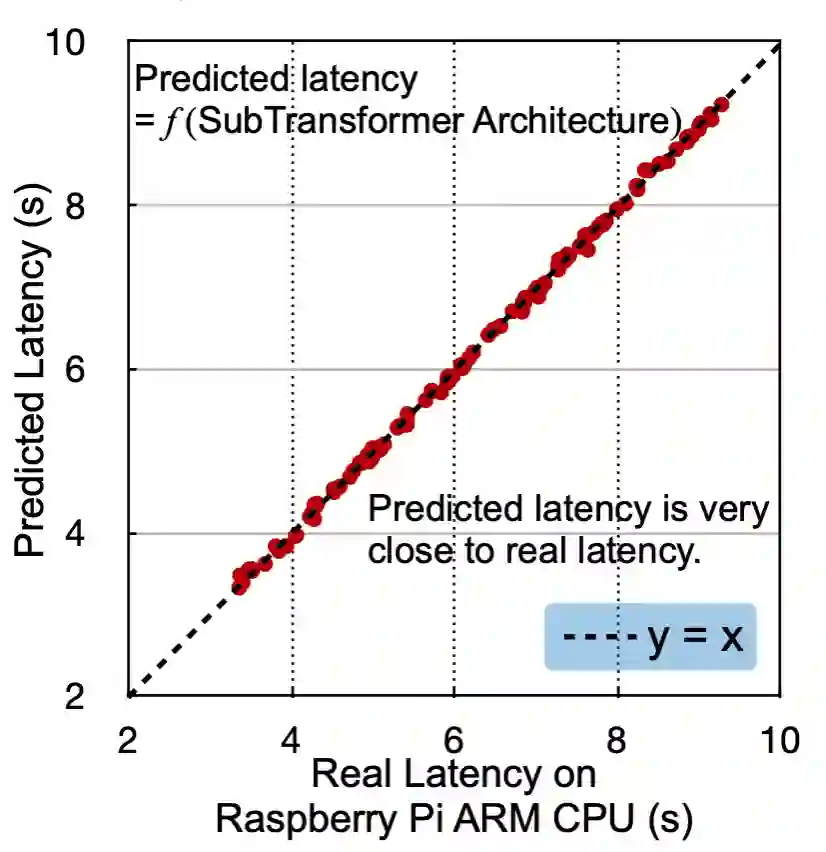
因此,在 HAT 中,研究者使用线下方法,训练一个预测器来快速且精确地给出子模型的运行时间。具体来说,他们将子网络的架构编码成一个向量,并且采集一个 [网络架构,运行时间] 数据对的数据集。然后训练一个多层感知器模型(MLP)来回归子网络的运行时间。对于每个硬件,他们采集 2000 个数据点,然后训练一个三层 MLP,每层维度 400,使用 ReLU 为激活函数。
实验表明,他们的预测器可以得到很精确的结果,在树莓派上的 RMSE 仅为 0.1 秒:
![]()
最终,他们将搜得的子网络从头进行一次完整的训练,并测试得到最终的模型精度。
研究者在四个机器翻译任务和三种硬件平台上进行了实验和分析。四个任务为:WMT‘14 EN-De(英语 - 德语)、WMT’14 EN-Fr(英语 - 法语)、WMT’19 EN-DE(英语 - 德语)、IWSLT‘14 De-En(德语 - 英语);三种硬件为:配备 ARM Cortex-A72 CPU 的树莓派、Intel Xeon E5-2640 CPU 和 Nvidia TITAN Xp GPU。
在多种平台和任务中,HAT 相比基线 Transformer 均有更好的精度 - 速度 trade-off 曲线,在相同精度下可取得 3 倍加速和 3.7 倍的模型压缩。
![]()
图 10:HAT 相比基线 Transformer 有更好的精度 - 速度 trade-off。
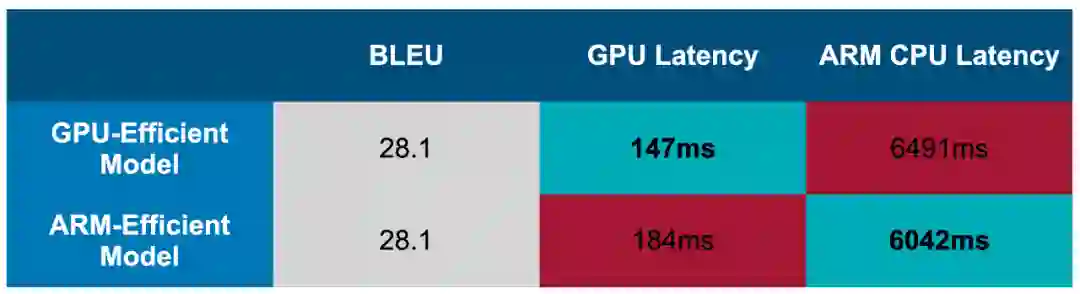
两个搜索得到的模型表现如下。可以看到,GPU 高效模型在 ARM CPU 上并不是最高效的,ARM CPU 高效模型在 GPU 上也不高效。这进一步证明了为不同硬件设计专用模型的必要性。
![]()
在树莓派上运行 WMT‘14 EN-Fr(英语 - 法语)任务时,相比 Evolved Transformer,HAT 可以取得 2.7 倍加速,3.7 倍模型压缩,3.2 倍计算量降低,并节省超过 1 万倍的搜索开销。
![]()
图 12:HAT 与 Evolved Transformer 对比。
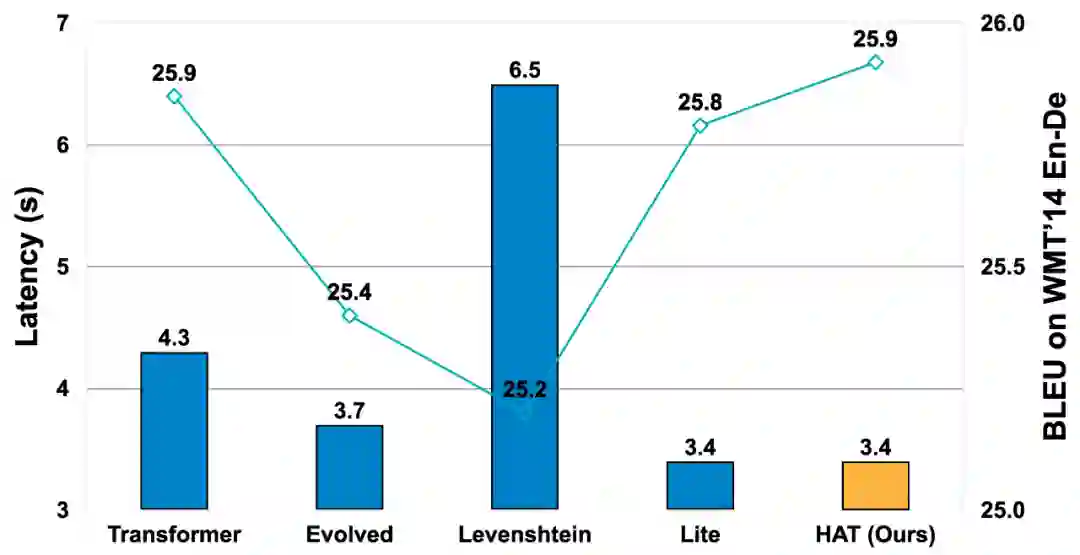
与 Levenshtein Transformer 和 Lite Transformer 对比
下图为不同模型在树莓派上运行 WMT‘14 EN-De(英语 - 德语)任务的对比。相比其他模型,HAT 可以获得最高的 BLEU 和最低的运行时间。值得注意的是,HAT 方法与 Levenshtein 和 Lite Transformer 中提出的新操作具有正交性(Orthogonal),可以结合使用。
![]()
图 13:HAT 与 Levenshtein Transformer 和 Lite Transformer 等对比。
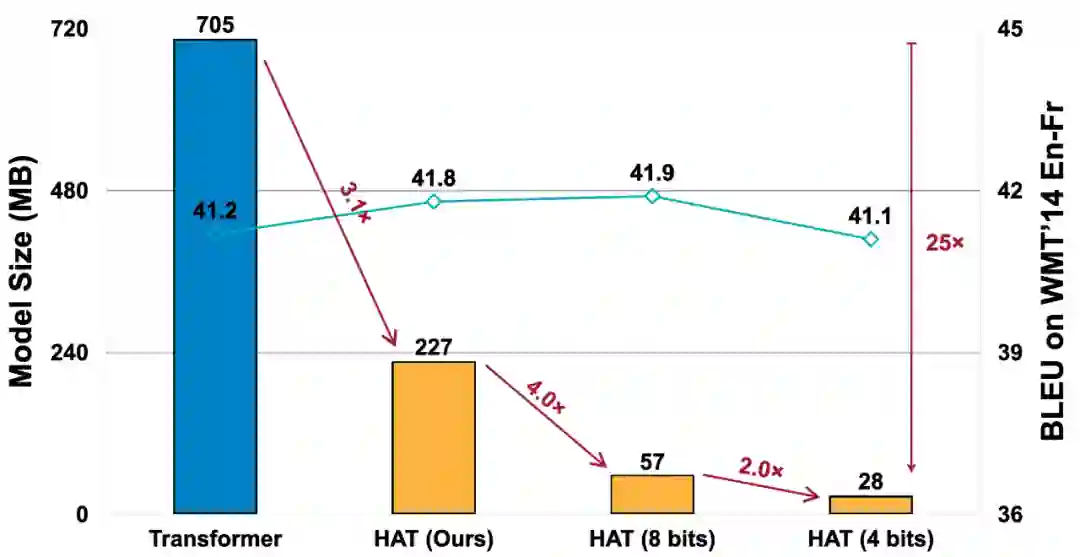
下图为在 WMT’14 EN-Fr(英语 - 法语)任务上,对 HAT 搜索模型进行量化的结果,在 4-bit 量化的情况下,HAT 模型与基线 Transformer 有相近的精度,但是模型大小可压缩 25 倍。
![]()
图 14:HAT 与通用模型压缩方法兼容,获得 25 倍压缩。
最后,研究者表示,他们将在 ACL 2020 大会上介绍自己的工作,在线问答将在 7 月 8 日北京时间晚 21 点 @13B Machine Translation-15 频道以及 7 月 9 日北京时间早 5 点 @15B Machine Translation-18 频道进行,感兴趣的老师、同学和工业界同事们可以前去交流。
7月11日09:00-12:00,机器之心联合百度在WAIC 2020云端峰会上组织「开发者日百度公开课」,为广大开发者提供 3 小时极致学习机会,从 NLP、CV 到零门槛 AI 开发平台 EasyDL,助力开发者掌握人工智能开发技能。扫描图中二维码,加机器之心小助手微信邀您入群。
![]()